S식 ........데이터와 프로그램
![]()
[例] ● 요소를 아톰으로 하는 리스트
(a b c)
● 리스트를 아톰으로 하는 리스트
(A (B 20) (C 30))
● Lisp함수를 아톰으로 하는 리스트
B (LAMBDA (X) (CAR, X))
(a) 리스트의 기본적인 형
(b) 리스트 (a, b, c)의 2진 나무 표현
AI의 핵심-추론하는 컴퓨터
|
생각하는 컴퓨터는 일렉트로닉스의 진보로 인한 것이라기 보다, 소프트웨어의 발전에 의해 실현되고 있다. 그 짜임새를 살펴 보기로한다. |
-추론 機構 (mechanism) 와 지식베이스-
제 1 부에 있어서는 AI를 정확히 이해하기 위한 기초지식을 서술했다. 그 중에서도 제 4장에서는 명제 논리와 술어 논리에 관해 언급하고, 제 5장에서는 술어 논리식의 모델이론과 도출 (resolution) 원리라는 상대적으로 어려운 것을 해설했다. 이들의 해설 목적은 모두 추론하는 컴퓨터의 짜임새를 이해하기 위한 것이다.
기초에서 이해해 감으로 하여, AI의 광범위한 응용시스템에 대한 이해도 가능하게 되며, 이로부터의 연구 방향 설정도 가능하게 될 것이다. 그러나 이해되지 못해도 큰 걱정은 없다. 그것은 현재의 컴퓨터 짜임새에 대한 이해가 되어 있지 않더래도, 이것을 사용하는데는 지장이 없는 것과 같다. 암상자 (black box) 내부의 짜임새를 알지 못해도 사용할 수는 있기 때문이다.
그러나 AI에 관하여는 다음 사항만은 이해해 두어야 하겠다. 그것은 인간이 생각할 수가 있는 것과 마찬가지로, 컴퓨터에 생각하게끔 시키기 위해서는 지식이 필요하다는 것이다. 생각하기 전에 문제를 이해하지 않으면 안된다. 이해하는 데에도 지식이 필요 한 것도 잘 명심해 두어야 하겠다.
생각한다는 것은 추론이며, 추론은 정보나 지식의 조합 방법에 관한 探索이라는 것. 또, 탐색을 효율적으로 수행하기 위해서도, 發見的 探索 (heuristic search) 에서 설명한 바와 같이, 문제에 관한 지식이 필요하다는 것, 그리고 문제의 탐색 공간에 차례차례로 작용소를 적용시켜 문제 해결의 방향으로 탐색을 계속해 간다고 하는 작용소의 機能에 관해서도 이해해 두어야 하겠다.
이상의 사항을 이해할 수가 있다면,AI의 태반을 안 것과 같아진다. 이 장에서는 이상의 것을 이해한 것으로 하고, 될 수 있는데로 알기 쉽게, 추론하는 컴퓨터의 하드웨어와 소프트웨어의 짜임새에 관해 설명한다.
그럼, 생각하는 기계는 전술한 바와 같이 지식을 갖고 있는 컴퓨터에 의해 실현될 수가 있다. 생각하는 것에 지식이 필요함을 깨달아서, 컴퓨터의 記憶 部分에 인간인 專問家가 갖고 있는 노우하우, 즉 지식을 기억시킨다. 이것이 지식베이스이다.
전문가의 判斷이 필요한 사태가 발생된 경우에, 이 지식베이스, 즉 추론하는 컴퓨터 (AI) 에 물어보면, 그 해답을 얻게 된다. 이것이 엑스퍼트 (expert) 시스템이란 것으로, 2-9절의 [AI의 응용 사례]에 그 한 실용시스템을 설명했었다.
이와 같은 추론하는 컴퓨터의 짜임새는 그림 7-1에서와 같이 크게 나누어서 推論 機構 (mechanism) 와 지식 베이스로 구성되어 있다. 그 중심 부분은 중앙처리장치 (CPU) 이며, 여기에 있는 추론 기구 (추론의 실행과 제어를 함) 가 지식 베이스 속에 기억되어 있는 지식을 이용하여 문제의 해답을 낸다. 지식 베이스는 사실 데이터를 기억하고 있는 데이터 베이스와, 추론의 루울 (rule) 을 기억하고 있는 루울 베이스로 나눠진다.
그림 7-1은 「철수의 할아버지는 누구인가」라고 질문하여, 「철수의 할아버지는 영호이다」라고 AI가 대답하는데 어떠한 지식을 지식 베이스에 기억시켜 두어야 할 것인가를 나타내고 있다.
그림 7-1 추론하는 컴퓨터의 짜임새
이 지식 베이스의 기술을 제 5장에서 설명한 술어 논리형의 언어로 기술한 개념도를 그림 7-2에 보인다. 그림 (a)는 사실데이터를 기술하는 선언절이며, (b)는 루울 베이스로, 프러덕션 루울 (production rule) 이라는 IF (條件) , THEN (結論, 行動)을 기술하고 있는 規則 節을 나타낸다. 우리가 일상 쓰고 있는 자연언어와 대조해가면서 설명하고 있으므로, 이해할 수 있을 것이다. 상기 (a)를 단기기억, 그리고 (b)를 장기기억이라 하기도 한다.
그림 7-2 (b)의 루울①에서는 "X가 Y의 아버지라면, X는 Y의 부모 (親)이다"를 술어 논리 표현으로
親 (X, Y) ← 父 (X, Y)
로 표현된다. 루울②는 "Y가 Z의 親(부모)이고, Y의 아버지가 X라면 (IF條件), Z의 할아버지 (祖父) 는 X이다(THEN 結論)"이며, 이것은
祖父 (X, Z) ← 父 (X, Y) ∧ 親 (Y, Z)
로도 표현된다. 그림 7-2 (c) 는 질문을 나타내고 있다. X, Y, Z는 변수로, 무엇이 대입되어 좋다.
그림 7-2 술어 논리형 언어에 의한 지식 베이스의 기술과 추론
(a) 데이터 베이스 (사실데이터의 기술)ㅡ 선언 절
|
• 은주의 아버지는 영호이다. ..........父(영호, 은주) (ㄱ) • 은주의 어머니는 경자이다. ..........母(경자, 은주) (ㄴ) • 철수의 어머니는 은주이다. ..........母(은주, 철수) (ㄷ) |
(b) 루울 베이스(프러덕션 루울의 기술)ㅡ규칙 절
|
(IF) 만약...라면, (THEN)...이다. 루울① • X가 Y의 아버지라면, X는 Y의 부모(親) 이다. ...親 (X, Y) ← 父 (X, Y) (ㄹ) • X가 Y의 어머니라면, X는 Y의 부모 이다. ...親 (X, Y) ← 母 (X, Y) (ㅁ) 루울② • Y가 Z의 부모이고, Y의 아버지가 X라면 Z의 조부는 X이다. ...祖父 (X, Z) ← 父 (X, Y) ∧ 親 (Y, Z) (ㅂ) • Y가 Z의 부모이고, Y의 어머니가 X라면 Z의 조부는 X이다. ...祖父 (X, Z) ← 母 (X, Y) ∧ 親 (Y, Z) (ㅅ) |
(c) 질문
|
• 철수의 조부는 누구이가....祖父 (X, 철수) |
여기서 설정되어 있는 문제는
• 은주의 아버지는 영호이다.
• 은주의 어머니는 경자이다.
• 철수의 어머니는 은주이다.
라고 하는 3개의 사실로부터, "철수의 할아버지는 누구인가"의 해답을 끌어 내는 것이다. 인간이라면 "철수의 할아버지는 영호이다" 로 바로 답할 수가 있다. 그러나 지금까지의 컴퓨터는 이와 같은 일은 매우 힘들었다.
인간에게는 어떻게 바로 이러한 일이 답해질 수 있는 것인가. 그것은 인간은 常識으로써 "아버지의 아버지는 할아버지이다" 라는 것이나, "아버지와 어머니는 부모 (親)이다" 라고 함을 기억해 두어서, 이 상식을 이용하여 추론하는 능력을 갖고 있기 때문이다.
그림 7-2 계속
추론하는 컴퓨터는 이러한 상식을 루울 베이스에 기억시켜서, 이 루울(상식)과 데이터 베이스의 사실을 매칭시켜 보고, 여기에 서술하는 패턴 매칭 (pattern matching) 으로 해답을 찾아 낸다. 이 사실과 루울(상식)을 지식베이스로부터 검색하여, 패턴 매칭을 수행하는 것이 추론 기구의 役割이다. 이 팬턴 매칭이 어떻게 수행되는가를 그림 7-2의 (c) 에 보인다.
그림 7-2의 (b)의 루울② (ㅂ)식과 질문을 매칭시켜 보면, Z = 철수인 것을 알 게 되고, 이것을 대입하여 (ㅈ)식을 얻는다. (ㄱ)식으로부터 X = 영호, Y = 은주를 얻는다. 루울①의 (ㄹ)식에 대입하면, 父(영호, 은주)와, 母(영호, 은주)를 얻게 된다. 그러나 母(경자, 은주)와 모순되므로, 이 패턴 매칭은 성립 않는다. 따라서 父(영호, 은주)로부터
X = 영호
가 해답이며, "철수의 祖父(X)는 영호이다"를 얻게된다.
