언어 이해
인지 심리학과 그 응용 : John R. Anderson 저서, 이영애 옮김, 이화여자대학교출판부, 2000 (원서 : Cognitive Psychology and Its Implication (4th ed), 1995), Page 383~418
공상 과학이 즐겨 다루는 대상은, 「2001년」에서의 HAL 과 같이 사악하든, 또는 「별들의 전쟁」에서 C3PO 처럼 쓸모 있든, 언어를 이해하고 말할 수 있는 컴퓨터나 로봇이다. 인공 지능 연구자들은 언어를 이해하고 생성할 수 잇는 컴퓨터를 개발하려고 노력해 왔다. 약간의 진전이 이루어지고 있지만, 현재의 언어 연구에서 나온 명백한 사실에 비추어, 언어를 실제로 처리할 수 있는 기계가 발병되면 그것은 기념비적 업적이 될 것이다. 언어는 방대한 양의 지식과 지능을 기초로 성공적으로 사용된다. 이 장에서는 언어 사용, 특히 언어 이해 (언어 생성과 구분되는) 를 볼 것이다. 언어 이해에 초점을 두는 이유는 언어 이해가 언어 생성보다 더 많이 알려져 있기 때문이다.
언어 이해를 논의할 때 이해는 듣기와 읽기 모두에 포함되는 것으로 다루겠다. 이 둘 중에서 듣기 과정이 더 기본적이다. 그러나, 같은 요인들이 듣기와 읽기 모두에 포함된다. 말과 문자 재료 중 어느 것을 쓸 것인지에 관한 연구자의 선택은 실험적 유연성에 따라 정해진다. 이것은 주로 읽기 연구를 뜻했다.
이해는 다음의 세 단계로 분석될 수 있다. 첫 단계는 지각
(perception) 과정인데 음운 또는 문자 메시지가 처음
약호화된다. 둘째 단계는 구조 분석 (parsing) 단계이다. 구조
분석은 메시지 속에 단어들이 의미로 조합되어 심적 표상으로
바뀌는 단계이다. 셋째 단계는 활용 (utilization) 단계로서,
이해자들은 실제로 심적 표상을 써서 문장을 뜻을 이해한다.
만일 문장이 주장이면 청자는 그 의미를 기억에 저장하며,
그것이 질문이면 답을 하고, 그것이 지시이면 따라야 한다.
그러나, 청자들이 항상 그렇게 고분고분하지는 않다. 그들은
화자의 성격을 추론하기 위하여 기후에 관한 주장을 내세울 수
있고, 질문에는 질문으로 답할 수 있으며, 화자의 요구에
무작정 반대로 대응할 수도 있다. 지각, 구조 분석 및 활용의
세 단계는 필요에 의해 시간적 순서로 나열되지만, 그러나
부분적으로 중복되기도 한다. 청자는 문장의 끝부분을
지각하는 동안 문장의 첫 부분으로부터 추론을 할 수 있다. 이
장은 구조 분석과 활용의 두 고급 과정에 초점을 두겠다. 지각
단계는 이미 2 장에서 논의되었다.
| 이해는 지각 단계, 구조 분석 단계, 그리고 뒤따르는 활용 단계를 포함한다. |
언어는 어떤 단어들의 나열로부터 그 의미를 해석하는 방법을 말해 주는 규칙 세트로 구성된다. 예를 들면, 영어에서 명사, 동사, 명사 형태의 문장을 들으면, 화자는 첫 명사의 예가 둘째 명사의 예를 설명하는 관계 (동사) 에 있음을 뜻한다. 대조적으로, 문장이 명사, was, 동사의 과거 분사, by, 명사의 형태이면, 화자는 둘째 명사의 예가 첫째 명사의 예로 기술되는 관계에 있음을 뜻한다. 이와 같이, 영어 구조에 관한 지식 때문에 A doctor shot a lawyer (의사가 변호사를 저격했다) 와 A doctor was shot by a lawyer (의사가 변호사에 의해 저격 당했다) 간의 차이를 알 수 있다.
언어 이해를 배우는 과정에서, 사람들은 다양한 언어 패턴을 약호화하고 이 패턴을 의미와 관련시키는 많은 규칙들을 획득한다. 그러나, 모든 문장 형태에 걸 맞는 각각의 규칙을 학습하기란 불가능하다. 문장들이 매우 길고 복잡할 수 있다. 모든 가능한 문장 형태를 약호화하려면 수많은 (아마도 무한한) 패턴이 요구된다.
