자연언어의 이해
인공지능의 기법과 응용 : 김재희, 교학사, 1988, page 398~444
(2) 문장의 이해 - 문장론 (syntax), 어의론 (semantics), 실용성 (pragmatics)
2.1 주요단어 (key word) 의 정합 (matching)
(2) 하강과 상승 파싱 (top-down and bottom-up parsing)
(4) 확장된 천이회로 (augmented transition network)
(1) 어의론적 문법 (semantic grammar)
(3) 개념의존 (conceptual dependency)
3.3 개요 (schema) 와 스크립트 (script)를 이용한 이해
무엇을 이해한다는 것은 이를 한 가지
표현 방식에서 다른 표현 방식으로 변환시키는 것을 말하는데, 변환될 새로운 표현
방식은 변환된 뒤 적용 가능한 일련의 행위에 따라서 선택되어진다. 이해한다는 것에
대하여 절대적이라는 것은 거의 있을 수 없다. 예로써 항공기 예약 시스템에게 '가능한한
빨리 서울로 가고 싶다' 라고 말하여서, 이 시스템이 '이해한다' 라고 하였다면, 이
시스템은 서울로 가는 첫 비행기를 찾게 될 것이고, 만일 이같은 내용을 말한 사람의
가족이 서울에 살고 있는 것을 알고 있는 어떤 친구에게 말하여서, 이 친구가 '이해한다'
고
하였다면, 이 친구는 말한 이의 가족에게 어떤 문제가 생겼음을 알 게 되었다는 것을
의미한다.
이제 우리가 '이해' 에 대하여 논의하게 될 때 이해하는
프로그램의 성공 여하는 어떤 절대적인 의미로 측정될 수 있는 것이 아니고, 대신에
수행하게 될 어떤 특정한 업무에 대하여, 평가되게 될 것이다. 이러한 것은 언어
이해를 포함한 모든 이해하는 프로그램, 예로써 시각인식 (vision) 과 같은 것에서도
마찬가지이다.
언어를 이것에 의해 묘사되는 어떤 실제 세계나 수행하여야 할 어떤 업무들과는 무관하게, 단순히 스트링들의 모임으로 정의할 수 있는 형식적 (formal) 인 연구 방법이 있다. 이런 언어의 형식적 연구로부터 나오는 개념들은 언어를 이해하는 과정의 일부분으로 간주될 수 있지만 이는 단지 시작에 불과하다. 이해 과정에 대한 윤곽을 파악하려면, 언어를 1쌍의 요소들 [원시언어 (source language) 와 대상표현 (target representation)] 로 간주하여, 이들 사이에 서로의 어떤 대응 관계 (mapping) 가 존재하는지를 생각하여야 한다. 대상표현은 주어진 업무에 적합하도록 선택되어질 것이다. 종종 주어진 업무가 명확히 이해되고 대상표현에 관한 자세한 것이 특별히 중요하지 않을 때는, 언어 그 자체에 대하여서만 언급할 것이나, 이 때에도 대상표현은 실제로 항상 존재하게 되는 것이다.
문장 (sentence) 이 무엇을 의미하는가 하는 문제는 중요한 철학적 논쟁이 되어 왔다. 우리는 이 문제에 대한 정의를 모색하지는 않겠다. 그러나, 일단 우리가 어떤 언어를 이해한다는 것이 이 언어를 특정한 환경에 적합한 다른 어떤 표현으로 변환시킴을 뜻한다는 것을 알 게 되면, 언어 이해가 무엇이고 문장 이해가 무엇인지에 대한 답변이 왜 어려운지를 알 게 될 것이다. 우리는 이해에 대한 한 가지의 정의가 모든 것을 설명할 수 없는 그런 다양한 경우에서 언어라는 말을 사용한다.
우리가 자연언어를 이해하는 컴퓨터 프로그램을 구성하는 작업에 임하고 있는 현재 상황에서 하여야 할 첫 번째 일은, 행하여야 할 업무의 정확한 정의와 대상표현이 어떤 것인가에 대한 정의를 하는 것이다. 이런 후에는 적어도 주어진 범위 내에서는 어떤 문장이 무엇을 의미하는 것인가를 정의하기가 훨씬 쉬어질 것이다.
이해하는 문제를 어렵게 하는 다음과 같은 세 가지 주요 요인이 있다.
몇 가지 예가 이들 요인의 중요성을 보여줄 것이다.
앞서 대상표현은 업무에 적합한 것이어야 한다는 것을 언급하였다. 예로서 데이터베이스에서 키워드 (keyword) 를 사용하여 데이터를 검색하는 시스템과 영어를 이용하여 통화를 한다고 생각해 보자.
이 때 다음의 문장,
(1) I want to read all about the last presidential election.
은 일례로 다음과 같은 대상표현으로 변환될 수 있다.
(SEARCH KEYWORDS = ELECTION ∧ PRESIDENT)
이 때의 대상표현은 비교적 단순한 형태이다. 그러나 좀 더 복잡한 경우로 영어 문장을 어떤 프로그램의 입력으로 이용하되, 이 프로그램은 이 문장을 이해하여 문장에서의 여러 사건들과 이들의 관계에 대한 질문에 응답할 수 있다고 가정하고 다음의 문장을 생각해 보자.
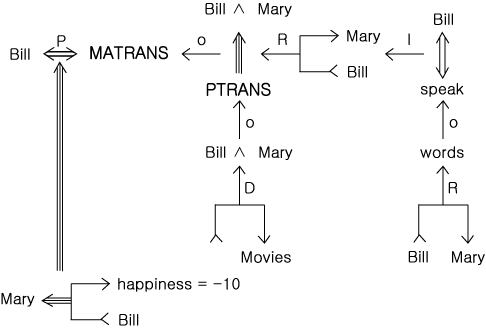
Bill told Mary he would not goo to the movies with her.
Her feelings were hurt.
그림 1 문장에 대한 개념의존 (conceptual dependency) 표현
위의 문장은 그림 1 에서 보이는 것처럼 제 6 장에서
언급한 개념의존 (conceptual dependency) 표현을 이용하여 나타낼 수 있다.
이
표현은 먼저 첫번의 예가 간단한 것에 비해 매우 복잡해진다. 일반적으로 복잡한
표현을 구성하는 것은 주어진 입력으로부터 더 많은 정보가 추출되어야 하기 때문에
간단한 표현을 구성하는 경우보다 더 어렵게 된다. 이러한 정보를 추출하기 위해서는
종종 문장이 묘사하고 있는 세계에 대한 추가적 지식의 사용을 필요로 한다. 자연언어
이해에 대한 초기작업은 매우 간단한 대상표현을 사용하였었다. 그러나 연구가 진행됨에
따라 더욱 향상된 이해를 도모하고 실제 세계와 더 유사하게 접근하기 위하여, 보다
복잡한 대상표현을 취급하는 작업들이 시도되고 있다.
이해는 원래의 형태에서 다른 유용한 형태로 문장을 대응시키는 과정이라는 것을 이미 언급하였다. 대응의 가장 간단한 형태는 1 대 1 대응이다. 프로그래밍 언어에서의 산술표현을 나타내는 언어를 생각해 보자. 이러한 언어에서는 다음과 같은 대응이 일어날 것이다.
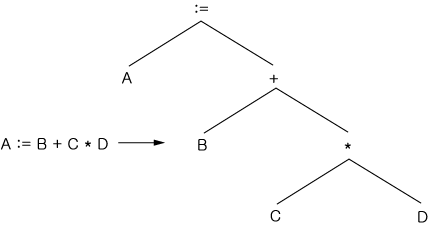
1 대 1 대응은 간단하지만 실용적인 언어에서는 별로 이용되지 않는다
다수 대 1 대응은 보다 일반적인 것으로 특히 영어 문장과 같이 풍부하고 다양한 구조와 어휘를 보다 간단하고 작은 대상표현으로 대응할 때 유용하다. 예로써 키워드 (keyword) 를 사용하는 데이터 검색 시스템에서 영어를 이용하여 입력시키는 경우를 생각하면 이 때 다수 대 1 대응이 있음을 알 수 있다.
|
Tell me all about the |
→ |
(SEARCH KEYWORDS |
|
I'd like to see all the |
→ |
(SEARCH KEYWORDS |
|
I an interested in the last |
→ |
(SEARCH KEYWORDS |
이러한 다수 대 1 대응은 대상표현을 어떻게 주어진 원시언어의 표현으로부터 얻을 것인가 하는 지식 이외에 다른 것은 별반 요구되지 않지만, 1 대 다수 대응의 경우는 여러 가능한 대상표현 중 어떤 것이 원시언어에 적합한 것인가를 선택하기 위하여 언어학적 지식 이외의 많은 지식을 필요로 한다.
예로써 다음과 같은 대응을 생각해 보자.
|
They are |
→ |
(They are (flying airplanes)) |
영어를 포함한 자연언어는 이러한 1 대 다수와 다수 대 1 의 두 가지 성격을 가지고 있다. 즉, 여러가지 표현이 같은 내용을 나타내기도 하고 (다수 대 1), 혹은 주어진 표현이 여러 가지 의미를 갖는 경우도 있다 (1 대 다수). 따라서 일반적으로 자연언어는 다수 대 다수 형태의 대응인데, 이러한 대응을 이루기 위해서는 많은 언어학적, 비언어학적 지식을 필요로 하게 되는 것이다.
대부분의 실용적인 언어에서는, 각 문장이 여러 요소들 (단어, 문자 등) 로 구성되어 있다. 문장에서의 각 요소들이 다른 요소들과 아무 관계도 갖지 않으면 대응은 간단해진다. 하지만 이들간의 상호 작용이 깊어질수록 대응은 복잡해진다. 프로그래밍 언어는 문장의 요소들 간의 상호 작용이 없는 좋은 예이다. 그림 2 는 프로그래밍 언어로 된 문장의 한 단어를 바꾸는데는, 대응되는 파스 트리 (parse tree) 에서의 한 개의 노드만 바꾸는 것으로 가능함을 보여준다.
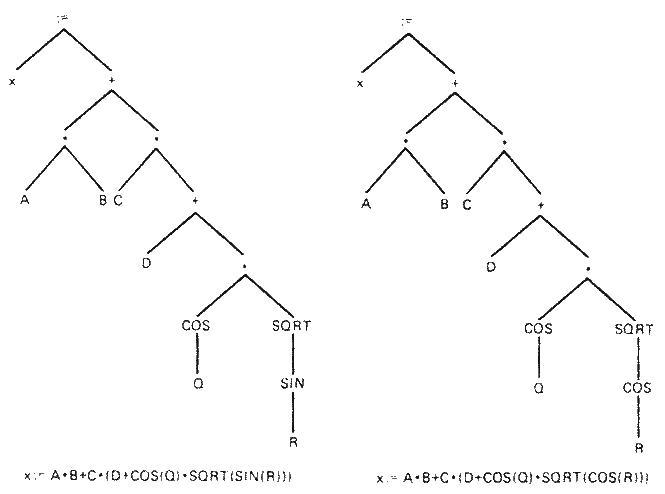
그림 2 요소들 간에 관련이 적은 경우
많은 자연언어 문장에서는 한 단어를 바꾸는 데 한 개의 노드 뿐만 아니라, 전체 구조를 바꾸어 주어야 하는 경우가 많다. 그림 3 이 그 예를 보여준다. 삼각형은 더 분석할 필요가 없는 부분을 표시한다.