여기서는 알기 쉽도록, 가장 간단한 추론(3단 논법)인 1단인 것을 서술하였으나, 실제 이 세계 속의 문제 해결은 이러한 3단 논법이 복잡하게 얽혀 있다.
그러나 여기서는 추론 기구와 지식베이스의 역할을 서술하였는데, 인공지능 언어, 가령 Prolog에는 이와 같은 패턴 매칭의 기능이 갖추어져 있어서 내부의 짜임새를 의식 않고 프로그래밍만 하면 추론하는 컴퓨터가 실현될 수 있도록 되어 있다.
[예제 7-1]
6-4절의 [예제 2]에서 보인 문제를 프러덕션 시스템을 사용하여 풀어보라.
(해답)
먼저 사실데이터의 기술을 하면
① (OCUPATION 철 수 EMPLOYEE)
② (OCUPATION 영호 STUDENT)
③ (철 수 ISA MALE)
④ (영호 ISA MALE)
⑤ (순이 ISA FEMALE)
⑥ (OCUPATION 순이 STUDENT)
이며, 프러덕션 루울의 기술을 하면
⑦ (IF (OCUPATION ? X STUDENT)
THEN(Put (? Y HAS DISCOUNT-TICKET)))
⑧ (IF (And (? Y HAS DISCOUNT-TICKET)
(? Y ISA FEMALE))
THEN(Print ? Y))
로 된다. 상기 표현형식은 u - PLANNER라는 인공지능용 언어에 속한다. 루울의 기술에서 3개의 함수 And, Put, Print를 사용하고 있다. 여기서, And는 뒤에 서술할 Lisp 함수의 AND와 같으며, 모든 요소에 대해 만족되어 있으면 만족한다. Put는 사실데이터베이스에 데이터의 부가를, 그리고 Print는 사용자에 표시를 수행해 주는 것이다.
추론의 실행은 다음과 같다.
(i) ⑦의 조건부는 ②와 매칭되므로, THEN부가 실행되어, 사실데이터베이스에
ⓐ (영호 HAS DISCOUNT - TICKET)
가 附加된다.
(ii) ⑥과 ⑦에서
ⓑ (순이 HAS DISCOUNT - TICKET)
도 부가된다.
(iii) 이때, ⑧의 조건부 (IF) 가 만족될 수 있으므로, ⑧의 THEN부에 의해, "순이"가 출력되고, 답을 얻게 된다.
이상에서와 같이, 인간의 단편적인 지식을 루울의 형태로 루울베이스에 넣게 됨으로 하여, 시스템이 자동적으로 관계 있는 루울을 작동시켜, 추론을 행한다[그림 7-3 (a) 참조]. 이 방법은 매우 편리하지만, 복수개의 루울 조건부가 만족될 경우, 또는 하나의 루울에 대해 그 조건부를 만족하는 데이터가 복수개일 경우, 어느 데이터와 루울을 사용해야 되는지가 문제로 될 때가 생긴다. 상기[예제 7-1]에서 ⑦에 대한 ②와 ⑥의 관계가 후자의 경우이며, 데이터베이스에 식 ⓐ와 ⓑ가 부가된 뒤에 ⑦과 ⑧의 관계가 전자의 경우이다. 이와 같은 문제의 처리를 경합해소 (conflict resolution) 라고 부른다[그림 7-3 (b) 참조]. 여러 경합해소법이 고려되고 있는데, 상기 예제에서는 다음과 같은 방법을 쓰고 있다.
① 데이터베이스와 루울베이스를 위에서 순서대로 이용한다.
② 한번 사용한 데이터와 루울 조는 가능한한 사용하지 않는다.
③ 조건이 엄격한 루울을 우선적으로 사용한다.
여기서 "조건이 엄격한" 이란 조건부의 구성요소의 수가 많은 경우를 뜻한다. 가령, ⑦과 ⑧에서는 ⑧의 조건이 엄격하다. 이와 같은 충돌해결은 추론기구에서 맡게 된다.
의미 네트워크는 5-8절에서 서술한 바와 같이, 각 사물이나 그들 관계를 그래프로 나타내고자 한 것이엇다. 즉 마디 (node) 에는 사실을, 그리고 가지 (branch) 에는 關係를 각각 대응시켜 표현했다. 이들 특징을 한번 더 요약 하면,
① 사실의 선언적 기술에 편리하다.
② 지식의 추가, 수정이 용이하다.
③ 네트워크를 더듬어 가거나, 다른 네트와의 매칭을 행함에 의해 추론을 한다.
④ 표현구조에 단순성, 균일성이 있고. 이해에 용이하다.
와 같다. 이의 지식처리시스템의 개념도를 나타낸다면, 그림 7-4와 같다. 그림 7-1과 비교하면, 의미네트가 데이터베이스, 의미네트 처리 프로그램이 루울베이스에 각각 상당한다. 여기서도 추론의 실행은 패턴매칭법이 쓰이게 된다.
그림 7-3 프러덕션 시스템에서의 추론 제어
그림 7-4 의미네트를 사용한 지식처리시스템
추론메카니즘은 네트워크 구조의 매칭에 바탕을 두고 이쓴데, 탐색 대상 혹은 질문을 나타내는 部分네트 (network fragment) 를 구성한 다음, 그러한 대상이 존재하는지를 조사하기 위해 네트워크 데이터 베이스와 매칭시켜 본다. 부분네트 내의 변수마디에는 매칭과정에서 매칭을 완전히 하기 위해 취해야 할 값이 결합된다. 가령, 데이터 베이스로서 6-4절의 [예제2]에서 보인 문제를 고려하기로 하자. 그것을 의미네트로 나타내면 그림 7-5 (a) 와 같다.
그림 7-5 의미네트 표현 예
이 네트워크에 대해, "할인권을 가진 여자는 누구인가?" 라는 질문에 답하고자 할 경우, 이 질문에 대한 의미네트는 그림 7-5의 (b)와 같다. 추론은 이 부분네트를 그림 7-5 (a)에 매칭시킴으로 해서 이루어 진다. 이 예에서는 ?X에 STUDENT, ?Y에 순이가 대응되며, 따라서 답은 순이가 된다.
5장에서 언급한 바와 같이 의미네트 지식표현의 장점은 상위, 하위 개념의 계층적 표현 (hierarchical representation) 과 지식의 집접 (chunk of knowledge) 이다.
Minsky는 사람의 認知過程에 있어, 프레임(틀)이라는 데이터 구조가 중요한 역할을 한다고 지적했다. 사람이 무언가를 인식하거나, 행동하고자 할 때, 직접 관계되는 대상만이 아니라, 그에 관련된 여러 구조화된 정보를 想起시키지 않으면 그때의 상황을 이해하기 힘들다. 이와 같은 構造化된 정보를 「프레임」이라고 명명했다(5-9절 참조). 이 지식표현의 특징에는 다음과 같은 것들이 있었다
① 프레임은 어떤 範例的인 상황 (stereo-typed situation)을 나타내는 데이터 구조이다.
② 수 종류의 지식이 프레임에 포함되어 있고, 그 중에는 프레임의 사용법에 관한 지식(즉, 절치)도 포함되어 있다.
③ 프레임은 階層構造를 만드는 지식을 표현할 수가 있다.
사람은 일상생활의 認知活動에 있어, 새로운 상황을 해결하고자 하면, 반드시 그 이전의 경험에서 얻는 잘 정리된 막대한 지식을 사용한다. 이러한 점을 5-9절에서 남의 집 방문을 예로 하여 설명한 바 있었다. 그때, 프레임은 여러 스로트로 구성되며, 이들 스로트는 각기 보다 상세한 지식으로 되어 있는 部分프레임으로 繼承된다고 함을 서술했다. 이 각 스로트에는 상식치 (default value) 가 쓰이는데, 이것은 상직적으로 있을 수 있는 경우를 말하는 것이나, 그렇지 않은 새로운 사태가 발생되면 추론기구가 그 대응 정보를 찾게 된다. 즉, 프레임적 문제해결은 기존의 지식에 바탕을 두고서 앞으로 예기 될 사건을 새 사태와 관련하여 해석해 감으로 해서 해결된다는 데 그 특징이 있다. 그림 5-13의 친구 방문의 프레임 전개에서 알 수 있듯이, 방문 프레임의 각 스로트에 대응되는 부분프레임이 불리어지고, 이때, 상식적으로 해왔던 경험이 우선된다. 즉, 보통 그렇게 했으니까 이번에도 그렇게 하면 되는 예기 구동형 처리가 이루어지면, 이것에 모순이 생기는 새 사태에서만 추론기구를 발동시켜 처리해 간다. 그렇게 함으로 해서 문제가 해결되는, 즉 추론이 이루어지게 되는 것이다.
여기서 한예를 들어, 추론과정을 보이기로 하자. 즉, 우리는 레스토랑에 가본 경험을 토대로, 메뉴, 테이블, 급사, 등에 관한 예기구동 처리를 하게 된다. 그림 7-6은 이 과정을 보인다.