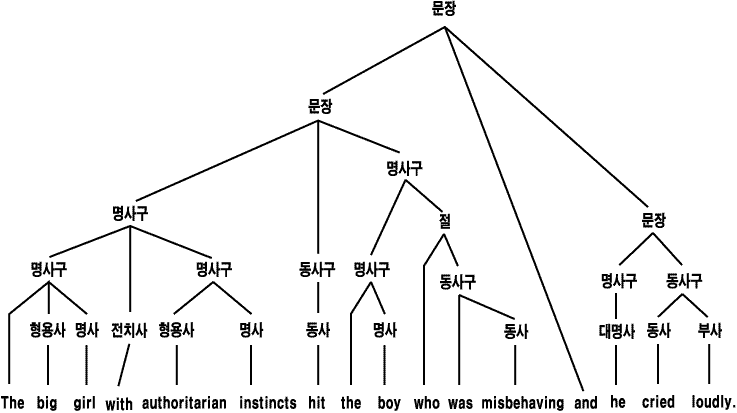
언어 이해를 배우면서 가능하고 완전한 모든 문장 형태를 해석하는 것은 배우지 않았지만, 이런 문장들의 하위 패턴이나 구를 해석하고, 그리고 이 하위 패턴을 조합하거나 연결시키는 것을 배웠다. 그림 12.1 은 앞 장에서 나온 예문의 구 구조를 보여 준다. 이 수준의 구 구조와 일치하여, 두 문장의 의미를 조합시키는 해석 규칙이 있다. 한 문장은 타동형 명사구, 동사구, 명사구 구조로, 그리고 다른 문장은 자동형 명사구, 동사구 구조로 해석되므로, 사람들은 이 패턴 각각을 어떻게 해석하는지 안다. NP (명사구) 와 VP (동사구) 는 몇몇의 다른 패턴으로 해석된다. 한 경우, 명사구 (the big girl with authoritarian instincts) 는 그 해석의 일부로 내포된 명사구 (authoritarian instincts) 를 가지고 있다.
이 하위 패턴들은 문장 구조 내에서 기본 구 또는 단위와 일치한다. 이 단위들은 구성 성분 (constituents) 이라고 불린다. 앞 장의 언어 생성 부분에서 이러한 구조의 심리적 실재에 관한 증거를 논의했다. 이해 과정에서도 이 구성 성분이 심리적 실재를 갖고 있음을 다음에서 보겠다.
그림 1 문장 패턴의 연결을 보여 주는 구 구조 표상.
| 사람들은 다양한 구의 의미를 이해하고 이들의 의미를 연결시켜 완전한 문장의 의미로 표상함으로써 언어를 이해한다. |
앞 절에서는 문장이 구성 성분 패턴의 연결로 이루어진다고
주장했다. 문장에서 구성 성분 구조가 더 분명히 파악될수록,
그 문장이 더 쉽게 이해될 수 있다. 그라프와 토레이 (Graf
& Torrey, 1966) 는 피험자들에게 한 문장을 여러
부분으로 나누어 한 줄씩 제시했다. A 형은 각 줄이 주요 구성
성분의 경계와 일치하는 구절이었으며, B 형은 그렇지 못했다.
두 유형의 예문은 다음과 같다 :
| A 형 During World War Ⅱ. even fantastic schemes received consideration If they gave promise of shortening the conflict. |
B 형 During World War Ⅱ even fantastic schemes received consideration if they gave promise of shortening the conflict. |
| (제 2 차 세계 대전 동안, 심지어 환상적인 계획들조차 그들이 갈등을 줄일 수 있다는 보장이 있으면 심사숙고의 대상이 되었다.) |
(제 2 차 세계 대전 동안 심지어 환상적인 계획들조차 그들이 갈등을 줄일 수 있다는 보장이 있으면 심사숙고의 대상이 되었다.) |
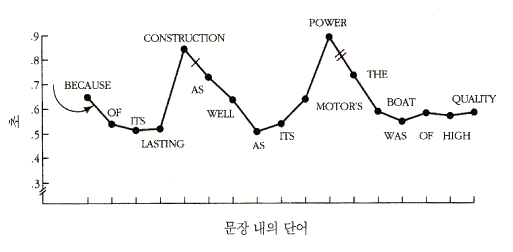
그림 2 표본 문장에서 단어 하나 하나를 읽는데 걸리는 시간, 그래프상의 짧은 선분은 구 구조 간의 끊김을 나타낸다. (Aaronson & Scarborough, 1977.)