그림 3 요소들 간에 상호 연관이 많은 경우
앞으로 여러 예에서 본 바와 같이 주어진 언어나 업무를 이해하는 과정을 어렵게 만드는 세 가지 주요 요인이 있다. 우리가 언급해야 할 것들이 복잡해짐에 따라 이런 문제들은 피할 수 없으며 또 극복되어야 한다. 자연언어 이해에 관한 넓은 논의와 이러한 어려운 문제의 극복을 위하여서는 다음을 참고하면 도움이 될 것이다 : [Wil 73] [Sch 75b] [Cha 76][Wal 78][Ten 81].
이 절에서는 개개의 문장을 독립적으로 이해하는 데 유용한 방법을 검토한다. 문장이나 대화에서 여러 문장이 모여지는 것을 이해하는 것은 그들 사이의 관계를 규정해야하기 때문에 아직은 어려운 작업이다. 따라서 이런 문제는 다음 절로 미룬다. 비록 여러 문장에 대하여 일관성 있는 해석을 한 번에 하는 것은 어렵지만, 일단 한 부분에 대한 해석이 얻어지면, 이를 이용하여 나머지 부분들을 이해하는 데 사용할 수 있을 것이다. 때로는, 단일 문장만 보고 해석할 수 없는 경우가 발생하게 되는데, 이 문제는 역시 군집된 문장이 해석될 때까지 보류되어야 한다. 단일 문장을 이해하기 위하여 다음의 두 가지가 필요하다.
이 작업의 처음 단계는 우선 보기에는 쉬운 것처럼 보인다. 예로써 각 단어에 대하여 이에 대응되는 대상표현을 저장한 사전 (dictionary 혹은 lexicon) 을 이용하여 간단히 해결될 것같은 생각을 갖게 된다. 하지만 많은 단어들이 하나 이상의 의미를 갖기 때문에 단어 자체만 보고 올바른 의미를 선택한다는 것은 매우 어렵다. 예를 들어 다이아몬드는 다음과 같은 의미들을 갖는다.
다음과 같은 문장을 생각해 보자.
John saw Susan's diamond
shimmering from across the room.
(존은 방 저편에서
수잔의 다이아몬드가 반짝이는 것을 보았다.)
여기서 기하학적 모양이나 야구장은 반짝이지 않지만, 보석은 반짝인다는 것을 알아야 한다.
각 단어의 정확한 의미를 결정하는 과정을 단어 의미 분명화 (word sense disambiguation), 혹은 어휘적 분명화 (lexical disambiguation) 라고 한다. 이는 사전 (lexicon) 에서의 각 단어에 대하여, 이 단어의 여러 의미 중 각각이 문맥 중에서 의미할 수 있는 정보를 첨부시켜 놓음으로써 해결된다. 문장에서의 각 단어는 다른 단어의 의미를 파악하기 위하여 사용될 수 있게 된다.
때때로 단어에 대한 매우 단순한 정보만이 사용되는 경우가 있다. 예를 들면, 다이아몬드가 야구장으로 쓰일 때를 위하여 이런 경우를 장소 (LOCATION) 로 표시하여 놓는다. 이 때 다음의 문장 "I'll meet you at the diamond" 에서 전치사 at 이 목적어로 시간이나 장소 (장소적 목적어) 를 갖는다는 사실을 기록해 놓았다면, 다이아몬드의 의미를 쉽게 파악할 수 있을 것이다. 그와 같은 표시를 어의적 부호 (semantic marker) 라 부른다.
다른 유용한 어의적 부호로는 다음과 같은 것이 있다.
이러한 부호들을 사용하면 주어진 문장에서 단어의 의미는 보다 분명해진다. 예로써 'I dropped my diamond' 을 생각해 보자. 사전에서 drop 에 해당하는 곳에는 drop 의 목적어가 물리적 - 물체이어야 한다는 표시가 있을 것이다 (물론 다른 부호도 있을 수 있다). 또한 diamond 의 의미 중의 하나로써 물리적인 물체라는 표시가 있으므로, 이때의 diamond 의 의미는 보석이라는 것을 알 수 있다.
어휘적 분명화의 문제를 완전히 해결하기 위해서 더욱 많은 어의적 부호의 도입이 필요하다. 하지만 그런 부호의 수가 증가됨에 따라 기억해야 할 단어의 양은 처리하지 못할 만큼 커지게 된다. 또한 사전에 새로운 단어가 수록될 때마다 기존의 많은 어의적 부호중 해당되는 것은 모두 표시하여야 하므로 다른 연구 방법이 필요로 하게 되는데, 이에 대한 것은 차후 논의하기로 한다.
또 다른 접근 방법으로는 지역적 (local) 정보에 의존하는 것인데, 선호 어의론 (preference semantics) 이라 불린다 [Wil 72][Wil 75a][Wil 75b]. 예를 들면, hate 같은 동사는 주어로서 살아있는 동물을 선호하게 된다. 따라서 다음 예문을 생각하여 보자.
Pop hates the cold.
(팝은 추운 것을 싫어한다)
이 문장은 어떤 음료수의 종류를 묘사하는 것이 아니고, 사람의 느낌을 묘사한다는 것을 알 수 있다 (Pop 은 음료수의 일종이기도 함). 그러나,
My lawn hates the cold.
(잔디는 추운 것을 싫어한다)
에서는 주어가 살아있는 동물은 아니나, hate 는 살아있는 동물을 선호한다는 것이지 필수적으로 선택한다는 것은 아니므로, 잔디 (lawn) 에 대한 비유적인 표현으로써 선택함으로써 이 문장을 이해하게 된다.
이해 과정의 두번째 단계로, 문장의 의미를 표현하는 구조를 형성하기 위하여 단어를 결합하는 것도 또한 쉽지 않다. 문장의 이해를 위해서는 정말로 다양한 정보가 필요한데,예로써 사용되는 언어에 대한 지식, 토의되는 분야에 대한 지식, 그리고 대화자들이 통상적으로 언어를 사용하는 방식들에 관한 것들이 포함될 수 있을 것이다. 이처럼 해석 과정에는 많은 것들이 포함되므로 해석 과정을 쉽게 하기 위하여 이를 다음의 세 부분으로 분리한다.
"Boy the go the to store."
"Colorless green ideas sleep furiously."a
이 세 가지들의 경계는 애매한 것이 보통이다. 이 단계들은 때로는 순차적으로 행해지기도 하고, 때로는 모두 일시에 행하여지기도 한다. 이들이 순차적으로 행해지는 경우에는 다른 단계로부터 도움을 얻을 수 있다. 예로써,
"John went to the drug store with the ice cream counter."
라는 문장의 구성을 분석하는 과정에서 전치사고 " with the ice cream counter" 에 의하여 수식되는 것이 어느 것인지를 결정하는 것을 생각해 보자. ice cream counter 가 있는 drug store 를 의미하는 것인지, 혹은 John 이 ice cream counter 와 함께 drug store 로 갔는지는 문장 의미의 분석 단계에서 결정하는 수 밖에 없다. 따라서 종종 이러한 단계들을 구별하는 것이 유용하긴 하지만, 이들이 서로 상호관계가 있을 수 있으므로, 이 단계들을 완전히 구분하는 것은 불가능하다.
언어의 이해 문제에 대한 아주 단순한 해결 방법으로는, 필요한 모든 작업을 한 단계로 모아서 해결하는 방법이 있다. 이 방법은 입력문장을 주요단어 (keyword) 로 구성된 간단한 템플릿 (template, 형틀) 들에 대해 비교시킴으로써 이루어진다. 이러한 방법의 이점은 문법이 비정상적인 문장도 인식될 수 있다는 것이다. 이 방법에서는 알려진 단어들만이 인식되고 나머지들은 무시된다. 이러한 방법을 근사적인 정합 (approximate matching) 이라고 생각할 수 있다. 이 방법을 사용한 프로그램은 두 가지가 있다. 하나는 ELIZA [Wel 66] 이고, 다른 하나는 PARRY [Col 75] 이다.
이러한 주요단어를 준비된 템플릿에 대응시켜서
인식하는 방법은 원래 문장을 정확하고 세밀하게 이해하는 것이 목표는 아니다. 이러한
방법은 실제로는 사람들로 하여금 프로그램이 언어를 이해하는 것처럼 착각하게 만드는
것에 지나지 않는 것이다. 그림 4 는 ELIZA 에 의해 사용된 각본의 일부이다.
이
각본은 입력문장에 대하여 정합될 수 있는 템플릿들을 포함하고 있다. 각 입력 템플릿에
대해서는 적당한 응답을 위한 한 개 이상의 출력 템플릿이 연관되어 있다. ELIZA
는 입력문장을 이의 의미를 나타내는 내부 구조로 대응 (mapping) 시키는 방식으로
입력문장을 이해하는 것은 아니다. 단지 입력문장은 직접 적당한 응답으로 대응되고는,
곧 잊혀진다. 출력을 구성하는 과정을 간략히 하기 위해, 어떤 단어들은 출력에 적합한
새로운 형태로 즉각 번역되기도 한다. 예를 들면, I 는 You 로, me 는 you 로 즉각
번역된다. 따라서 환자가 "(I cried." 라고 하면 ELIZA 는 "Why did
you cry?" 라고 응답한다. 이러한 즉각적인 번역은 다른 템플릿의 사용을 시도하기
전에 이루어진다.
ELIZA 각본은 기본적인 주요단어 (keyword) 로 구성되어 있는데, 위의 예에서 보이는 첫째는 remember 이다. 단어 remember 에 대해서는 두 개의 입력 템플릿이 있다.

그림 4 ELIZA 의 각본
이 템플릿에서 0 은 어떤 갯수의 단어도 정합 (matching) 된다 (하나도 없는 경우도 포함). 각 입력 템플릿은 여러 개의 관련된 출력 템플릿을 갖는다. 이러한 출력 템플릿에는 숫자가 (4 와 같은) 저장되어 있는데 이는 입력 템플릿에서 이 숫자의 순서에 (4번째) 대응되는 부분을 출력에서 숫자가 놓인 곳에다 삽입시키라는 뜻이다.
예를 들어, ELIZA 에게 "I remember the first time I went to the beach." 라고 말했을 때, 이 입력과 대응되는 형틀은 (0 YOU REMEMBER 0) 이고 (이때 이미 I 가 YOU 로 대치되었음), 이 때 4 번째에 대응되는 부분은 'the first time you went to the beach' 이다. 만일 입력 템플릿 (0 YOU REMEMBER 0) 에 대한 첫번째 출력 템플릿 (DO YOU OFTEN THINK OF 4) 을 사용한다면 4 에 해당되는 'the first time you went to the beach' 를 삽입시켜, 결과의 출력은
'DO YOU OFTEN THINK OF THE FIRST TIME YOU WENT TOO THE BEACH'
가 된다.
일반적으로 하나의 입력 템플릿은 여러 개의 관련된
출력 템플릿을 갖게 되고, ELIZA 는 이들을 교대로 사용하게 된다. 이와같은 템플릿을
사용할 때는 동일하게 취급되어야 할 단어들을 한 곳으로 모아 이용할 수 있으면
편리하다. 이 예에서는 FAMILY 는 mother, mom, dad, father 의 그룹을 나타내는
단어이다. 단어 'your' 에 관한 입력 템플릿 중 처음 것을 보면 FAMILY 가 어떻게
사용되는지를 알 수 있다. ELIZA 에게 "My brother is mean to me." 라고
말할 때 두번째 출력 템플릿이 적용되면, "Who else in your family is mean
to you?" 라고 응답할 것이다. 템플릿을 정합시키는 시스템에서는 주어진 입력문장에
대해서 하나 이상의 템플릿이 대응되는 경우를 처리하여야 한다. ELIZA 의 경우는
각 단어에 순위번호를 부여하여 이 문제를 처리하였다. 즉, 입력문장 중 최고의 순위를
갖는 단어에 대응되는 템플릿이 우선적으로 선택한다. 이 예에서는 컴퓨터가 순위
50 을 가지므로 가장 높은 순위가 된다.