그림 7-6에서, ~의 특수화 (specialization of) 라는 스로트는 프레임 간의 특징 계승 계층을 설정하는 데 쓰인다. 이 메카니즘이 親프레임에 관한 정보를 자에 계승시킬 수 있게 한다. 이것은 의미네트워크표현에서의 ISA 링크와 유사하다. 위치 (location) 스로트는 그 자신의 副스로트를 갖고 있는 것에 주의 해야 하겠다. 이와 같이 스로트가 복잡한 프레임형의구조를 가진 시스템도 있다. 이 프레임 예에서의 범위 (range) 스로트의 내용은 레스토랑의 위치 스로트 속이 어떠한 종류의 것인가라고 하는 예기치르 나타내고 있다. 補足 (if-needed) 스로트에는 필요에 따라서 그 값을 결정하는 데 쓰이는 부가절차 (attached procedure) 가 들어간다.
그림 7-6 레스토랑 프레임 표현 예
일반적인 RESTAURANT 프레임
~의 특수 예 : 상용 설립물
종 별 (types) :
범위 : (Cafeteria, 자유착석, 안내착석)
상식치 : 안내착석
補足 (if-needed) : 만약 프라스틱제의 오렌지색 카운터라면 즉석요리임.
만약 돈이 쌓아져 있으면 Cafeteria 임. 만약 "안내할 때까지 기다려 주십시오" 라는 간판이 있거나, 예약되어 있으면, 안내 받아 착석함. 그외는 자유로이 착석함
위치:
범위 : 주소
보족 : (메뉴를 본다)
이름
보족 : (메뉴를 본다)
요리의 종류 :
범위 : (햄버그, 중국요리, 미국요리, 생선요리, 불란서요리)
상식치 : 미국요리
보족 : 또 다른 메뉴를 본다.
영업시간 :
범위 : 시각
상식치 : 저녁 때 개점, 단 월요일 휴점.
지불방식 :
범위 : (현금, 신용카드, 수표, 접시닦이의 스크립트)
사건계열:
상식치 : "레스토랑에서의 식사" 스크립트
그림 7-7은 은 레스토랑에서 어떠한 일이 일어나는 전형적인 상화에 관한 지식을 台本 (script) 으로 나타낸 것이다.
Script (台本) 「레스토랑에서의 식사」
소도구 (props) : (레스토랑, 돈, 음식, 메뉴, 테이블, 의자)
매역 (roles) : (배고픈 사람, 급사, 주인)
관점 (point-of-view) : 배고픈 사람
때 (time-of-occurence) : (레스토랑의 영업시간)
장소 (prace-of-occurence) : (레스토랑에서)
사건의 계열 (envet-sequence)
first : 레스토랑 스크립트에 들어감.
then : 만약 「앉으시죠」의 손짓 또는 예약했으면, 「급사장을 부른다」의 스크립트
then : 「앉으시죠」의 스크립트
then : 「식사주문」의 스크립트
then : 만약 「긴 대기시간」아니면 「식사를 함」의 스크립트, 그렇지 않으면 「화를 내고 레스토랑을 나옴」의 스크립트
then : 만약 「식사가 좋아서 입맛에 맞음」이라면, 「주인에 칭찬을 함」의 스크립트
then : 「계산을 끝냄」의 스크립트
finally : 「레스토랑을 나옴」의 스크립트
그림 7-7 스크립트의 표현 예
현재의 맥락이나 상황을 나타내는 프레임이나 스크립트를 선정한 뒤에, 그 스로트에 의해 요구되는 細部를 채워가는 작업이 프레임에 바탕을 둔 推論시스템의 주요한 프로세스임을 전술한 바 있다. 예를 들면, 그림 7-6의 일반적인 레스토랑의 프레임을 선택한 뒤, 시스템이 제일 먼저 해야 할 것 중 하나는 "種別 (types)" 스로트의 값을 결정하는 일이다. 이에는 몇 개의 방법이 있을 수 있다. 종별은 직접 親프레임에서 계승되는 수가 많지만, 이 경우는 몇몇 별도의 길이 있다. 가령, 타와 모순되지 않으면, 상식치의 레스토랑 형을 채용할 수 있고, 또는 "補足 (if-needed)" 스로트의 附加節次로 결정할 수도 있다.
상식치와 계승치는 스로트를 메꾸는 데 비교적 코스트가 들지 않는 방법이다. 그들은 강력한 추론절차를 필요로 하지 않기 때문이다. 그들은 프레임의 능력 대부분을 설명하는 것이다. 이 상황을 解釋하는 어떤 새로운 프레임도, 다시 계산하지 않고 과거의 경험에 의해 결정된 값을 이용할 수가 있다. 필요한 정보를 도출하고자 할 때는 부가적인 절차기 현재의 맥락, 즉 스로트 고유의 휴리스틱 (heuristic) 을 이용할 수 있는 적당한 방법을 정해주는 수단을 만들어 준다. 바꾸어 말하면, 일반적인 문제해결 방법이 특정 스로트 레벨 목표를 어떻게 풀어 갈 것인가라는 영역 고유의 지식에 의해 보강되게 된다.
[예제 7-2]
6-4 절의 [예제2]에서 보인 문제를 프레임에 의해 풀어 보라.
(해답)
프레임의 구조를 다음과 같이 나타낸다면
(Frame 名
(slot 명1 (facet 명 11 (data 11))
....... (facet 명 12 (data 12)))
.......
(slot 명m (facet 명ml (data ml))
........
(facet 명mn (data mn)))
문제의 프레임 표현은 다음과 같다.
1. (철 수 (ISA ($ VALUE (MALE)))
(OCCUPATION ($ VALUE (EMPLOYEE))))
2. (영호 (ISA ($ VALUE (MALE)))
(OCCUPATION ($ VALUE (STUDENT))))
3. (순이 (ISA ($ VALUE (FEMALE)))
(OCCUPATION ($ VALUE (STUDENT))))
4. (STUDENT (HAS ($ VALUE (DISCOUNT-TICKET))))
문제를 풀어 내기 위해서는
IAS 스로트에 값 FEMALE
HAS 스로트에 값 DISCOUNT-TICKET
을 갖는 프레임을 찾아 내야 한다. 허나, 상기 프레임에는 없다. 이 경우 순이는 학생이고, 학생은 할인권을 갖는다라고 하는 것을 상기의 프레임 3과 4에서 추론하는 절차가 필요하게 된다.
그래서 순이의 프레임에 있는 HAS 스로트에 절차를 부가한다. 즉
(HAS ($ IF-NEEDED (SEARCH-OCCUPATION)))
여기서, $ IF-NEEDED는 데이터가 절차명임을 나타내고, 그 절차는 HAS 스로트가 참조되었을 때, 값이 없을 경우에 그 값을 얻는 데 작동된다. SEARCH-OCCUPATION은 그 프레임의 OCCUPATION 스로트의 값이 나타내는 프레임의 HAS 스로트를 조사하여, 값을 부가하고, 그리고 값을 되돌리는 절차이다. 따라서 값이 없을 경우도 마치 값이 주어졌던 때와 같이 보인다. 절차가 작동된 뒤의 순이 프레임은 다음과 같이 된다.
( 순이 (ISA ($VALUE (FEMALE)
(OCCUPATION ($VALUE (STUDENT))
(HAS ($ IF-NEEDED (SEARCH-OCCUPATION))
($ VALUE ( DISCOUNT-TICKET)))
따라서, ISA스로트에 값 FEMALE, HAS스로트에 값 DISCOUNT-TICKET을 가진 프레임은 순이이므로, 답은 순이로 된다.
단조성 (monmonotonic) 은 하나의 결론이 어떤 사실의 집합으로부터 도출된 경우, 다시 별도의 사실을 첨가해도 동일 경과를 도출해내는 것을 말한다. 이와 같은 성질을 이용하여 문제해결을 하는 시스템은 술어 논리에 바탕을 둔다. 그러나 이 술어 논리는 중요 정보를 표현하고 조작하는 데는 좋은 방법이 못된다. 예를 들면, "오늘 매우 덥다" 에서 더운 정도의 표현법이나, "금발 머리칼의 사람은 대개 푸른 눈을 갖는다" 에서 확실한 양의 표현, "반대할 이유가 없다면, 당신이 만날 어떤 성인도 읽는 방법을 알고 있다고 가정하라" 에서 한 사실을 다른 사실 없이 추리해 내는 것을 어찌 표현할 것인지, 마지막으로, "철 수는 자이언트가 이길 것이라고 하나, 내가 생각하기로는 그렇지 않다" 에서 몇 개의 서로 다른 確信시스템을 곧바로 어찌 나타낸 것인지 등이다.
따라서 확신의 조작에 의해 추론할 수 있고, 이 확신을 위해서는 어떤 증거를 요구하게 되는 데, 한 조의 확신, 즉 확신시스템 (belief system) 은 불완전, 모순된 것일 수도 있으나, 이로서 추론 시스템을 구성할 수 잇어야 된다는 것이다.
예를 들면, 인간은 언제나 완전한 지식을 바탕으로 일상적인 일의 판단을 하고 있는 것은 아니다. 전차로 출근할 때, 사고 등에 의해 늦어질 것인지의 여부를 조사한 뒤, 집을 나선다. 즉, 간혹 일어 나는 예측 불허의 사태인 경우는 별로 생각지 않고, 통상의 상태인 경우만 상정해서 행동한다. 그리고 만일 이상 사태가 발생하면, 당황해서 다음 취해야 할 수단을 생각한다. 그밖에 공공 교통기관이 없는가, 택시는 없는가 등이다. 이와 같이 不足한 속에서, 상식적인 선에서 문제를 해결해 가는 것을 非單調 (monmonotonic) 적이라 하며, 부족 (default) 추론, 혹은 상식적 추론이라고 한다.
통상의 상태만 상정해 두고서 추론하는 이 상식적 추론은 언제나 예외적인 이상사태를 고려해 넣은 추론에 비한다면, 그 결과는 불완전 할지는 모르나, 추론의 코스트는 격단으로 싸게 먹힌다.
[確信의 修正 (belief revision)]
상식적 추론의 결점은 예외적인 경우 실수를 범하는 것이나, 이것을 보충 해 주는 것이 확신의 수정이다.
상식 (default) 의 가정은 만약 그것을 적극적으로 부정해 줄 반증이 없는 한, 옳다고 생각하고 추론을 진행시킨다. 계속해서 추론하는 도중 모순이 생겼을 때, 문제로 되는 것은, 옳지 않을지도 모르는 상식의 가정이다. 「확신의 수정」은 모순의 원인을 확실히 알아내어 잘못되어 있었던 가정을 수정하는 조작이다.
「확신의 수정」은 우리 일상생활의 중요한 짜임새이며, MIT의 John Doyle에 의해 개발된 Truth Maintenance System이 잘 알려져 있고, 그 뒤 Drew Mcdermott가 논리학에 바탕을 둔 이론적 기초를 주었다.
〔「확신의 수정」을 행하는 메카니즘의 예〕
여기서는 추론을 관리하는 추론계와 추론의 신빙성을 관리하는 신빙성 관리계라는 두 시스템끼리 서로 연락을 해 가면서 문제해결을 한다.
"소수의 붉으면서 무거운 공과, 다수의 붉지 않은 가벼운 공이 존재하는 세계"를 고려한다. 즉 다음 두 사실이 성립한다.
① 거의 모든 공은 가볍다.
② 붉은 공은 모두 무겁다.
따라서 공의 무게에 관한 default value(상식치)는 "가볍다"이다. 이때, 어떤공 A의 輕, 重을 추론의 대상으로 하자.
「신빙성 관리계」에서는 각 명제의 의미를 생각하지 않고, 그들의 추론에서의 관계만을 관리한다. 이 때문에 각 명제에 아래의 이름을 붙인다.
① 붉은 공은 모두 무겁다 ↔ G001
② 공 A는 붉다 ↔ G002
③ 공 A는 무겁다 ↔ G003
④ 공 A는 가볍다 ↔ G004
여기서, G001은 사실임을 알고 있다.
「추론계」는 다음과 같이 추론하게 된다.
① 상식적 추론에 의해, 「 공 A는 가볍다 」, 즉 G004를 답으로 가정한다. ② 이 가정은 거의 모든 경우에 올바른 답을 준다. 허나, 뒤에서 공 A는 붉다는 것을 알았다고 하자. 그러면 「 붉은 공은 모두 무겁다 」인 것,「 공 A는 붉다 」인 것에서, 「공 A는 무겁다」인 것을 연역하게 된다. 이 연역은 신빙성 관계에서는「 G003을 확신시켜 주는 근거는 G001 및 G002이다.」라는 형으로 기억된다.
③ 추론계는 그 다음,「 공 A는 가볍다 」와 「공 A는 무겁다」의 두 결론이 모순됨을 보여 준다. 이 모순을 G005로 나타내면, 신빙성 관리계는 「 모순 G005를 확신시켜 주는 근거는 G003과 G004이다」라고 하는 형으로, 이모순을 도출시킨 추론을 기술하게 된다.
④ 이 시점에서, 문제 해결 시스템은 모순 G005의 제거를 시도한다. 신빙성 관리계를 보면, 모순 G005가 발생한 근거는 G003과 G004임을 알고 있다. 이들 2개 중, G003은 두 사실 G001과 G002에 의해 그 올바름이 보증되어 있음을 알 수 있으나, G004는 상식치이며, 결국, 그 가정이 모순의 원인임을 시스템은 알 수 있게 된다.
⑤ 시스템은 이 상식치의 가정을 삭제시킴에 의해 모순을 해소시킨다. 여기서 신빙성관리계는 추론과정 자체를 기술하고 있으며, 이 의미에서, 메타시스템이 되어 있음에 주의를 요한다.
이상의 예에서와 같이,「확신의 수정」은 인간의 일상적 추론 모델과 닮았고, 능률 좋은 되돌이 (backtracking) 제어를 실현시키는 데 쓰이고 있다. 즉
① 되돌이는 모순의 발생에 수반되어 발생된다.
② 어디까지 되돌릴까는 그 모순의 원인을 조사해서 결정한다.
③ 이 모순의 원인 규명에 「확신의 수정」메카니즘이 쓰인다.
문제해결 과정에서 비결정적인인 선택이 생기는 것은 문제해결 시스템의 지식이 불완전하면서, 어떤 선택 가지 (branch) 를 선택하면 좋을 것인가를 一義的으로 결정 불가능하기 때문이다. 이 중에서, 하나를 선택하여 계산을 진행시켜 감은, 그 선택 가지가 옳다고 하는 가정을 두는 것과 같다.「되돌이의 제어」를 선택 가지를 선택함은 앞의 가정을 수정하여, 새 가정에 바탕을 두고서 계산을 진행시켜 감과 같다. 이것이「확신의 수정」이다.
-효율적인 프로그램 언어를 구하여-
그림 7-1에 보인 하드웨어의 짜임새, 즉 CPU와 지식 베이스의 구성은 현재의 컴퓨터(가령, 개인용 컴퓨터)도 갖추고 있다. 또, 현재 사용하고 있는 프로그램 언어(가령, 개인용 컴퓨터)도 갖추고 있다. 또, 현재 사용하고 있는 프로그램 언어(가령 BASIC, PASCAL 등)에도 制御의 흐름을 나타내는 文으로 그림 7-4에 보이는 것과 같은 IF-THEN文 이 있다. 이것은 흡사 演繹推論과 꼭 같은 것이다. 따라서 현재의 개인용 컴퓨터를 사용하여 AI를 실현 할 수가 있다.
그러나 이와 같은 3단 논법의 추론을 현재의 프로그램 언어로 수행하는 데에는 많은 스텝이 필요하게된다. 다시말해, 현재 일반적으로 쓰이고 있는 프로그램 언어를 사용하여 인공지능을 실현하면, 매우 처리 효율이 나빠진다(〔AI의 공리 1〕을 참조). 또 하나, 현재의 프로그램 언어는 수치정보를 주로 하여 취급하기 위해 만들어진 것이므로 지식의 표현이 곤란하다.
그림 7-4 제어의 흐름을 나타내는 문 (if-then-else문을 사용하면 연역추론이 가능)
후술되지만, 이외에 인공지능을 실현하기 위해 필요한 프로그램의 조건이 있는데, 지금까지의의 AI연구는 소프트웨어의 연구였다. 일본의 ICOT(제 5세대 컴퓨터 개발 기구)에서 맨 처음 인공지능 지향 하드웨어, 즉 병렬처리 할 수 있는 컴퓨터를 만들기 시작했다. 소프트웨어의 개발에 중점을 두지 않으면 안되는 인공지능의 연구에, 하드웨어의 개발에 중점을 두었었기 때문에, 일본의 제 5세대 컴퓨터 개발은 성공 못할 것이라는 비판이 있었을 정도였다.
지금까지 읽어 왔던 독자는 인공지능용 프로그램 언어가 구비해야 할 조건에 관하여는 개략적으로 이해할 수 있을 것이다. 그것은 3-2절에서 언급한 바와 같이 문제의 기술이 문제 해결의 제 1단계였을을 기억해둬야 하겠다. 다음, 초기상태 혹은 목표상태에 작용소를 적용시켜서 상태공간을 만들어 내고, 이 상태공간을 탐색하는 것이 문제 해결이다.
효율적인 탐색에는 문제 영역의 지식이 필요한 것도 기억해두어야 하겠다. 즉 인공지능용 프로그램 언어의 제 1조건은 「지식과 탐색공간의 기술 및 探索 (추론) 機構로써 목표상태를 패턴 매칭하여 확인한다」라고 할 수 있다. 효율적인 탐색을 하기 위하여는 「再歸的인 制御 構造」라는 기능도 필요하게 된다.
제 5장에서 언급한 술어 논리에 의한 지식 표현은, 추론을 일종의 계산으로 보고 기계적으로 수행할 수 있도록 하고, 한정되어 있긴 하나 추론 기구까지도 포함된 Prolog라는 범용 인공지능 언어를 출현시켰다. 옛날부터 범용 인공지능 언어로 쓰이고 있는 Lisp에 관해서는 다음 3절에서 서술하기로 한다.