그 반대 경우로, 대응되는 템플릿이 없을
때도 고려하여야 하는데, ELIZA 의 경우에는 항상 어느 문장과도 대응되는 템플릿을
구비하였다. 이러한 템플릿은 단순히 (0) 으로 되었는데, 예로써 "Can you elaborate
on that?" 같은 범용 목적의 응답을 출력한다. 이러한 방식의 주요 단점은 문장이
포함하고 있는 많은 정보를 무시하는 것이다. 예로써, "My friend's sister
likes me" 라는 입력에 대하여 ELIZA 는 "Tell me more about your family."
라고 my 와 sister 사이의 단어인 friend 를 무시하게 되고 만다. 그러나 실제는
my 가 sister 를 수식하는 것이 아니므로 이 응답은 부적당한 것이다.
|
S → NP VP |
그림 5 영어의 일부분에 대한 간단한 문법
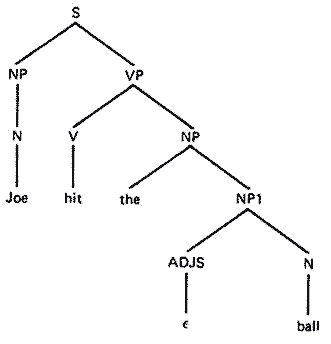
그림 6 문장에 대한 파스 트리 (parse tree)
그림 5 는 영어의 일부분에 대한 간단한 문법을 나타내며, 그림 6 은 이러한 문법을 이용하여 'John hit the ball" 의 문장에 대한 파스 트리를 보여준다. 알아야 할 것은, 파스 트리의 구조는 출발 심볼 S 에 문법의 법칙들을 적용시키면서 최종적으로 주어진 문장을 얻을 수 있음을 보여준다는 것이다.
파싱 과정에서는 다음의 두 가지 일을 처리한다.
이를 생각하면, 어떤 언어에 대한 문법을 만들 때에는 세 가지를 같이 고려하여야 한다. 즉, 원하는 모든 문장을 만들어 낼 수 있어야 하고 이 문장에 유용한 구조를 배정할 수 있어야 한다. 또한 문법은 보다 효율적인 파싱이 가능하도록 하여야 한다.
공식적으로 문법은 다음과 같이 구성된다.
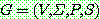
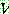 는 전체 어휘 (vocabulary) 를 나타내는 유한하나 공집합이 아닌 집합.
는 전체 어휘 (vocabulary) 를 나타내는 유한하나 공집합이 아닌 집합.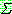 는 종단 알파벳 (terminal alphabet) 이라고 불리우며,
는 종단 알파벳 (terminal alphabet) 이라고 불리우며, 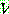 의 부분집합으로 공집합은 될 수 없다.
의 부분집합으로 공집합은 될 수 없다. 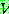 에서
에서 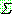 를 제외한 나머지를 비종단 알파벳 (nonterminal alphabet) 이라고 하며, 이들의
집합을
를 제외한 나머지를 비종단 알파벳 (nonterminal alphabet) 이라고 하며, 이들의
집합을 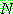 으로 나타낸다.
으로 나타낸다.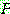 는 다음과 같은 형태의 생성규칙 (production) 들의 유한한 집합.
는 다음과 같은 형태의 생성규칙 (production) 들의 유한한 집합. , 여기서
, 여기서 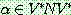 이고
이고 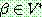
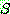 는 비종단 알파벳의 한 요소이며 출발 심볼 (start symbol) 이라 불린다.
는 비종단 알파벳의 한 요소이며 출발 심볼 (start symbol) 이라 불린다.이 장에서는 비종단 심볼들은 대문자로,
종단 심볼들은 소문자로 쓰게 될 것이다. 또한 문법을 보다 간결하게 나타내기 위하여,
여러 규칙들(즉, 생성규칙에 의하여 주어지는)중 왼쪽 심볼이 같은 것은 하나로 묶되,
오른쪽 것들은 'ㅣ' 로 구분시키고 이것을 or 로써 읽는다. 빈 (empty) 스트링은 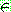 으로 나타내며 이는 아무것도 없음을 나타낸다.
으로 나타내며 이는 아무것도 없음을 나타낸다.
각 문법에 대하여,
이 문법에 의하여 정의되는 언어가 있다. 이 언어는, 문법에서 주어진 출발 심볼에다
문법에서 주어진 규칙들을 유한한 횟수만큼 적용시켜 얻어지는, 종단 심볼들로써
구성되는 모든 스트링들의 집합으로 정의된다. 즉, V 는 문법에서 사용되는 모든 심볼들의
집합을 나타내며, 이 중의 일부는 종단 심볼들로써, 이들의 집합이 Σ이다. 출발
심볼로부터 시작하여 문법의 주어진 규칙을 적응시켜 나가면 종단 심볼들로써만 구성되는
스트링을 얻을 수 있다. 이렇게 얻어지는 모든 스트링들의 집합이 이 문법에 의하여
정의되는 언어인 셈이다. 예로써 다음의 스트링들은 그림 1의 문법에 의하여 정의되는
언어에 포함된다 (여기에서 정의한 바에 따르면, 영어에서는 각 단어가 종단 심볼에
해당하고, 각 문장이 종단 심볼로 구성된 스트링에 해당된다).
(1) The boy ran.
(2) The ball hit.
(3)
Ball hit the Joe.
세 번째 문장은 영어가 아님을 잘 알아두어라. 그러나
이는 주어진 문법에 의하여 정당하게 얻어지는 문장 (sentence) 임에는 틀림이 없다.
(결국
이는 앞서의 문법이 영어를 나타내기에는 부적당한 문법임을 알 수 있다).
다음의
것들은 상기 문법에 의하여 얻어질 수 있는 스트링은 아니다.
(1) the NPI ran.
(2) Joe the ran.
(3)
The girl ran.
첫 번째 문장은 종단 심볼이 아닌 것을 포함하고 있으므로,
주어진 언어에 포함될 수 없다.
하나의 주어진 언어에 대해 여러
문법이 존재할 수 있다. 여러 문법이 같은 언어를 묘사한다고 해도 유용성의 측면에서는
동등하지 않을 수가 있다. 어떤 문법은 파싱을 상당히 효과적으로 처리할 수 있고,
반대로 어떤 것은 파싱을 위한 탐색에 많은 시간이 소요되기도 한다. 또한 같은 문장에
대하여 다른 문법들은 다른 파스 트리를 형성하게 되는데, 이는 주어진 문장에 대한
파스 트리는 이 문장을 생성하기 위하여 사용되는 생성규칙들을 반영하기 때문이다.
파싱을 하기 위해서는, 주어진 문장이 어떻게 출발 심볼로부터 생성되었나를 알아야 한다. 이를 위한 방법은 두 가지가 있다.
이 두가지 방식 중 어느 것을 선택할 것인가는, 주어진
업무에 비추어 선택하여야 한다. 때로는 이 두 가지 방식을 결합한 하강 여과를 지닌
상승 파싱 (bottom-up parsing with top-down filtering) 을 사용하는 수도 있는데,
이 경우에는 파싱은 상승으로 하나 (즉, 생성규칙을 역방향으로 적용시킴), 미리 준비된
표를 이용하여 가능성이 없는 것은 (즉, S 로 갈 수 없는 것) 중도에 제거된다. 앞서
주어진 몇 개의 예에서 알 수 있듯이, 문장을 이해하는 과정은 여러 가능한 해석이
놓여진 공간에서 특별히 문장에서 주어진 여러 제한을 만족하는 한 가지 해석을 찾는,
일종의 탐색에 해당하는 것이다. 다른 탐색과 마찬가지로, 이 경우에도 모든 가능한
경로를 검토할 것인지, 아니면 가장 가능성 있는 경로를 검토하여 이의 결과를 답으로
할 것인지를 결정하여야 한다.
예로써, 문장을 이해하는 프로그램이
입력문장의 단어를 한 번에 한 개씩, 왼쪽부터 오른쪽으로 처리한다고 가정하자.
입력 중 다음의 문장까지를 처리하였다고 하자.
Have the students who missed the exam
이때에 이 프로그램이 따를 수 있는 다음의 두 가지 경로가 가능하다.
이와 같은 문장을 처리하는데는 다음의 네 가지 방법이 있다.
(1) 모든 경로 추적 - 가능한 모든 경로를 고려하여
각각의 경로에 대항 잠정적인 결과를 내었다가 이를 요구할 것으로 기대되는
입력이 나타나지 않으면 이를 제외시킨다. 위의 예에서 have를 조동사로 설정했다가
taken같은 과거분사가 나오지 않으면 조동사로 설정한 것을 제외시킨다. 이 방식은
모든 경로를 고려하므로 비효율적이다.
(2) 백트래킹 (backtracking)
을 사용하는
최적경로 추적 - 한번에 한 경로만 선택하되, 어떤 경로를 따랐을 때 해석이
실패할 경우 다른 선택을 하기 위한 필요 정보를 매 선택점마다 기억해 놓고,
선택한 경로가 문장을 완전히 해석하지 못하였을 경우에는 저장한 정보를 사용한다.
이 예에서는 만일 have를 조동사로 해석할 것을 우선 선택하였으나, 문장이 끝날
때까지 본동사가 나타나지 않으면, 프로그램은 이러한 선택이 실패임을 깨달아
먼저의 선택점으로 백트랙 (backtrack) 하여 다른 경로를 선택한다. 이 방법의
단점은 각 선택점에서 상태 정보를 저장하는데 많은 시간과 공간이 소요되고,
같은 문장 요소들이 여러번 분석될 수도 있는 것이다. 우리의 예에서 만일 have에
대한 선택이 잘못되었다면 이의 잘못은 'the student who missed the exam' 의
부분이 읽힐 때까지 인식되지 못할 것이다. 일단 잘못되었다는 것을 알게되면,
간단한 백트래킹을 사용하는 경우에는 have 이후의 모든 해석을 취소하고, have
에
대한 두 번째 선택을 한뒤, have 뒤의 모든 해석을 다시하게 될 것이다.
(3)
패치 업 (path-up) 을 이용한 최적경로 추적 - 이 방법에서는 한 번에 한 경로만을
추적하여 해석을 시도하지만, 일단 이 경로의 선택이 잘못되었음이 밝혀지면,
이미 해석된 문장요소들을 다시 배열시킨다. 예로써 앞에서 주어진 보기를 살펴
보자. 만일 have 를 조동사로 선택하여 해석을 시도하였다면 다음에 뒤따르는
명사구 'the student who missed the exam' 을 해석하고, 이를 문장의 주어로써
기록하여 놓을 것이다. 만일 이 뒤에 taken 이 나타난다면, 이 선택경로는 계속될
것이다. 그러나 만일 take 가 다음에 나타났다면, 프로그램은 have 가 주동사임을
알 게 되고, 문장의 주어는 you (명령문이므로) 임을 알 게 되며, 이미 해석된 'the
student who missed the exam' 은 문장의 주어는 아니나, 이의 해석을 또다시
하지는 않고, 단지 문장에서의 이 명사구의 역할을 재조정한다. 이 방법은 앞서의
다른 두 방법보다는 효율적이기는 하지만, 이를 위하여서는 문법에서의 법칙간의
상호 관계가 분명히 명시되어 문장요소들이 한 곳에서 다른 곳으로 이동할 수
있어야 한다.