-Lisp와 Prolog의 특색-
컴퓨터 기술이 확립되기 위해서는 언제나 다음 두 요건이 필요하다. 그것은 처리할 분야의 槪念이 整理되어 알고리즘이 확립되고, 또 프로그래밍의 기술 확립이 되어 있어야 한다는 것이다.
전술한 바와 같이, 인공지능은 그 기술이 확립되었을 때에, 그것을 인공지능이라고 부르지 않게 되는, 끊임 없이 인간 두뇌에 접근하는 것을 목적으로 한 기술 개발인데, 그 프로그램 언어는 쉴 새 없는 진보를 계속하여, 항상 미완성의 언어로 불리는 숙명을 안고 있는 것이다.
인공지능의 연구는 인간 두뇌의 접근 혹은 실현임과 동시에, P, H, Winston은 「인간 두뇌의 기술 그 자체가 프로그램이다」라고 하고 있다. 다시말해 인공지능은 자연언어 대신에 프로그램언어를 사용하여, 인간 두뇌의 모델을 기술하는 것이라야 한다.
보다 인간 두뇌의 모델 기술에 알맞는 언어에, 현재 Lisp와 Prolog가 있다. 이 양쪽의 차이점과 특징을 알기 쉽게 해설하고저 하나, 보다 상세한 것을 전문서적을 참고하기 바란다.
처리 순서의 표현이란 측면에서 프로그램 언어를 고려한다면, 다음 3개로 대별된다.
① 처리를 실행문(처리 요소)의 계열로 표현하는 프로그램 언어인, 순차형의 표현 형식-FORTRAN, PL/1, PASCAL 등의 현재 널리 쓰이고 있는 언어 모두가 이 형의 표현임.
② 처리 순서를 식(처리 요소)간의 데이터 입출력 관계로 표현하는 것인, 함수형의 표현 형식-Lisp, APL등이 이 형에 든다.
③ 처리 순서를 술어(처리 요소)간의 데이터의 등가 관계로 표현하는 관계형의 표현 형식-이 대표적인 프로그램 언어가 관계를 술어 논리로 표현하는 Prolog이다.
인공지능 언어는 이 함수형 표현인 Lisp와 관계형 표현인 Prolog로 대표된다. 양쪽에 공통적인 것은 재귀적인 제어 구조가 있으며, 패턴 매칭이 가능하고, 연역 기능을 시스템측 혹은 프로그램측에 붙일 수가 있다. 특히 다음에 보일 리스트 처리가 探索, 分類, 패턴 매칭 등을 수행하는 메카니즘의 기본이 되어 있으며, 이것이 演繹操作을 할 수 있게 한다는 데 주목해야 할 것이다.
리스트 (list) 라는 개념은 5-4절에서 보였다. 그림 5-9 및 5-10에서, 리스트는 탐색 나무 구조를 표현하는데 최적인 짜임새인 것을 이해해야 한다.
그림 7-5 지식과 루울 (rule) 의 표현 예
그림 7-5는 "X는 Y의 아버지이다" 라는 지식의 표현을 술어 논리와 2진 나무 (binary tree) 양쪽으로 나타내고 있다. is-father-of(X, Y)를 모델화하여, 「is-father-of」,「(」,「X」,「,」,「Y」,「)」로 구성된 기호열 표현이다. 祖父라는 개념, 즉 루울 (rule) 은 그림의 (b)에서와 같이 2진 나무 표현을 할 수 있고, (c) 에서와 같이 명제 논리 표현도 가능하다. 이것은 지금까지 상세히 서술해 온 3단 논법인 "A라면 B이다" 와 "A이다" 로부터 "B가 성립한다" 라는 논리 조작을 나타내고 있다. 이 X, Y, Z에 각각 "영호", "철수", "종훈" 이란 이름을 대입하면, "영호는 철수의 조부이다" 라는 해답을 얻게 된다.
인공지능은 이와 같은 연역 조작을 수치 계산에 의한 가감승제 연산 처럼 일정 규칙에 따라 기계적으로 수행하고 있다. 물론 이 조작을 하는 것이 프로그램 언어의 역할이며, 지금까지의 컴퓨터는 데이터를 처리하지만 인공지능은 데이터 대신에 지식을 연역 조작하게 된다. 이러한 리스트 처리가 인공지능의 핵심이며, 이 강력한 리스트 처리 프로그램 언어에 Lisp가 있다.
중요한 것은 5-4절에서 서술한 1階의 술어 논리로 표현될 수 있는 문제라면 어떤 문제도 전적으로 기계적인 처리로 풀어 낼 수가 있다는 것이다. 이점이 도출 (resolution) 원리를 해설한 이유이다. 이 때문에, 술어 논리형(관계형 표현) 프로그램 언어인 Prolog에는 한정된 추론 기구가 구비되어 있어서, 인공지능용의 프로그램 언어로서 각광을 받고 있다. Lisp와 Prolog의 相違點을 표 7-1에 보인다.
표 7-1 Lisp와 Prolog의 비교
|
① ② ③ ④ ⑤ ⑥ |
LISP |
PROLOG |
|
Lisp processing의 약칭 미국에서 개발, 세계적으로 보급 함수형 표현으로 절차적으로 기술 추론 기구는 user가 만듦 약간 난해 탐색, 추론 방식은 자유로이 설정 할 수 있음 |
Programming in Logic의 약칭 유럽에서 개발, 일본 제 5세대 컴퓨터에서 사용함. 관계형 표현(술어논리)으로 선언적으로 기술 제한되어 있으나 추론기구 내장 인간이 쓰는 언어에 가깝고 알기쉬움 깊이 우선 탐색, 역방향 추론, 자동되돌이 (back-tracking) |
AI연구의 초기부터 인공지능용의 언어가 개발되었었다. 그것이 Lisp 이다. Lisp는 記號處理나 복잡한 처리 순서를 간단히 표현할 수가 있다. 그 개요를 일반적으로 널리 쓰이고 있는 MIT가 개발한 MACLISP(LISP의 일종)으로 설명한다.
여기서는 지금까지 서술해 온 지능로보트의 작용소 기술을 할 수 있는 범위에서 설명하여 인공지능용 언어의 특징을 이해하도록 한다. 본격적인 것은 참고문헌을 참조하기 바란다.
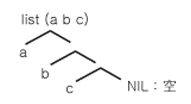
(1) 문제의 기술과 탐색 공간의 기술에 편리한 리스트처리 : Lisp의 특징의 하나는 프로그램도 데이터도 같은 구조를 갖고 있어서, 그림 7-6에 보이는 리스트로 표현되는 것이다. 이것은 아톰 (atom) 이라는 문자열로 도시하는 것과 같이, 리스트를 아톰으로 하는 리스트와, 후술할 Lisp함수르를 아톰으로하는 List가 있다. 아톰과 리스트는 S식이라 총칭된다. 즉, Lisp에서는 프로그램도 데이터도 S식으로 표현된다.
(2) 리스트를 조작하는 기본 명령: 리스트를 조작하는 세 기본 명령(CONS, CAR, CDR)을 그림 7-7에 보인다. 이들 함수를 조작하면, 리스트가 표시하는 2진 나무의 탐색 공간이 조작되는 데에 주목해야 한다. 다음에 보이는 것과 같은 리스트 조작의 계산을 하여, 익혀질 필요가 있다. 여기서 나타내는 *표시는 평가된 결과를 표시한다. 평가한다고 함은 S식의 아톰이 조작되어, 그 값이 구해지는 것이다. S식을 평가하고 싶지 않을 때의 인용기호 " ▼ "를 붙인다. 여기서 나타내는 SETQ는 그림 7-9에서와 같이 첫 번째 매개변수의 값으로 하여 두 번째의 매개변수를 제공하는 함수로, 이 이외 도시되어 있는 것과 같은 함수들이 준비되어 있다.
그림 7-6 리스트 처리
|
S식 ........데이터와 프로그램
[例] ● 요소를 아톰으로 하는 리스트 (a b c) ● 리스트를 아톰으로 하는 리스트 (A (B 20) (C 30)) ● Lisp함수를 아톰으로 하는 리스트 B (LAMBDA (X) (CAR, X)) (a) 리스트의 기본적인 형 (b) 리스트 (a, b, c)의 2진 나무 표현 |
그림 7-7 리스트 조작의 기본 명령
|
CONS 2 매개 변수의 함수로 리스트의 선두에 새 아톰(또는 리스트)를 붙인다. |
|
CAR 리스트를 매개 변수로 하는 1매개 변수 함수. 선두의 요소를 집어 낸다. |
|
CDR 리스트를 매개 변수로 하는 1매개 변수. 선두를 집어내어 없앤 나머지의 리스트를 그 값으로 한다. |
(3) S식의 眞僞를 구하는 술어 함수 : Lisp에서는 참을 T, 거짓을 NIL이라고 특별한 아톰에 의해 표현한다. 이 술어 함수와 그 평가를 그림 7-9에 보인다. 그림 7-11에 보이는 것과 같은 논리 연산 함수도 정의되어 있어서, 그 평가를 나타내고있다.
그림 7-8 술어 函數의 評價
|
ATOM 매개 변수가 아톰이라면, T, 그렇지 않으면, NIL. |
[예1] (ATOM′ YAMAMOTO) * T [예2] (ATOM′ (ON A C)) * NI L [예3] L =′ (A B C) 로 정의하면 (ATOM L) * NIL (ATOM′ L) * T |
|
ZEOP 매개변수가 0이면 T, 그렇지 않으면 NIL. |
[예] (ZEROP 2) * NIL |
|
EQUAL 첫 번째 매개 변수와 두 번째 매개 변수가 같으면 T, 같지 않으면 NIL. |
[예1] (EQUAL L L) * T [예2] (EQUAL L′ L) * NIL |
|
NULL 매개 변수가 空인지의 여부를 조사한다. |
(NULL X) ={ T if X =〔 〕, F Otherwise} [예1] (NULL′ ()) *T [예2] (NULL L) * NIL [예3] (NULL(CDR(CRR′ (AB)))) * T |
|
MEMBER 첫 번째 매개 변수가 두 번째 매개 변수의 리스트의 요소 인지를 조사한다. |
[예1] (MEMBER′ A L) * T [예2] (MEMBER′ A (CDR L)) *NIL |
그림 7-9 시스템의 평가
|
SET 2 매개 변수 함수, 첫 번째 매개 변수를 평가하고, 그 결과의 값으로써 두 번째 매개 변수의 값을 제공한다. |
[예] SET (CAR′ (X Y)′ (A B)) * ′(A B) 注 : (CAR′ (X Y) 의 값은 X이며, 그것에 (A B)라는 값을 준다. |
|
SETQ 2 매개 변수 함수, 첫 번째 매개 변수의 값으로써 두 번째 매개 변수의 값을 제공 한다. |
[예1] (SETQ TWO 2) * 2 [예2] (SETQ L′ (A B C)) * (A B C) 주 : SETQ = (SET +1) 이므로, 가령 (SET′ Z′ (CD)) = (SETQ Z′ (CD)) 로 된다. |
|
LIST 임의 갯수의 매개 변수를 취해, 그것을 요소로 하는 리스트를 만든다. |
[예] (LIST′ A′B) (LIST′C′D)) * ((AB) (CD)) |
|
APEND 리스트를 연결한다. |
[예] (APEND′ (AB)′ (CD)) * (A B C D) |
|
數値計算用函數 PLUS (덧셈) DIFFERENCE (뺄셈) TIMES (곱셈) QUOTIENT (나눗셈) SQRT (제곱근) ABS (絶對値) MAX (最大値) 등이 있다. |
[예] (PLUS 2 3) * 5 備考 : * ㅡ 시스템으로부터의 응답을 표시함 ′ㅡS식을 평가하고 싶지 않은 경우에 붙인다. [예1] ′TWO * TWO [예2] ′(PLUS 2 3) * (PLUS 2 3) |
그림 7-10 함수를 정의하는 방법
|
DEFUN 함수를 정의할 경우에 사용한다.
|
(DEFUN<함수명. <假媒介變數의 리스트> <함수의 정의>) 리스트의 두 번째를 구하는 [예1] 함수 SECOND를 정의한다 (DEFUN SECOND (X) (CDR X))) * SECOND 이것을 정의하여 두면 L = (A B C)에서 (SECOND L) * B [예2] 그래프 탐색에서의 리스트 OPEN에 새마디 N을 더해주는 함수 UPDATE-OPEN의 정의(OPEN 리스트에 마디 N이 없는 경우만 추가한다). (DEFUN UPDATE-OPEN (NEW-NODE) (COND ((MEMBER NEW-NODE OPEN) OPEN) (T (CONS NEW-NODE OPEN))) 지금, OPEN이 (A B C)이라 하면 (UPDAE-OPEN´D) * (D A B C) |
|
① (CAR′ ((A B)C)) * (AB) ② (CDR′ (FIRST SECOND THIRD)) * (SECOND THIRD) ③ (CDR′ (ONE)) * ( ) 注 : ( ) 는 空리스트를 나타냄 ④ (CONS′ A′ (BC)) * (A B C) ⑤ (CONS (CAR′ (A B C)) ((CDR′ (A B C))) * (A B C) 주 : 내측의 리스트로부터 순서대로 평가되어 계산함 ⑥ (SETQL′ (ABC)) * (A B C) ⑦ (CRR L) * A ⑧ (CONS L L) * ((ABC) A B C) |
(b) 리스트 조작의 예
그림 7-11 논리 연산 함수의 평가
|
NOT AND OR
|
[예1] (NOT (ATOM′ C)) * NIL [예2] (NOT (ATOM L)) * T [예3] (AND (NOT (NULL L)) (ATOM (CAR L))) * T [예4] (OR (NULL L) (ATOM(CAT L))) * T OR와 AND는 몇 개의 매개 변수를 가질 수가 있다. [예] (AND T T NIL) * NIL |
그림 7-12 조건에 따라 평가 대상을 바꾸는 함수 COND
(4) 조건에 따라 대상을 바꾸는 방법 : 탐색할 경우에 차례차례로 탐색 대상을 바꾸어서 그림 7-12에 보이는 COND가 정의되어 있다. 이것은 도시되어 있는 것과 같이 조건식의 표현이 가능하다.
(5) 임의의 함수를 정의하는 방법 : 이상에서 정해진 함수 이외에, 그림 7-10에 보이는 DEFUN이라는 함수를 사용하여, 임의의 함수를 정의 할 수가 있다. 그림 (a)의 [예2]는 제4장에서 언급한 그래프 탐색에서의 OPEN 리스트에 새 마디를 더해주는 함수를 정의한 것이다. 이와 같이, Lisp에 의해, 제 4장에서 보인 탐색의 알고리즘에 대한 프로그램화가 가능해진다.
(6) 재귀함수의 정의 사례 : 그림 7-8의 밑에 보인 MEMBER란 술어 함수는 첫 번째 매개변수가 두 번째 매개변수의 리스트인지를 조사하는 함수이다. 이것을 재귀적으로 불러내어 차례차례로 조사해 가도록 하면, 편리하다. 이것은 (4)에서 보인 조건에 의하여 평가대상을 바꾸는 함수 COND를 사용하여 그림 7-13과 같이 정의할 수 있다. 이것은 A : RED (赤) 가 L이라는 리스트 속에 있는지를 차례차례로 조사하고 있는 사례를 설명하고 있다. 식 중에 MEMBER가 두군데 있어서, 자기 자신을 불러내어 재귀하고 있다.
그림 7-13 再歸 函數에 의한 반복 탐색
|
재귀함수의 정의 : 함수에 이름을 붙여서 데이터 베이스에 등록시켜 놓고, 그 이름으로 함수를 불러 내는 재귀함수의 정의가 가능하다. (DEFUN MEMBER (A L) (COND ((NULL L) NIL) ((EQUAL A(CAR L))T) (T(MEMBER A(CDR L))))) (MEMBER가 두 군데 들어 있음에 유의) A :RED L : CTEEN BLUE RED YELLOW 로 하면 (MEMBER′RED′ (GREEN BLUE RED YELLOW)) 로 되고, 이것을 입력시키면, A와 CAR L이 같지 않으므로, 최후의 행인 (MEMBER A(CDR L) 가 평가된다. 이에 의해 문제가 (MEMBER′RED′(BLUE RED YELLOW) 로 변환된다. 이와 같이 하여 한번 더 같은 일이 반복되어, 다음은 (MEMBER′RED(RED YELLOW) 로 되어 (EQUAL ′RED(CAR′ (RED YELLOW))) 가 성립하여 T로 되고, RED가 L중에 있음을 알 게 된다. |
(7) 패턴 매칭을 하는 함수의 정의 : 그림 7-14에 목적 상태를 찾기 위해 패턴 매칭을 하는 함수의 정의를 보인다. 이 사례는 R식과 S식을 매칭시켜 보아서 "붉은 것이 있는가"란 질문을 하여, "있다" 라고 답하고 있는 부분을 보이고 있다. "그 붉은 것은 무엇인가" 라고 하도록 출력시키는 함수도, 이것을 변형하면 정의할 수가 있다.
(8) 데이터 베이스의 검색 사례 : 그림 7-15에, 앞장의 그림 6-4에서 보인 지능로봇이 각목을 이동시키는 문제의 초기상태를 데이터 베이스에 기술하여, 그 상태가 어찌 되어 있는지를 검색하고 있는 점을 보인다. 문제의 기술과, 검색의 짜임새를 이해해야 하겠다. 마찬가지로 하여 데이터 베이스의 갱신을 하는 함수의 정의도 가능하다.
그림 7-14 리스트의 패턴 매칭을 하는 함수의 정의
|
그림 7-8에 두 매개변수의 S식이 같은지를 조사하느 ㄴ술어 함수 EQUAL을 보였다. 여기에 보일 함수 MATCH는 패턴 매칭에 쓰는 것으로, 패턴 P와 S식과를 매칭시켜 본다. 재귀적 호출에 의해 선두의 리스트로부터 조사한다. (DEFUN MATCH (P S) (COND ((AND (NULL P)(NULL S))T) ((OR(NULL P)(NULL S))NIL) ((OR(EQUAL(CAR P)′?) (EQUAL(CAR P((CAR S))) (MATCH(CDR P)(CDR S))))) [예] P式(Color ? RED) S式(Color BOX RED) (MATCH′ (COLOR ? RED)′ (COLOR BOX RED)) * T |
그림 7-15 지능로보트의 작용소의 기술
|
그림 6-4에 보였던 지능 로봇트의 작용소의 동작을 기술한다. (STACK(X Y)) : Y를 X위에 둔다(전제조건 : Y위에 아무것도 없다).