(4) 대기 및 관찰 (wait-and-see) - 이 방법에서는 한 경로만
따라가지만, 문장의 각 요소를 만나게 되면 그 기능을 결정하지 않고, 후에 충분한
정보가 얻어져서 정확한 결정이 가능할 때가지 보류한다. 이 방법을 우리의 예에
적용시켜 보자. 이 문장에서 have를 만났을 때, 이는 동사로써 그 기능은 아직
알려져 있지 않은 것으로 기록된다. 뒤따르는 명사구는 해석되어 단순히 명사구로써
기록된다. 다음 단어를 만났을 때, 이제까지 만난 모든 요소들을 어떻게 구성시켜야
할 것인지를 결정할 수 있게 된다. 여러 파서 (parser) 가 이러한 방법을 사용하였는데
그 중 특히 PARSIFAL [Mar 79] [Mar 80]이 이 방법을 집중적으로 사용하는 예가
되겠다. 이러한 방식은 상당히 효율적이기는 하지만, 만일 대기하는 정보가 많게
되면 해결이 곤란하게 된다. 그러나 이러한 경우에 대해서는 인간도 같은 어려움을
겪는 것이 보통이다. 예로써,
The horse raced past the barn fell down.
이 경우, 말 (horse) 이 넘어진 것 (fell down) 인지 아니면 헛간 (barn) 이 무너진 것 (fell down) 인지 애매하다.
이렇듯 어떤 경로를 따를 것인지 결정하는 문제와 어떻게 백트랙을 처리할 것이냐는 모든 탐색 과정에 있어서 생기는 공통적인 문제이지만, 이들이 언어 이해에 있어서 더욱 복잡하게 되는 것은, 언어에는 선천적으로 애매한 문장들이 존재하기 때문이다. 예로써 "They are flying plane." 은 예를 상기해 보면 된다. 만일 한 가지 해석이 아닌 가능한 모든 경우의 해석이 필요하다면, 모든 경로를 따라하거나 (이는 상당히 비효율적인데, 이유는 이들 대부분이 문장의 끝을 만나기 전에 제거되기 때문이다) 아니면 강제적으로 백트래킹을 시킨다 (이 역시 중복된 연산을 하므로 비효율적이 된다). 많은 실용적인 경우에는 하나의 가능한 해석을 찾는 것으로 만족하게 된다. 이 해석이 후에 의미의 불합리나 혹은 실용적인 이유에서 거부된다면, 다른 해석을 찾는 새로운 작업이 수행될 것이다.
앞서 주어진 문법의 정의에는, 생성규칙 (production) 의 형태에는 아무런 제한도 가하지 않았다. 즉, 규칙의 양쪽 어디에나 임의의 수의 심볼이 놓일 수 있었고, 규칙은 순환적 (recursive), 즉 오른쪽을 정의할 때 자기 자신을 이용하여 정의할 수 있는 것으로 예를 들어 A→aA 와 같은 것을 말한다. 이렇듯 제한이 전혀 없는 문법을 사용하여 생성된 문장류의 제한이 가해지면 연산적으로 더 효율적인 파싱 방법이 개발될 수 있다. 하지만 파싱을 쉽게 하기 위하여 규칙의 형태에 제한을 주면 그만큼 묘사되는 언어의 종류가 제한되게 된다. 언어는 그 언어를 생성하는 최대로 제한되는 문법의 정도에 따라 그림 7 과 같은 종류를 갖는다. 이는 촘스키 계층 (Chomsky hierachy) 이라고 하는, 제한된 문법의 형태(따라서 각 문법에 의하여 생성되는 언어도 제한됨) 를 정의하는 한 가지 방법이다.
|
종류 |
언어 종류 |
규칙의 제한 |
|
0 |
순환적 열거가능 (recrusively enumerable) |
제한 없음 |
|
1 |
문맥 의존 (context sensitive) |
길이를 줄이는 규칙은 없음 |
|
2 |
문맥 자유 (context free) |
규칙의 왼편은 반드시 하나의 비종단 (nonterminal) 알파벳일 것 |
|
3 |
정규 (regular) |
왼편은 하나의 비종단이고, 오른편은 하나로 된 종단(terminal) 알파벳이거나 혹은 하나의 종단뒤에 하나의 비종단이 놓일 것 |
그림 7 촘스키 계층 (Chomsky hierarchy)
이 언어의 계층에서 제일 밑에 있는 정규언어는
매우 효율적인 파싱 과정에 의하여 인식될 수 있다. 어떤 언어를 인식한다는 것은
임의의 입력 스트링 (영어의 경우는 문장) 이 이 언어에 속하는지 여부를 판별하여
줄 수 있다는 것이다. 즉, 주어진 입력이 정하여진 언어를 생성하는 문법에 의하여
만들어질 수 있나의 여부를 알려주는 것이다. 정규언어는 유한상태기계 (finite state
machine) 에 의하여 인식될 수 있는데, 유한상태기계는 하나의 상태를 다른 상태로
변환하는 방법에 의하여 묘사된다. 이 기계는 유한한 갯수의 상태를 갖는데, 이 중의
하나는 시작상태 (start state) 이고, 또 하나 이상의 끝상태 (final state) 를 지닌다.
상태들은 심볼로써 표시된 아크에 의하여 연결되는데, 이 심볼은 입력의 한 문자에
해당된다. 입력 스트링에 대하여, 시작상태에서 출발하여, 각 입력 심볼에 따라 순서적으로
상태를 변환하여, 모든 입력 심볼이 끝났을 때 끝상태에 놓이게 되면, 이 입력은
정하여진 언어에 속하는 것으로 간주된다. 그림 8 은 1 의 갯수가 홀수인, 0 과 1
로
구성된 스트링을 받아들이는 (accept) 유한상태기계의 예이다.

그림 8 유한상태기계
유한상태기계는 쉽게 구성할 수
있고 효율적이지만, 자연언어에는 정규 (regular) 문법이 부적합하므로 사용하기 곤란하다.
정규 문법 형태는 가장 제한된 것으로 끼우기 (embedding) 가 허용되지 않는다. 자연언어에서는
비교절 등을 처리하기 위해서는 끼우기가 절대 필요하다. 비록 간단한 프로그래밍
언어의 경우라도, 중복된 괄호 표현 등을 위해 끼우기가 필요한 것이다. 따라서 정규
언어 (regular language) 의 인식은 언어 인식의 초기적 과정인 어휘 분석 (lexical
analysis) 에서 사용되는데, 이는 주어진 단어가 올바른지 (예로써 FORTRAN 에서 2XY
는
에러) 를 판단하는데 사용되는 정도이다.
문맥자유(context free)
언어에서는(특히 결정적 [deterministic] 인 경우) 효율적인 파싱 알고리즘을 얻을
수 있고, 이는 프로그래밍 언어의 컴파일러 구성에 많이 쓰이고 있다. 비록 대부분의
프로그래밍 언어는 이러한 문맥자유규칙에 의하여 묘사될 수 있지만, 자연언어의
경우는 그렇지 못하다 (문맥자유규칙의 경우는 각 규칙의 왼쪽은 반드시 비종단 (nonterminal)
한 개로만 되어야 한다는 제한이 있다). 이는 비종단을 확장시킴에 있어서 주위에
무엇이 있든지 상관 없다는 것이고, 따라서 문맥자유 (context-free) 라는 말을 붙인
것이다.
그러나 이도 영어와 같은 자연언어에서의 문제를 해결하기에는
부족하다. 예로써 그림 5 에 주어진 간단한 문법을 다시 생각해 보자. 여기에서의
규칙들은 명사구와 동사구의 구조를 나타내고 있다. 그러나 문장에서 주어의 수가
동사의 수와 같아야 한다는 것은 어디에도 주어져 있지 않고 있다. 이는 NP 와 VP
가
각각 따로 확장되기 때문에 이러한 제한을 줄 수 없는 것이다. 이를 피하기 위하여,
S → SINGNP SINGVP |PLURALNP PLURALVP
와 같이 나타낼 수도 있으나, 이렇게 하면, NP와 VP에 대한 규칙 대신에 SINGNP 와 PLURALNP, 그리고 SINGVP 와 PLURALVP 를 위하여 많은 규칙이 필요할 것이고, 이들 모두가 규칙의 중복인 셈이다. 이러한 중복은 자연언어 중 문맥자유가 아닌 부분에서 계속 나타날 것이다. 그러나 문맥자유언어를 파싱하는 것이 그렇지 못한 문맥 의존등에 비하여 훨씬 효율적이므로, 종종 영어 등을 문맥자유인 것처럼 간주하여 파서 (parser) 를 구성한다. 물론 이 경우 받아들이지 말아야 할 스트링들을 받아들이는 경우도 생기게 된다.
영어문장을 완전히 처리하기 위해서는 촘스키 계층 (chomsky hierarchy) 중 최고의 언어 종류를 인식할 수 있는 튜링 기계 (turing machine) 정도의 능력이 필요하다. 더불어서 보다 효율적으로 문장을 인식하기 위해서는 그러한 파싱 (parsing) 시스템에 다양한 지식을 첨부시킬 수 있어야 하는데, 확장된 천이회로 (이하 ATN 으로 약함) 가 이러한 목적으로 사용된다. ATN 은 유한상태기계와 비슷한 것으로 상태간의 변환을 정의하는 아크에 첨부될 수 있는 표시의 종류가 유한상태기계보다 다양해진 것이다. 아크는 다음의 어느 것으로도 표시되어 질 수 있다.
(1) 특별한 단어
(2) 문장의 중요한 요소를 인식하는 다른 회로로 이동시킴. 이러한 이동은 순환적일 수 있어, 자기회로로 직접 혹은 간접적으로 다시 이동되어 올 수 있음.
(3) 현재의 입력과 이미 인식되어진 문장 요소들에 대한 임의의 테스트를 위한 프로그램들.
(4) 최종적인 파스 트리의 일부를 형성하는 구조를 만드는 프로그램 코드들.
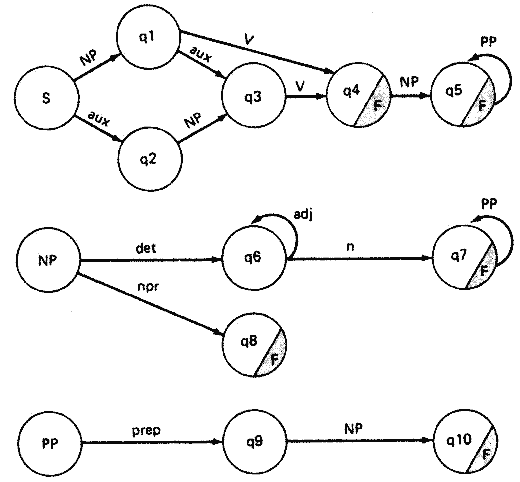
그림 9 영어의 일부분을 위한 ATN 의 예
이렇듯 다양한 조건들이 아크와 관련지워 질 수 있으므로, ATN 은 튜링 기계의 모든 능력을 소유한다. 그림 9 는 ATN 의 예를 그래프 표시로써 나타낸 것이다.
그림 10 은 그림 9 의 제일 위의 것을 프로그램의 형태를 이용하여 나타낸 예이다.
|
(S/
(PUSH NP/ T (CAT
AUX T (Q1
(CAT V T (CAT
AUX T (Q2
(PUSH NP/ T (Q3
(CAT V T (Q4 (POP (BUILDQ (S + + + (VP +)) TYPE SUBJ AUX V) T) (PUSH
NP/ T (Q5 (POP(BUILDQ (S + + + + ) TYPE SUBJ AUX VP) T) (PUSH
PP/ T |
그림 10 리스트 형태로써 나타낸 ATN 문법의 예
ATN 의 동작을 살펴 보기 위하여, 다음의 문장을 ATN 이 파싱하는 과정을 살펴 보자.
The brown dog has gone.
이는 다음과 같이 수행된다.
(1) 상태 S 에서 출발.
(2) NP 로 이동 (push).
(3) the 가 정관사 (det) 인가를 알아본다.
(4) 정관사이므로, 정관사와 관계된 레지스터 DETERMINER 를 정관사 (DEFINITE) 로 기록되게 한 후 q6 의 상태로 간다.
(5) brown 이 형용사 (adj) 인가 검토한다.
(6) 형용사이므로 형용사와 관계된 레지스터 ADJS 에 포함되는 리스트에 brown 을 첨부시킨다.
(7) dog 이 형용사인가 검토한다. 검토 결과는 틀린 것으로 판명된다.
(8) dog 이 명사 (n) 인가를 검토한다. 맞으므로, 명사와 관계된 레지스터 NOUN 을 dog 으로 하고 q7 상태로 간다.
(9) PP 로 이동 (push).
(10) has 가 전치사 (prep) 인가 검토한다. 아니므로 실패를 알리고 빠진다 (pop).
(11) q7 상태에서는 더 이상 할 것이 없으므로, 다음의 구조를 갖고 빠진다 (pop),
(NP (DOG (BROWN) DEFINITE))
q7 에서 빠지면 q1 상태로 가게 되며, 이 때 레지스터 SUBJ 는 위의 구조를 갖게 되고, 레지스터 TYPE 는 DCL (서술문 ; declarative) 을 갖게 된다.
(12) has 가 동사 (V : Verb) 인가를 검토한다. 결과가 맞으므로 레지스터 AUX 를 NIL 로 하고 레지스터 V 를 has 로 한다. q4 상태로 간다.
(13) NP 상태로 이동 (push) 한다. 다음 단어인 gone 이 정관사 (det) 나 명사고 (noum phrase) 가 아니므로 NP 는 실패로 되어 빠진다 (POP).
(14) q4 상태에서는 정지하는 것 이외에는 달리 할 것이 없다. 그러나 아직도 입력에는 단어가 남아 있으므로, 완전한 파싱이 된 것은 아니다. 따라서 뒤로 되돌아 (backtracking) 가게 된다.
(15) 이전에 q1 상태가 최종 선택기로점이었기 때문에 그곳으로 돌아간다. AUX 와 V 레지스터를 지운다.
(16) has 가 조동사 (aux) 인가 검토한다. 검토 결과가 성공이므로, 레지스터 AUX 는 has 의 값을 갖고 q3 상태로 간다.
(17) gone 이 동사인가 검토한다. 결과가 성공이므로 레지스터 V 를 gone 으로하고 q4 상태로 같다.
(18) 이제 모든 입력이 소비되었으므로, q4 는 받아들일 수 있는 최종상태가 된다. 다음의 구조를 갖고 빠진다.
(S
DCL (NP (DOG (BROWN) DEFINITE))
HAS
(VP
GONE))
이 구조가 파싱의 결과 출력이 된다.
이상의 문법의 예에서 ATN 의 사용에 대한 몇 가지 중요한 점을 알 수 있다.
the boy with the dog with the long tail
(SETR TYPE (QUOTE DCL))
혹은, 현재의 입력으로부터 얻는 값일 수도 있는데, 다음의 예에서 보자.
(SETR SUBJ *)
여기서, * 는 변환을 허용하는 구성인자이며, 이 경우는 찾아낸 NP 를 나타낸다.
이 밖에도 이 예에서는 보이지 않으나, ATN 에 대한 이용 방법은 많다.
John
hit Mary.
Mary
was hit by John.
ATN 에 대하여 생각할 때에 중요한 것은 ATN 의 형식 그 자체는 어느 언어에 대한 문법을 갖고 있는 것은 아니라는 것이다. ATN 은 단순히 그러한 문법이 정의되고 사용될 수 있는 기구에 지나지 않는 것이다. 또한 ATN 은 그 형태에 어떠한 기능을 포함시키느냐에 따라 촘스키 (Chomsky) 계층 중 다른 형태의 문법에 적용 가능하다. 예로써 기본적인 상태의 이동 (push) 만을 허용한다면 정규 (regular) 언어의 형태에 사용될 수 있고, 여기에서 빠지는 pop 기능을 갖춘다면 문맥자유 (context free) 언어에 사용할 수 있고, 사용되는 레지스터의 크기에 제한을 가하면 문맥의존 (context - sensitive) 언어에 사용할 수 있으며, 이러한 레지스터에 아무런 제한도 가하지 않으면 순환적 열거 가능 (recursively enumerable) 한 언어에 사용 가능하게 된다. 비결정적인 (nondeterministic) 문법을 처리하기 위하여 대부분의 ATN 은 다음의 세 가지를 허용하게 된다.
ATN 은 다양한 형태의 언어이해 시스템에 유용하지만, 다음과 같은 결점이 있다.
그러나, 이러한 단점에도 불구하고 ATN 은 상당히 유용한 것이다. 실제로, 이는 여지껏 개발된 것 중 가장 성공적인 파싱 방법일 것이다. LUNAR [Woo 73] 에서 달에 대한 지질학적 정보에 대한 대규모의 데이터베이스를 추출하는 데 사용된 이래, 이 방법은 많은 언어이해 시스템에서 사용되어 왔다.
이상, 문장의 문장론적 (syntactic) 분석을 하기 위한 몇 가지 기법에 대하여 살펴 보았는데, 이보다 자세한 논의는 [Win 83] 을 참조하기로 한다.
(2) 케이스 문법 (case grammar) : 이는 파서 (parser) 가 어느 정도의 어의론적 정보를 지니게 된다.
(3) 문장론적으로 생성된 파싱 결과에 어의론적 구분을 하는 방법, 이는 다음의 두 가지 방법이 있다.
(4) 파싱에 중점을 덜 주고, 이해하는 과정을 문장론적 지식보다는 어의론적 지식으로써 행하는 방법.
어의론적 문법은 일종의 문맥자유 (context-free) 문법으로서, 비종단 (nonterminal) 과 생성규칙의 선택은, 문장론적 지식과 함께 어의론적 지식이 사용된다. 어의론적 문법을 사용한 초기의 예는 [Bur 76] 에서 찾아 볼 수 있는데, 이 경우는 지능적인 컴퓨터 보조 학습기인 SOPHIE 에서 사용자와의 인터페이스 (interface) 를 제공하기 위해 사용되었다. 참고로, SOPHIE 는 전자회로의 고장 진단법을 교육시키는 프로그램이다. 대규모 어의론적 문법은 LADDER 시스템 [Ben 78] [Sac 77] 에서 큰 데이터베이스를 검색하는 자연언어를 위해 사용되었다. LADDER 에서의 언어 처리 부분은 LIFER [Hen 77b] [Hen 77c] [Hen 77d] 라는 패키지 (package) 로써 개발되었는데, 이는 다용도를 위한 실용적인 자연언어 처리를 위하여 사용된다.
|
S → what is SHIP-PROPERTY of SHIP ? |
그림 11 어의론적 문법
그림 11 에 어의론적 문법의 예가 주어져 있다.
LADDER 에서 해군 선박과 이들의 특성에 관한 정보를 갖고 있는 데이터베이스에 대한 인터페이스를 정의하기 위하여 사용된 것을
축소시킨 것이다.
이 문법의 경우, NP 나 VP 등과 같은 문장론적
비종단 (nonterminal) 을 사용하기 보다는, SHIP 과 LOC 같은 어의론적 요소를 사용하고
있음을 주지해야 한다.
어의론적 문법은 문장론적 문법이 사용되는 방법과 동일하게 파싱 (parsing) 에서 사용된다. 어의론적 문법을 사용하는 여러 시스템은 ATN 을 이용하여 구성되는데, 이는 ATN 을 이용하여 여러 변화를 얻을 수 있기 때문이다.
어의론적 문법의 주요 이점은 다음과 같다.
"What is the closest ship to the Biddle with a doctor aboard?"
라는 문장을 생각해 보자. 순수한 문장론적 파싱의 경우에는 전치사구 'with a docotor aboard' 가 ship 에 대한 것인지 혹은 the Biddle 에 대한 것인지가 명확하지 않게 된다. 그러나 어의론적 문법의 경우에는, 이러한 묘사가 ship 에만 허용되도록 할 수 있을 것이다.
그러나, 어의론적 문법의 경우에도 다음과 같은 결함이 있다.
What is the longest book you've ever finished reading?
Who taught the hardest course you've ever finished taking?
여기서, 두 문장의 형용사의 최상급 형태를 포함한 문장론적 구조는 유사하지만, 관계절 (relative clause) 어의론적 기능은 서로 다르다. 이는 순수한 어의론적 문법에서는, 최상급을 포함하는 문장론적 법칙은 각 어의론적 기능에 따라서 두 번 주어져야 한다는 것을 의미한다.
어의론적 문법은 제한된 자연언어 처리를 빠르게 할 때에는 상당히 유용하지만, 언어학적 일반성이 결여된 관계로 언어 이해에 관한 전반적인 해로써는 부적합하다.
케이스 문법 [Fil 68] [Bru 75] 은 문장론적인 해석과 어의론적인 해석을 합친 또 하나의 방식이다. 문법의 규칙을은 어의론적인 것보다는 문장론적인 성격들을 나타내지만, 결과로 얻어지는 구조는 엄밀한 문장론적인 것보다는 어의론적인 관계에 해당된다. 예로써, 두 문장과 이들이 간소화된 전형적인 파스 트리 (parse tree) 가 있는 그림 12 를 생각해 보자.
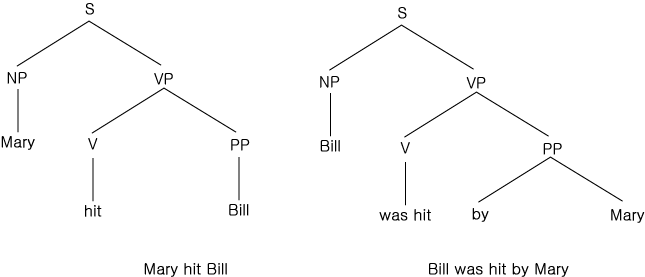
그림 12 능동태와 수동태의 문장론적 분석 (parse)
이 두 문장에서 Mary 와 Bill 의 어의론적 역할은 같지만, 이들의 문장론적 역할은 반대이다. 이들은 각각 한 문장에서는 주어이고 다른 문장에서는 목적어가 된다. 케이스 문법을 사용했을 때는, 두 문장의 해석 결과는 동일하게 다음과 같이 나타난다.
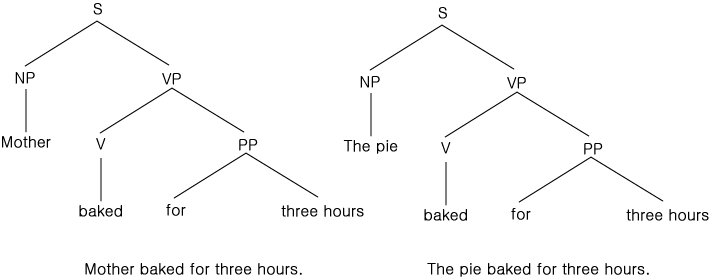
그림 13 비슷한 두 문장의 문장론적 파싱 결과(parse)
(hit (Agent Mary)
(Dative
Bill))
이제 그림 13에 있는 두 문장을 생각해 보자.