(DEFUN STACK(X Y) (PROG(? Z Z) (COND ((FIND(LIST′ON X Y))(RETURN))) LOOP (COND((FIND(LIST′ON ? Z Y)) (PUTDOWN Z′TABLE)(GO LOOP) (PUTDOWN X Y))) 주 : Y위에 각목이 있으면 순서대로 제거하고 있다. (PUTDOWN X Y)는 X를 Y위에 두는 것을 나타낸다. (PUTDOWN(X Y) : 각목 X를 Y위에 둔다. (그림 6-4의 UNSTACK (x, y)와 PUTDOWN (x) 양쪽의 동작을 하는 작용소를 정의한다.) (DEFUN PUTDOWN (X Y) (PROG(? Z Z) (COND((NOT(FIND(LIST′HOLD X))) (COND((FIND(LIST′HOLE ? Z)) (PUTDOWN Z′TABLE) (DELETE(LIST′HOLE Z)) (ADD(LIST′ONTABLE Z)))) (PICKUP X)) (DELETE(LIST′HOLD X)) (COND((EQUAL Y′TABLE)(ADD(LIST ONTABLE X))) (T(ADD(LIST ON X Y)))) (RETURN))) 주 : DELATE는 리스트 HOLD로부터 제거한다. ADD는 리스트 HOLD에 추가한다. (PICKUP X) : X를 집어올린다(전제조건 : X위에 아무것도 없다.) X위에 무엇이 올려져 있으면 그것을 순서대로 제거한다. (DEFUN PICKUP(X) PROG(? Z Y) LOOP (COND ((FIND(LIST′ON ? Z X)) (PUTDOWN Y′TABLE)(GO LOOP))) (COND((FIND(LIST′ON X ? Y)(DELETE(LIST′ON X Y))) (T(DELETE(LIST′ONTABLE X))))) (ADD(LIST′HOLE X)) (RETURN) |
그림 7-16 문제를 데이터 베이스에 기술하여 필요 데이터를 검색하는 사례
|
하기의 초기상태를 데이터 베이스에 기술한다.(그림 6-4참조)
초기상태의 기술 (ON A C)(ON B C)(ONTABLE C)(ONTABLE D)(ENPTY) 데이터 베이스에 각목의 상태를 기술 (SETQ LDATA′ ((ON A C)(ON B C)(ONTABLE C) (ONTABLE D)))) 주 : LDATA는 각목에 대한 사실의 리스트로 변수를 나타냄. 검색을 할 함수의 정의 (DEFUN FINS(FACT) (PROG(LTEMP) (SETQ LTEMP LDATA) LOOP (COND((NELL LTEMP)(RETURN NIL) ((MATCH FACT(CAR LTEMP))(RETURN T) (SETQ LTEMP (CDR LTEMP)) (GO LOOP) 주 : 검색할 함수명 : LTEMP, PROG는 반복함수, LOOP는 장소를 나타내는 아톰으로 (GO LOOP) 에 의해 제어가 끝남. [예] 質問 : C위에 것은 무언가 (FIND′ (ON ? X C)) * T (올려져 있다) × * A (A이다) 질문 :A위의 것은 무언가 (FIND′ (ON ? X A)) * NIL(올려져 있지 않다) |
(9) 지능로보트의 작용소의 기술 : 그림 7-16에는 앞장의 그림 6-4에 보였던 지능로봇트가 각목을 이동시킬 경우, 작용소의 동작을 정의하고 있다. 전제조건이 만족되지 않는 경우는 그 조건을 만들어 가면서 작용소가 동작하는 점에 주목해야 하겠다.
(1)) Lisp언어의 발전 : 1970년대로부터 Lisp를 기초로하여 그 기능을 확장시킨 PLANNER, CONNIVER, POP-2등이 만들어졌다. 그 뒤, Lisp에 여러 가지의 기능을 붙여서 강화시킨 INTER-Lisp도 개발되었다. 많은 기능을 집어 넣게 되면 시스템이 커지게 되고, 처리 속도가 떨어지며, 디버깅이 곤란해진다. 다음에 보일 Prolog는 이들의 결점을 보완한 AI용의 새 언어로 등장하고 있다.
Prolog는 자연언어의 구문 해석 연구에서 생겨난 언어로, 후술하는 바와 같이 복잡한 자연언어(나무형 구조)의 기술에 편리하다. 일본의 제 5세대 컴퓨터 개발에는 Lisp를 쓰지 않고 이 Prolog를 채용하고 있다.
인간이 쓰는 자연언어에 가장 가까운 언어가 이들 AI용 언어인데, 이것은 장차 OA 분야 등 여러 곳에 광범위하게 사용될 것이다. 이 Prolog역시 Lisp와 마찬가지로 범용의 리스트 처리 언어이나, 그 기술 레벨이 Lisp보다 높은 것으로 되어 있다. 이것은 종래의 언어와 같이 해법을 기술하는 것이 아닌, 문제를 기술하면 시스템 자신이 해를 찾아 주는, 추론 機構 (한정되어 있긴 하나)를 그 언어 속에 갖추고 있는 점이 특징이다.
이하 Lisp와 대조해가면서 Prolog의 장점을 설명한다.
(1) 지식을 술어 논리로 표현한다 : 그림 7-17에 Prolog에 의한 지식을 나타내는 문의 기본적인 구조를 보인다. 이 표현은 지금까지 자주 언급해 왔던 술어 논리 표현으로 Lisp의 아톰에 상당하는 항(이것을 술어의 매개변수라 함)을 술어라는 항으로 관계 지워서 문을 만든다. 이들의 항은 모두 소문자로 표현하고, 이 매개변수 사이를 ", "로 끊는 것도 Lisp와 다르다. 이와 같이 표현하면 자연언어에 잘 쓰이는 나무형구조도 그림 7-18에 보인는 바와 같이 쉽게 표현할 수가 있다.
(2) 리스트 처리를 패턴 매칭에 의해 수행한다 : Lisp의 경우는 리스트 처리를 CAR이나 CDR에 의해 수행한다. Prolog에서도 리스트는 ( )로 표현되고, 요소와 요소 사이에 ","을 붙인다. 그러나 현저한 상위점은 그림 7-19에 보이는 바와 같이, 리스트 처리는 패턴 매칭으로 행하고 있는 점에 있다. 그림의 단일화란 패턴 매칭에 의해 X를 구하고 있는 것을 나타낸다(Lisp의 CAR 동작을 하고 있음에 주의).
그림 7-17 Prolog에 의한 문의 기본적인 구조
그림 7-18 나무형 구조의 표현에 알맞는 Prolog
Sentence(np (det (this), noun(travel), VP(VP(Verb(was), ad(not)), a(interesting)), npp(Prep(at), np(noun(all)))))
(3) 프로그램은 文의 계열이다 : 전술의 문(이것을 리터럴이라 하는 수가 있다)의 게열에 의해 그림 7-20에 보이는 프로그램을 표현할 수 있다. 그림 7-21은 OR를 포함한 프로그램이나, 이것은 AND문으로 변환될 수 있다. 이상의 표현을 사용하여 Prolog의 기본적인 동작을 살펴보기로 한다.
(4) Prolog에 의한 프로그램의 실행 : Prolog는 문제를 기술하면, 시스템이 자동적으로 해를 찾아 준다. 그대신, 입력문이 그림 7-20에 보이는 바와 같은 형식으로 제한되어 있다. 이것은 머릿 부분은 하나의 항으로, 몸 부분은 否定을 포함 않는 항의 AND인 제한을 갖는다. 이는 논리적으로 표현하면,
Q ∨ R V S V P 또는 ~Q V ~R V ~S V P
라는 형이 된다. 이는 절 형식으로 나타내었을 때에 正의 리터럴이 겨우 한 개로, 이러한 논리식의 집합을 혼 (horn) 집합이라 함을 전술했었다. 즉 Prolog는 혼 집합에 도출 원리를 적용시키고 있다.
그림 7-19 Prolog의 리스트 처리는 패턴 매칭으로 수행한다.
|
리스트의 표현 [a, b, c] 주: Lisp인 경우는 (a b c) 리스트[a,b,c,d]로부터 제 1요소를 끄집어 내는 데는 패턴 매칭을 수행한다. [X : Rest]와 리스트 [a,b,c,d] 을 단일화 한다. X = a Rest = [b,c,d] 로 된다. 주 : Lisp인 경우는 (CAR′(a b c d)) * a |
그림 7-20 프로그램은 문의 계열이다.