이 두 문장의 문장론적 구조는 서로 비슷하다. mother 와 baked 의 관계는 pie 와 baked 의 관계와는 아주 다른다. 이 두 문장에 대한 케이스 문법에 의한 해석은 이러한 상이점을 나타내어 준다. 첫 문장은 다음과 같이 해석될 것이다.
(backed (Agent Mother)
(Time-period
three-hours))
반면에 두번째 문장은 다음과 같이 해석된다.
(baked (Object the pie)
(Time-period
three-hours))
이러한 표현들에서는 mother 와 the pie 의 어의론적 역할이 명백히 표현되었다. 이러한 어의론적 정보가 언어의 문장론에 내포되어 있다는 것은 흥미로운 일이다. 두 병행한 문장을 하나로 묶는 것이 허용될 때는 (즉, "the pie baked" 와 "the cake baked" 는 "the pie and the cake baked" 로 묶여진다), 두 명사구가 동사에 대하여 같은 케이스 (격 ; 格) 관계를 가질 때에만 가능하다. 따라서 "Mother and the pie baked" 로 묶을 수는 없는 것이다.
케이스 문법에서의 각 케이스는 동사와 이의 인수 (argument) 들 간의 관계를 묘사한다. 영어에서는 케이스가 주격, 목적격 등과 같은 격을 나타내어, 각 격에 따라 문법적 표기 (예로써 주격 I 와 목적격 me) 가 달라지는데 이러한 것을 표면 케이스 (surface case) 로써 깊은 케이스 (deep case) 라고 한다.
현재까지 어떤 것들을 깊은 케이스로 할 것인지가 명확히 정의되어 있지는 않으나, 다음 것들은 비교적 자주 사용되는 것들이다.
|
A |
: |
Agent - (전형적으로는 움직이는 것으로) 행동을 일으키게 하는 것. |
|
I |
: |
Instrument - (대체로 부동적인 것) 어떤 사건을 일으키는데 사용된 사건이나 물체. |
|
D |
: |
Dative - (대체로 움직이는 것) 행동에 의하여 영향 받는 개체 (entity). |
|
F |
: |
Factitive - 사건의 결과로써 물체나 존재 (being). |
|
L |
: |
Locative - 사건의 장소. |
|
S |
: |
Source - 무엇인가가 움직이기 시작한 곳. |
|
G |
: |
Goal - 무엇인가가 움직여 가는 곳. |
|
B |
: |
Beneficiary - (대체로 살아 있는 것) 그를 위해 사건이 생겨난 존재. |
|
T |
: |
Time - 사건이 일어난 시각. |
|
O |
: |
Object - 행동이 가해진, 혹은 변화된 개체 (entity) 로서 가장 일반적인 케이스 |
케이스 표현으로의 파싱 과정은 주로 각 동사와 관련된 사전의 내용에 따라 이루어진다. 그림 14 는 이러한 내용의 예이다. 괄호에 놓인 것은 경우에 따라 주어질 수 있는 것이다.
|
open |
[ _ _ O (I) (A)
] |
|
die |
[ _ _ D] |
|
kill |
[ _ _ D (I) (A)
] |
|
run |
[ _ _ A ] |
|
want |
[ _ _ A O ] |
그림 14 몇 가지 동사에 대한 케이스 골격
케이스 문법을 이용한 어원 분석은 예상에 따라 처리되는 예상 구동 (expectation-driven) 형태를 취한다. 문장에서의 동사의 위치가 정해지면, 이를 이용하여 명사구의 위치를 추정하고, 또 이들을 이용하여 문장의 나머지 부분과의 관계를 정하게 된다.
ATN 은 케이스 문법을 사용하는 경우의 파싱에 유용한 구조가 된다. 전통적인 어원 분석 방법에서는 문법규칙의 구조가 출력 구조로 그대로 반영이 되지만, ATN 에서는 출력 구조가 임의의 형태를 취한다. 이의 이용에 대한 예로써 [Sim 73] 을 보면, 이 시스템에서는 영어 문장으로 하여금 문장의 케이스 구조를 나타내는 의미회로 (semantic net) 로 변환시키기 위해 ATN 파서 (parser) 를 사용하였다. 이 의미회로는 문장에 대한 여러 가지 질문에 답하기 위하여 사용하였다.
주어진 문장을 개념의존 (이하 CD 로 약함) 표현으로 파싱 (parsing) 하는 것은 케이스 문법으로 파싱하는 과정과 유사하다. 두 경우 모두 문장의 주동사에 근거를 둔 일련의 예측에 의하여 처리된다. 그러나 CD 에서의 동사 표현은 케이스 문법에서의 동사 표현 (이 경우는 사용되는 표현이 영어 단어와 동일) 보다 훨씬 더 세분되어 있으므로, CD 의 경우는 보다 예측할 수 있는 정도가 크다. 주어진 문장을 CD 표현에 대응시키는 첫단계에서는 문장의 주어와 동사를 추출하는 문장론적 처리가 이루어진다. 이 때 동사의 문장론적 범주 (사역동사인가 자동사인가, 타동사인가 등) 를 결정한다. 이후에 CD 처리가 이루어진다. CD 처리시에는 Verb-ACT 사전을 이용하게 되는데, 동사가 나타날 수 있는 각 경우에 따라 사전의 내용은 구분되어 진다. 그림 15 는 동사 WANT 와 관련된 사전의 내용이다. 그림에서 세 가지의 구분은 다음의 세 종류의 wanting 에 해당한다.
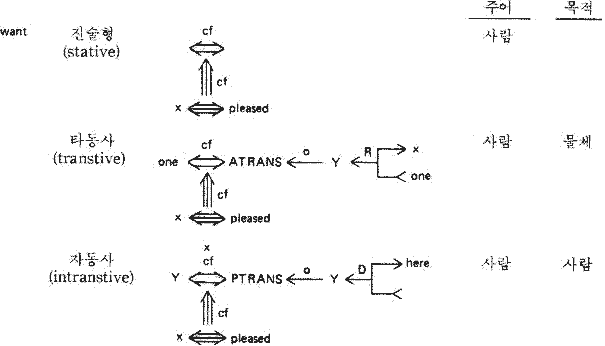
그림 15 Verb-Act 사전
일단 올바른 구분이 얻어지면, 동사 구조의 빈 곳을 채울수 있는 요소를 찾기 위하여 문장의 나머지 부분을 분석한다. 예로써 주어진 문장에서 want 가 목적어가 목적보어를 갖는 진술형 (stative) 이라고 밝혀졌다면, 이 진술형 구조를 이용하여 나머지 부분들을 완성시키게 된다. 따라서 만일 처리되는 문장이 다음과 같다면,
John wanted Mary to go to store.
그림 16 과 같은 구조를 얻게 된다 (여기서 이 동사의 구조는 세번째의 자동사 (intransitive) 가 아님을 유의하라. 자동사이기 위해서는 원하는 이가 주어가 있는 곳, 즉 here 로 와야 한다).
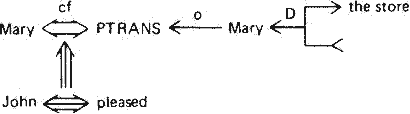
그림 16 CD 구조
CD 로 처리되는 경우는 주어진 문장에 대한 가능한 여러가지 해석을 잘 정리된 순서로 검토한다. 예로써 "with PP" (PP 는 picture producer 즉, 보이는 것) 형태의 구가 있다면, 이는 다음과 같이 PP 와 이것이 부분이 되어 형성되는 개념화 구조 간의 여러 관계중의 하나가 될 수 있다.
(1) 도구인 경우의 물체
(2) 주요 ACT 의 보조적인 행위자 (actor)
(3) 문장에서 with 바로 앞에 놓인 것에 대한 PP 의 성격
(4) 개념화 구조에서 행위자 (actor) 의 성격
다음의 문장을 해석하는 경우를 생각해 보자.
John went to the park with the girl.
우선, 시스템은 이전에 'park with the girl' 이 언급되었었는가를 검토하고 그러한 경우에는 언급되었던 특별한 대상에 연관을 시켜 놓고 일을 끝낸다. 그러나 그렇지 않은 경우에는, 앞의 네 가지 가능성에 대하여 이들이 놓인 순서대로 검토된다.
첫째 가능성을 생각해 보자. 우선 이 문장에서 went 는 CD 에 의하여 개념화되면 PTRANS 가 된다. 이것이 문장의 주요 ACT 인데, PTRANS 의 도구가 될 수 있는 것은 MOVE 나 PROPEL 이고 이들의 대상은 신체 일부이거나 이동할 수 있는 기구이어야 한다. 따라서 'the girl' 이 문장의 주요 ACT 의 도구는 아님을 알 수 있다. 따라서 두번째 가능성을 검토한다. girl 이 주요 ACT 에 대한 보조적인 행위자 (actor) 이기 위해서는, girl 은 살아 있는 것이어야 되는데, 이는 맞다. 따라서 두번째 해석이 선택되고, 이 과정은 끝나게 된다. 그러나 만일 주어진 문장이
John went to the park with the fountain.
이었다면, fountain 이 살아 있는 것이 아니며 움직일 수 없는 것이므로, 세번째 가능성이 검토된다. Park 는 fountain 을 가질 수 있으므로, 이 문장은 받아들여지고, 여기서 처리는 끝나게 된다. 이러한 CD 에 관계된 보다 상세한 내용은 [Sch 73] [ Rie 75a] [Rie 75b] 를 참조하기 바란다.
여기서 제시된 예는 문장 이해를 위한 CD 방식의 장·단점을 알려 주고 있다. 이해과정에서는 많은 의미론적 정보가 사용되므로, 순수한 문장론적 방식으로는 파싱하기가 애매한 문장들도 이러한 방식에서는 특정된 해석을 부여할 수 있게 된다. 그러나 불행히도, 이러한 작업을 완전하게 하기 위해 요구되는 의미론적 정보의 양은 방대하게 된다. 어떤 간단한 법칙이라도 예외는 있기 마련이다. 예로써, 앞에서 묘사된 CD 방식에 다음의 문장이 주어졌다고 생각해 보자.
John went to the park with the peacocks.
여기서 peacock 은 살아 있는 것이므로, 주동사 went 의 보조적인 행위자 (actor) 로 받아들여진다. 따라서 얻어진 해석은 그림 17 (a) 와 같은 것이 될 것이나, 실제로 옳은 해석은, John 이 peacock 이 있는 park 에 갔으므로 그림 17 (b) 와 같은 형태이어야 할 것이다. 그러나 만일 with 로 되는 전치사구의 해석 순서를 이 문장이 제대로 해석되게하기 위하여 순서를 바꾼다면, 앞서의 예인 'with Mary' 는 잘못 이해될 것이다.
문제는, 동물 (ANIMATE) 이란 성격이 PTRANS 의 보조적인 행위자 (actor) 의 받아들이는 여부를 결정하기에는 충분하지 못하다는 것이다. 이를 위하여서는 지식이 더욱 첨부되어야 할 것이다. 문장에 대한 올바른 의미론적 해석을 얻기 위해서는, 문장이 나타내는 내용에 대한 많은 지식이 필요하게 된다. 이러한 지식을 개발하는 기술에 대한 것은 다음 절에서 논의될 것이다.