그림 7-21 OR를 포함한 문에서 AND로의 변환
|
grandfather (X, Z) : -(mother (X, Y)) ; father (X, Y)), father(Y, Z). [" ; " 는 OR를 표시] X가 Y의 어머니 또는 아버지이고, Y가 Z의 아버지라면 X는 Z의 할아버지이다. |
↓ OR를 제거
|
grandfather (X, Z) : -(mother (X, Y), father (X, Z). grandfather (X, Z) : -father (X, Y), father(Y, Z). |
그림 7-22에 Prolog에 의한 프로그램 실행 예를 보인다. (1), (2), (3)은 사실의 표현이다. (3)은 루울 (rule) 의 표현이다. (5)는 "경자가 좋아하는 것은 무엇인가"로 입력시키면, 매칭시켜 보는 머릿 부를 갖는 문을 위에서 아래의 순으로 탐색한다. (2)를 찾아 내어, 패턴 매칭에 의해 답인 "여행"을 얻게 된다. 답 다음의 " ; "는 다음의 답을 구하고 있는 입력으로, 이제 답이 없는 때는 no로 응답해 온다. 질문(8)인 경우는 답 "골프"와 루울 "사랑하는 사람이 좋아하는 것은 모두 좋다" 의 패턴 매칭을 자동적으로 수행하여 해답을 얻는다. 이것이 전술한 혼 집합에 도출 원리가 적용되는 점을 나타내고 있다. 이 탐색은 깊이 우선 탐색으로 , 데이터 베이스의 문의 나열 법에 따라 탐색 시간이 대폭으로 달라진다. 그러나 이 사실은 매칭은 주어는 입력문의 기억순에 따름으로 하여 도출의 전략을 유저에 맡겨 두게도 된다. 또 시스템이 간략하게 되는 메리트도 있다.
그림 7-22 Prolog에 의한 프로그램의 실행 예
|
(1) love (Yeoung ho ; Kyeongja) (2) like (Kyeongja;travel) (3) like (Yeongho,golf) (4) like(X, Y) : -love (X, A) like(A, y). (5) ?ㅡlike (Kyeongja, X), (6) X = Travel; (7) no (8) ? ㅡlike(Yeongho, X), (9) X = golf; (10) X = travel (11) no |
(1) 영호는 경자를 사랑한다. (2) 경자는 여행을 좋아한다. (3) 영호는 골프를 좋아한다. (4) 사랑하는 사람이 좋아하는 것은 모두 좋다. (5) 경자가 좋아하는 것은 무엇인가 (6) 여행 (; 는 다음 답을 구하고 있음) (7) 이제 답은 없음 (8) 영호가 좋아하는 것은 무엇인가 (9) 골프 (; 는 다음 답을 구하고 있음) (1) 여행 (11) 이제 답은 없음 (Prolog-KABA로 나타냄) |
이상 언급한 것으로부터 AI용 프로그램 언어에 필요한 조건을 살펴준다. 그 제 1조건은 AI에서 다루는 것은 지식이며, 종래의 컴퓨터 처럼 수치가 아니라는 것, 또 기호(지식) 처리에 알맞어야 한다는 것이다. 제 2조건은 리스트 처리이다. 그것은 프로그램을 쓰는 시점에서는 지식의 구조를 알고 있지 못하므로, 임의의 요소의 리스트를 다룰 수 있을 필요가 있다. 제 3조건은 계층적인 프로그램 구조가 필요하다. 그것은 인간의 지식의 기억구조가 계층구조를 하고 있기 때문이다. 게다가 이 프로그램을 종래의 컴퓨터에서의 데이터 처럼 다룰 수 있을 필요가 있다. 그외, 전술한 재귀적 호출 기능(어떤 함수 혹은 절차의 실행중에, 그 함수 혹은 절차를 불러 내는 것. 그림 7-13참조)이 있는 것, 대화적 프로그래밍이 가능한 것 등으로 해서 인터프리터 (interpretor) 방식으로 프로그래밍을 할 수 있을 필요가 있다(FORTRAN 은 컴파일러 방식이므로 AI용 언어로서는 알맞지 않다. Lisp나 Prolog는 이 점을 고려하여, 프로그램 개발은 인터프리터 방식으로 되어 있다).
이상 언급한 지식을 취급하고 또 계층적인 구조로 하여 기술하는 데에 적당한 언어에는, 제 5장에서 설명한 유니트표현에 알맞는 KRL이다. Frame이론으로 설명한 프레임 기술에 적당한 FRL이란 지식 기술 언어가 개발되어 있다. 또 기계 번역용의 언어로서는 構文의 기술이나 解析에는 Prolog가 일맞음을 그림 7-18에 나타내었으나, 文章의 의미를 기술하는 데에 적당한 의미 표현용 언어 SRL도 개발되어 있다.
AI용의 언어는 현재 개발 도중에 있으며, 기술 계산은 FORTRAN, 사무처리는 COBOL과 같이 패턴화된 것은 없다. 오히려 AI의 취급 대상은 복잡다단하며, 각각에 적당한 프로그램언어가 요구되는지도 모른다. 또는 각각의 취급 대상을 한정하거나 하여, 범용성이 높은 언어를 사용한다면 시스템을 만드는데 융통성이 있으나, 유저에 부담이 되고, 개발 기간이 걸리며, 불필요한 기능을 늘리는 것이 된다. 또 대상 영역에 전용의 언어를 만들면, 융통성이 없어지는 대신에 개발 기간이 단축된다.
그리고 AI연구 환경으로서, Lisp머신이나 Prolog머신과 같은 단일의 유저에 매우 강력한 CPU와 큰 메모리를 점유시켜서 개인이 사용할 수 있는 워크 스테이션도 보급되어 가고 있다. 그러나 예전부터 개인용 컴퓨터 (PC) 가 기계어로 시작되어 BASIC만능의 시대를 맞아서, PASCAL이나 그외의 고수준언어로 옮아 가는 듯이 보였을 때, 간이 언어나 통합화 소프트웨어에 그 지위를 빼앗긴 것과 같이, 쓰기 쉬운 대상 영역 마다 특성화된 전용의 AI의 언어가 쓰이고 보급될지도 모른다. 그만큼 AI가 대상으로 하는 영역은 넓고 무한하다.
그러나 한편에서는 AI의 영역은 경영 관리에 큰 역할을 가지므로,현재의 각 기업에서 쓰고 있는 메인 프레임과의 관련을 어찌 할 것인가라고 하는 문제도 제기되고 있다. 지금까지의 컴퓨터 역사는 시스템의 창조적 파괴의 연속이었던 것 처럼, 앞으로의 AI역사는 지금까지 이상으로 시스템의 창조적인 파괴를 반복해 갈 것이다. 그리고 언젠가는 인간에 가까운 창조하는 컴퓨터에 도달할 것을 기대하는 것이다.
-知識工學의 대두-
인간이 생각하는 것과 같이 컴퓨터에도 생각해 주기를 바라는 마음으로, 다트마우스會議가 열렸던 약30년전, 앞서 있었던 이들에 이어서 그림 7-23과 같은 여러 가지 종류의 추론하는 컴퓨터가 만들어져 왔다. 그것을 대별하면, 인간이 외계의 사물을 인식하여 이해하는 것과 같은 일을 하는 패턴 이해 시스템과, 그 이해하여 기억하고 있는 지식과 외계의 새로운 정보를 결합시켜, 추론하여 判斷해서 자기에 유리한 정보를 창조하는 문제 해결 시스템으로 대별된다.
전자는 인간의 눈이나 귀와 같은 패턴 認識 시스템과 인가의 두뇌가 결합된 시스템이며, 후자는 사물을 사고하여 판단하는, 소위 생각하는 컴퓨터이다. 이 양쪽의 시스템에 있어 핵심은, 꼭 같은 구조로 되어 있는 후론하는 컴퓨터 이다. 그리고 현 단계에서, 이 패턴 이해 시스템과, 문제 해결 시스템이 서로 부합하여 産業用 로봇트를 실현시키고 있는 것이다.
이 패턴 이해 시스템도, 문제 해결 시스템도, 그 지식 베이스에 기억되어 있는 지식의 量이 커지고, 그 質이 향상되면 될수록 인간의 두뇌에 접근된다. 다시말해, AI의 연구는 각각의 영역에서 인간이 갖고 있는 지식을 어떤 방법으로 추론 하는 컴퓨터에 移植시킬 것인가라는 학문, 즉 지식공학 (knowledge engineering) 이라는 새로운 학문을 태어 나게 한 것이다. 세계에서 맨 처음 엑스퍼트 시스템 (expert system) 을 만든 E. A. Feigenbaum 은 이 학문에 지식공학이란 이름을 붙인 것이다.
지식공학의 목적은 그림 7-23에 보인 바와 같이 추론하는 컴퓨터를 보다 인간의 두뇌에 가까이 하고저 하는 것으로, 최종 목적은 인간과 마찬가지로 "創造할 수 있는 컴퓨터", "학습하는 컴퓨터"를 실현시키는 것이다. 지식공학에 관하여 상세를 언급하는 것은 별도의 기회로 하고, 이하 이 책에서는 현재의 추론 컴퓨터를 응용한 응용 시스템을 그림 7-23에 따라 해설한다.
그림 7-23 추론하는 컴퓨터의 분류