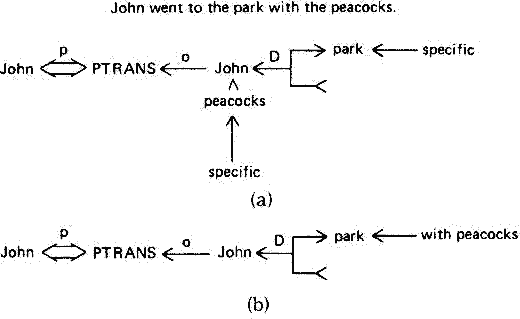
그림 17 한 문장에 대한 두 가지 CD 표현
CD 를 이용한 자연언어 시스템 중에 많은 것은 앞서 논의한 문장론적 처리와 어의론적 처리를 합치는 방법 중 네번째에 속하는 것이 많다. CD 에 의한 경우, 어의론적 차원에서 제공되는 예측력 때문에 문장론적 처리는 덜 강조된다.
하나의 문장을 이해하는 문제에서는 보통 각각의 단어에 의미를 부여하고 전체 문장에 적합한 표현 구조를 배정하게 된다. 그러나 여러 복합 문장을 이해하는 경우, 문헌의 일부나 대화의 일부건 간에, 문장들 간의 관계도 규명되어야 한다. 문장들 간의 관계로 중요한 것들은 다음과 같은 것들이 있다.
이러한 여러 관계를 인식하기 위해서는 대화의 주제나 배경이 되는 것에 대한 방대한 지식이 필요하다. 따라서 복합 문장들을 이해하기 위한 프로그램은 방대한 지식을 저장할 데이터베이스가 필요하며, 이러한 지식이 어떻게 구성되어 있느냐가 이해하는 프로그램의 성공 여부를 결정하게 된다. 이 절의 나머지 부분은 이전에 논의한 지식표현방식들이 언어 이해 프로그램에서 어떻게 이용될 수 있는가에 대해 생각하여 보기로 한다.
이해하기 위하여 지식을 이용하는 과정에는 두 가지 중요한 부분이 있다.
데이터베이스 내의 관계된 지식을 저장한 부분에 초점을 맞춘다.
이 지식을 이용하여 언급되는 것들간에 애매한 것을 해결하며 또 연관을 지어준다.
두 가지 중 첫번째 것은 허용되는 지식이 방대한 경우에는 특히 중요하다. 이를 위한 몇 가지 기본적인 기법을 제 6-1-3 절에서 언급하였으나, 여기서는 그러한 일반적인 기법을 특정한 지식구조에 대해 보다 세분화시켜서 생각해 보자. 이해 과정에서 초점을 맞추는 필요성을 생각해 보기 위해, 다음의 간단한 문장들을 생각해 보자.
Next, attach the pump too the platform.
The
bolts are in a small plastic bag.
(이를 국역하면 : 자, 이제 펌프를
지주대에 부착시키시오. 볼트들은 작은 플라스틱 봉지에 있읍니다.)
이 문장들을 이해하기 위해서는, 두번째 문장에서 인용되는 볼트는 펌프를 부착시키기 위하여 사용되는 것이라는 것을 인식하여야 한다. 이는 만일 첫째 문장을 이해할 때, 요구되는 볼트에 초점을 맞추었다면 쉽게 가능할 것이다. 이렇게 하기 위해서는, 부착 (attaching) 에 관한 지식을 표현함에 있어서, 부착이 거론될 때마다 볼트 등과 같은 관계된 개념을 쉽게 액세스 (access) 될 수 있어야 한다.
간단한 사물이나 사건은 의미회로 (semantic nets) 를 이용하면 쉽게 표현할 수 있다. 의미회로에서 양화사 (quantifier) 나 변수를 나타내기 위하여 분할 (partitioning) 하는 방법 (6 장 참조) 을 더욱 확장시켜 초점공간 (focus space) 이라는 표현 방법을 이루는데. 이는 초점이 함께 주어져야할 노느나 아크를 모아놓은 것이 된다 [Gro 77]. 이렇게 함으로써 하나 (예로써 ATTACHING) 가 찾아지면, 관계된 다른 것 (즉, 볼트) 도 빠르게 찾아질 수 있는 것이다. 그림 18 이 이러한 분할된 의미회로를 나타내고 있다.
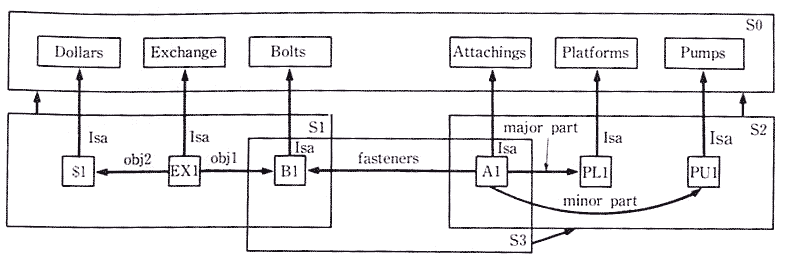
그림 18 초점을 보이는 분할된 의미회로
이 회로는 네 가지로 분할되어 있다.
(1) S0 는 달러 (dollar), 교환 (exchanges), 부착 (attachings) 등의 일반적 개념 (general concept) 을 포함한다.
(2) S1 은 특정한 볼트의 구매 (즉, 달러와의 교환) 에 관련된 특정한 개체 (entities) 를 포함한다.
(3) S2 는 펌프 (pump) 를 지주대 (platform) 에 부착 (attaching) 시키는 특정한 동작에 관여된 특정한 개체를 포함한다.
(4) S3 는 S2 처럼 부착시키는 동작에 관여된 특정한 개체를 포함하나, 이 경우는 부수적으로 좀 더 자세히, 즉 어떤 볼트가 관여되는지를 나타낸다.
초점공간은 그림에서 굵은 화살표로 보이는 것 같이, 다른 것들과는 종적 (hierarchically) 으로 관계된다. 하나의 초점공간에 집중되었을 때는, 이보다 종적으로 높은 차원에 있는 공간을 액세스할 수 있다. 초점공간에 의하여 하나의 물체가 여러 가지로 간주될 수 있음을 유의하여야 한다. 예로써 B1 은 구매 (purchase) 의 일부로써 혹은 조이는 작업 (fastening) 의 일부로써 간주될 수 있는 것이다.
이해 과정에서 초점공간을 사용하는 것은 두 단계에 의하여 이루어진 것이다.
앞서 두 문장의 예를 이용한다면, 우선 첫 문장이
이해되었을 때는 S2 가 초점이 될 것이다. S0 공간은 종적으로
S2 의 위에 있으므로 액세스할 수 있다. 두번째 문장의 이해를 위하여,
'the bolt' 가 이 두 공간의 요소들과 비교될 것이나, 일치하는 곳이 없다. 그러나
S3 가 초점을 받게 되면, B1 노드와 일치한다는 것을 알게되고,
따라서 두번째 문장에서 언급된 볼트는 첫문장에서 묘사된 부착에 사용되는 것이라는
것을 알게 된다. 이렇게 해서 두 문장은 서로 무관하지 않고 상호 연결되는 문장들임을
알 수 있다.
초점에 관한 더욱 상세한 내용은 [Sid 78] 을 참조하기로 한다.
불행히도, 사물이나 사건을 이해하는 것만으로는 사람과 이들의 행위를 다루는 이야기를 이해하기에는 불충분하다.
예로써 다음을 생각해 보자.
John was really in the mood for a glass of cold
beer.
He asked the man walking past him where the nearest bar was.
이 이야기를 이해하기 위하여, John 이 다음의 것들을 갖고 있었다는 것을 인식할 필요가 있다.
등장인물들의 목표들과 이 목표들을 이루기 위한 그들의 계획을 인식하는 것은, 이야기를 이해하는 데 중요한 부분이 된다. 몇 가지 보편적으로 사용되는 목표들로는 다음과 같은 것들이 있다.
인간은 이상과 같이 많은 목표를 세울 수 있고, 이러한 목표를 이루기 위하여 여러 가지 계획을 세운다. 또한 이미 구성되어 있는 계획을 지니고 있다가, 적당한 때에 이를 사용하기도 한다. 만일 이해하기 위한 프로그램이 이러한 계획들이 존재하고 있음을 알 수 있다면, 이 프로그램은 이야기 속에 생략된 부분들을 추론할 수 있는 것이다. 이러한 계획의 한 예가 그림 19 에 나타나 있다.
|
USE(x) = |
D-KNOW (LOC (x)) + |
그림 19 계획의 예 (USE 계획)
물체 X 를 어떤 목적으로 사용하기 위해서는, 물체의
위치 (LOC) 를 알아야 하는 부분 목표, 물체의 곁 (PROX) 으로 가야 하는 부분목표,
물체를 장악하는 (CONTROL) 부분목표, 이를 사용할 수 있도록 준비하는 (PREP) 부분목표,
그리고 원하는 일을 하는 (DO) 부분목표들을 순서적으로 만족시켜야 한다.
USE
계획에 저장되는 부분목표들 중에서 D-로 시작되는 세 가지는 자주 사용되므로 이들은
planbox 라고 불리우는 이미 저장된 계획들을 이용하여 이루도록 한다. 예로써, D-KNOW
를 이루기 위해서는 ASK 라는 계획이 제공된다. D-CONTROL (물체를 장악하는 것)
에 대한 목표를 만족시키기 위한 계획은, ASK-FOR (얻든지), BARGAIN-FAVOR (사든지),
STEAL (훔치든지), OVERPOWER (빼앗든지) 등을 포함한다.
하나의 planbox 는 계획에 관련된 전제조건 (precondition), 후미조건 (postcondition) 과 행위 (action) 를 묘사한다. 그림 20 은 ASK 에 대한 planbox 를 보이고 있다. 이는 아래의 정보를 포함하고 있다.
|
ASK |
|
|
ACT CP UP MP RES
|
X MTRANS Q? to Y X BE (PROX (Y)) Y knows Q Y wants to MTRANS Q to X Y MTRANS Q to X Q BE (MLOC (X)) |
그림 20 ASK 에 대한 planbox
|
─ |
수행할 행위 |
|
|
─ |
계획을 구성하는 측이 조성할 수 있는 전제조건 |
|
|
─ |
계획을 구성하는 측으로써 조성할 수 없는 전제조건으로서, 이것이 만족되지 않으면 계획은 포기되어야 함. |
|
|
─ |
이는 간접적인 전제조건으로, 계획을 구성하는 측이 다른 planbox 를 이용하여 만족시킬 수 있음. |
|
|
─ |
계획을 수행한 결과. |
이러한 계획을 이용하여 앞의 예에서의 경우, 시스템은
John 과 맥주의 관계를 이해할 수 있고, 따라서 '왜 John 이 술집의 위치를 묻는가'
에 대한 답변을 할 수 있는 것이며, USE (beer) 계획이 호출되어 이 계획의 첫단계인
맥주 (beer) 의 위치를 찾는 것이 행하여진다. 이러한 목표와 계획에 관한 연구는
이야기를 이해하는 프로그램인 PAM [Wil 78] [Wil 81] 에서 이루어졌다. PAM 의 업무처리의
예가 그림 21 에 나타나 있는데, 보여진 바와 같이 PAM 은 이야기를 듣고 물음에
답할 수가 있었다.
PAM 은 우선 영어를 CD 의 표현으로 파싱한 뒤에, CD 표현을
이용하여 입력에서 묘사된 사건에 대한 해석을 한 뒤, 이 해석을 이용하여 차후의
사건에 대한 가능한 해석을 예측하였다.
|
Story |
|
John wanted Bill's bicycle. |
|
Question |
|
Why did Bill give his bicycle to John? |
|
Answer |
|
Because he didn't want to get hurt. |
그림 21 PAM 의 처리에 대한 예
USE 와 같이 일반목적으로 사용될 수 있는 계획 외에도, 인간은 특수한 상황에서 보편적으로 일어나는 양식 (pattern) 에 대한 묘사들을 매우 상세하게 저장하고 있다. 예로써, 식당에서 식사하기 위한 경우라든지, 여행할 때에는 일반적으로 적용되는 양식이 있는데, 이러한 것에 대해서는 제 6 장에서 이미 논하였다. 특별히 스크립트 (scripts) 는 자연언어를 이해하기 위하여 광범위하게 사용되고 있다. 이전에 논의한 바와 같이 스크립트는 일련의 사건들에 대한 묘사를 기록한 것인데, 어떤 상황에 대하여 planbox 보다 더 특수한 정보를 저장함으로써 보다 많은 추론을 가능하게 한다.
우리가 논의한 다른 여러 메모리 구조들처럼, 스크립트를 이용하여 언어를 이해하는 과정도 두 단계로 구성된다.
이러한 두 단계에 대해서는 이미 6 장에서 논의하였다. SAM [Sul 81] 은 스크립트를 이용한 이해 프로그램인데, PAM 과 같이, 먼저 영어 문장을 CD 표현으로 변화시키고, 관계된 스크립트를 이용하여 전체 내용에 대한 표현을 얻는다.
사람을 위한 일을 하기 위하여, 컴퓨터 프로그램은 사람이 원하는 것이 무엇인지를 우선 알아야 한다. 언어 대화는 사람이 이러한 정보를 전달하기 위한 아주 편한 방법이다. 따라서 컴퓨터에 의한 자연언어 이해의 응용 중에 중요한 것은 컴퓨터와 이의 사용자 간의 대화를 이루는 것이라 하겠다. 그러나 여러 이유에 의해 대화를 이해하는 것은 지극히 힘든 일이다. 그림 22 는 GUS[Bob 77]라는 여행 안내 시스템에서, GUS 와 사용자와의 대화 내용을 발췌한 것이다.
|
GUS
: Hello. My name is GUS. I can help you plan a simple trip by air. |
|
(1)
Client : I want to go to San Diego on May 28 (2)
Client : I must be in San Diego before 10 am (3)
Client : What is the next flight? (4)
Client : I'll take the first one (5)
Client : Dan Bobrow May 28 from San Jose to San Diego that leaves at 7.30 am and arrives at 9.15 am. What date do you want to return on? (6)
Client : On Friday in the evening. (7)
Client : That's fine. from San Diego to San Jose that leaves at 7.45 pm and arrives at 9.30 pm. Thank you for calling. Goodbye. |
그림 22 GUS 의 대화
이는 다음과 같은 문제점들을 설명하여 주는데, 효율적인 대화 이해를 위해서는 이러한 문제점들이 해결되어야 한다.
이러한 어려움에도 불구하고, 대화를 이해하기 위해서는 다음을 포함한 제공되는 모든 정보를 이용하는 것이 중요하다.
[Jos 81]는 이러한 대화의 이해에 관한 여러 이론적인 면과 계산적인 면에서 고찰한 것이다. 이미 우리는 이러한 네 가지 중, 앞에서 두 가지의 내용을 다루었다. 이는 문장의 경우에서와 공통으로 유용하기 때문이다. 나머지 두 가지 내용은 대화의 이해를 위하여 중요하기에 여기서 논의하기로 한다.
프로그램이 지능적으로 대화에 참여하기 위해서는, 프로그램이 세상에 관한 자기의 의견을 표현할 수 있는 것은 물론, 세상에 관한 지식을 표현할 수 있어야 되며, 더 나아가 프로그램의 생각에 대한 다른 사람의 생각 등도 표현할 수 있어야 한다. 조금 과장한다면 '네가 알고 있는 것을 내가 안다는 것을 또한 네가 알고, 그러한 사실을 내가 안다는 것을 다시 네가 아는 것' 인데, 이러한 사고력이 항상 필요한 것이다.
각 대화 참여자 (혹은 이야기에서 각 등장인물) 에 대한 개개의 생각을 표현하기 위해서는, 다음의 내용이 필요하다.
(1) 모든 참여자가 같이 생각하는 많은 것을 효율적으로
나타낼 것.
(2) 각자가 별개로 생각하는 보다 작은 것을 정확하게 나타낼
것.
(1) 의 경우는 하나의 데이터베이스로써 모든 참여자의 생각을 나타내게 되지만, (2) 의 경우는, 한 사람이 생각하는 것을 다른 사람이 것들과 구분하여야 한다. 이를 위한 방법중의 하나는 분할된 의미회로 (semantic nets) 를 사용하는 것인데, 이는 이미 6 장에서 다룬바 있다. 그림 23 은 분할된 공간 (space) 을 이용한 것이다. 여기서는 세 가지 다른 공간이 존재한다.

그림 23 세 개의 믿음 공간 (belief spaces) 을 보여주는 분할된 의미회로 (semantic net)
대화의 경우에는 기본적으로 존재하는 규칙들이 있다. 이들은 보통 많은 경우에 잘 적용되나, 적용되지 않는 경우에는 위반되는 것 자체가 무엇인가를 의미하게 된다. 이러한 대화의 가정에 대한 규칙들 중 몇 가지는 다음과 같다.
이러한 대화의 가정에 대해서는 [Gri 75] 나, [Gor 75] 를 참조하기 바란다.
언어 생성 과정은 언어 이해의 반대로써
생각하면 된다. 정보를 나타내는 구조를 원하는 언어로 된 올바른 스트링 (string)
으로
대응시켜야 한다. 그러나 경우에 따라서는 전달할 정보가 어디로부터 얻어지는가를
생각하는 것도 중요한 문제이다.
언어 생성에 대한
전체 과정은 다음과 같이 세 부분으로 나뉘어 질 수 있다.
(1) 전달할 정보를 나타내는 구조의 구성 : 이것은
무엇을 말할 것인가를 결정하는 것이다.
(2) 문장의 순서를 정하기 위한 대화
구조 및 문장에 대한 규칙을 적용한다.
(3) 실제 문장을 생성하기 위하여,
단어에 대한 정보 및 문장론적 규칙을 적용한다.
이들 중 처음 (1) 은 가장 어려운
문제이고, 이는 또 언어학적 문제와는 거리가 멀다. 경우에 따라서는 대화할 정보가
질의응답 시스템에서는 질의에 대하여 산출되기도 한다. 이러한 시스템에서는 정보
생성 과정이 질문에 대하여 제한 받기도 한다.
나머지 두 부분은
대화할 내용이 정하여 졌다고 가정하고서 대화를 효율적으로 하는 문제를 강조하게
된다. 문장이나 대화의 구조를 생각함에 있어서, 얼핏 생각하기에는 언어 생성이
언어 이해보다는 쉬울 것처럼 보인다. 왜냐하면 후자를 위해서는 입력을 주는 사람에
의하여 구성되는 모든 대화 범위를 프로그램이 이해할 수 있어야 하나 전자의 경우에는
프로그램이 보다 작은 구조를 이용하여 여러 가지를 하나로 나타낼 수 있기 때문이다.
그러나, 이렇듯 최소한의 언어학적 지식을 사용하면 극히 한정된 형태의 문장을 생성하게
되고, 대답에 대한 부담은 단순히 생성자에게서부터 이해자로 넘겨지는 것에 지나지
않는 것이다. 좋은 문장을 생성하기 위해서는 언어 이해에서 생기는 모든 문제가
해결되어야 한다 :
예로써, 언어 이해에서의 어려움 중의 하나가
대용어라고 말했다. 좋은 문장을 생성하기 위해서는 적당한 대용어를 생성하는 문제가
해결되어야 할 것이다. 다음의 짧은 문장을 생각해 보자.
John saw a bicycle in a store window. John wanted the bicycle.
이처럼 짧은 문장에서조차, 대명사의 사용이 없다면 아주 부자연스럽게 된다. 이미 언급된 사물을 가리키는 대명사를 사용함으로써, 보다 자연스러운 문장을 얻을 수 있다.
John saw a bicycle in a store window. He wanted it.
그러나 이 간단한 방법도 항상 유용한 것은 아닌데, 대명사는 명백히 해석될 수 있다고 생각될 때만 사용할 수 있기 때문이다. 예로써 원래 문장이 다음과 같이 주어졌다면,
John saw a blue ball in a shiny red wagon.
John
wanted the blue ball.
앞서와 같이 단순한 대명사로 대치시키면,
John saw a blue ball in a shiny red wagon.
He
wanted it.
과 같지만, 여기서는 it 은 애매하게 된다. 이는 ball을 의미할 수도 있고, wagon 을 의미할 수도 있기 때문이다. 이러한 문제는 앞의 문장에서는 생기지 않았는데, 이는 John이 store window 를 원하지는 않을 것이기 때문이다. 두 번째 경우에는 언어 생성 프로그램을 다음과 같이 하여야 할 것이다.
John saw a blue ball in a shiny red wagon.
He
wanted the ball.
복합 문장의 생성에 관한 여러 문제를
다룬 시스템들이 개발되었는데, 이 중에서 KDS [Man 81A][Man 81 b] 는 조각 구성(fragment
and compose) 방법을 사용하여, 대화할 정보를 아주 작은 단위 (보통은 절에 해당)
로
쪼갠 후 이를 다시 적당히 읽을 만한 문장으로 재구성시켰다.
문장
생성의 세 가지 부분 중 마지막은 주어진 지식 표현으로부터 문법에 맞는 언어를
생성하는 것이다. 이를 위한 한 가지 방법은 언어인식기법을 역으로 적용시키는 것이다.
예로써, 영어 문장을 인식하기 위해서는, ATN 을 사용할 수도 있다. ATN 을 문장생성에
사용하기 위해서는, 아크의 조건으로 지식구조를 첨부하고 문장 구성을 위한 규칙을
써나가면 된다. 이를 이용한 질의응답 시스템이 [Sim 72] 에 주어져 있다.
다른
문장론적 문장 생성에 관한 논의는 [Gol 75] 과 [Bat 81] 을 참조하기 바란다.
컴퓨터의 최초의 비수치 (non-numeric) 응용 중의 하나는 기계 번역이었다. 이러한 번역 프로그램의 모델이 그림 24 에 주어져 있다.
|
원시언어 |
→ |
대상언어 |
그림 24 구식 기계 번역 프로그램
원시언어 (source language) 의 문장은 대상언어 (target language) 의 문장으로 직접 대응되는데, 이는 원시언어-대상언어사전을 이용하며, 또 두 언어의 아주 간단한 문법구조의 모델을 이용하여 이루어진다. 이런 방식의 번역에 관해서는 [Boo 67] 를 참조하기 바란다. 불행히도, 이 방법은 성공적이 못되었다. 한 문장을 어떤 언어에서 다른 언어로 번역하기 위해서는 먼저 문장의 의미를 이해하여야 하는데, 이를 소홀히 하는 시스템의 경우에는 다음과 같은 단점을 같게 될 것이다.
1. The
spirit is willing but the flesh is weak.
(정신은 강하고 육체는 약하다.)
2. The
vodka is good but the meat is rotten.
(보드카 [술의 종류] 는 좋지만 고기는
상하였다.)
이미 우리가 생각한 바와 같이 이를 해결하기 위해서는 원시언어의 문장을 이해하고, 이를 대상언어로 나타내어야 하는 것이다. 이러한 방식이 그림 25 에 나타나 있다.
|
원시언어 |
→ |
의미론적 표현 |
→ |
대상언어 |
그림 25 신형 기계 번역 프로그램
현재 기계 번역은 이러한 방식에 의한 연구가 대부분이다. 이 방식에 대한 보다 자세한 논의는 [Wil73] [Cul 81] [Car 81] 들을 참조하기 바란다.