피험자들은 A 형을 더 잘 이해했다. 이것은 구성 성분의 구조 파악이 한 문장의 구조 분석에 중요함을 보여 준다.
사람들은 그런 문장들을 읽을 때, 자연스럽게 절의 경계에서 쉰다. 아론슨과 스카보로 (Aaronson & Scarborough, 1977) 는 피험자들에게 컴퓨터 스크린에 나타나는 문장의 단어들을 하나씩 읽게 하였다. 피험자들은 다른 단어를 읽으려 할 때마다 키를 눌렀다. 그림 2 는 피험자들이 나중에 회상할 문장을 읽는 데 걸린 시간 패턴을 나타낸다. 구 경계에서 오랜 쉼이 있는 U 형태의 패턴을 주목하라. 주요 구를 완결시키면서, 피험자들은 그 구를 처리할 시간을 필요로 한다.
개인이 구성 성분 또는 구의 처리를 일단 끝내면, 구성 성분의
단어 하나하나를 더 이상 유의할 필요가 없다. 그 이유는 구성
성분이 의미의 자연스러운 단위이므로 단어들의 해석은 구성
성분의 끝에서 완결되기 때문이다. 따라서, 피험자들이 한
구성 성분의 구조 분석을 끝낸 후 새 구성 성분을 분석하기
시작했을 때는 바로 전의 구성 성분을 구성하는 개개 단어의
기억은 빈약해질 것이다. 자벨라 (Jarvella, 1971) 의 실험이
이를 증명한다. 그는 피험자들에게 짧은 글귀를 읽어 주는
도중 여러 지점에서 읽기를 중단했다. 중단 지점에서
피험자들은 들은 내용 중 기억나는 것을 가능한 한 많이
쓰라는 지시를 받았다. 흥미 있는 점이 다음과 같은 단어로
끝난 문장에서 드러났다 :
|
1 |
2 |
3 |
4 |
5 |
6 |
|
Having |
failed |
to |
disprove |
the |
charges, |
|
(고소를 논박할 수 없었기 때문에,) |
|||||
|
7 |
8 |
9 |
10 |
11 |
12 |
13 |
Taylor |
was |
later |
fired |
by |
the |
president. |
| (테일러는 후에 대통령에 의해 파면 당했다.) |
||||||
마지막 단어를 들은 후, 피험자들은 전체 문장을 회상하라는 단서를 받았다. 각 문장은 6 개 단어로 구성된 종속절 다음에 7 개 단어로 된 주절이 따른다. 그림 3 은 주어진 문장에서 나머지 12 개 단어에 대한 회상률을 보여 준다 (첫 단어는 탐사 단어이므로 제외되었다). 주절의 첫째 단어인 7번에서 함수가 크게 증가하고 있음을 주목하라. 이 자료는 피험자들이 마지막 주된 구성 성분을 가장 잘 기억함을 보여 주며, 이 결과는 피험자들이 마지막 구성 성분만은 축어적 기억 (verbatim memory) 으로 유지한다는 가설과 일치한다.
그림 3 한 단락의 마지막 열두 단어 내에서 위치 함수에 의한 단어 회상 확률. (Jarvella, 1971.)
캐플란 (Caplan, 1972) 의 실험도 구성 성분의 구조가 활용된다는 증거를 보여 주지만, 이 연구는 반응 시간 방법론을 썼다. 피험자들은 문장을 들은 후 탐사 단어를 제시 받았으며, 그 단어가 문장 내에 있었는지를 가능한 한 빨리 판단해야 했다. 캐플란은 문장 쌍을 다음과 같이 대비시켰다 :
1. Now that artists are working fewer hours oil prints are
rare.
(이제 화가들이 그림을 잘 그리지 않기 때문에
유화가 귀하다.)
2. Now that artists are working in prints are rare.
(이제 유화를 그리는 화가들이 드물다.)
이 연구의 관심은 각 문장의 끝에서 oil을 탐사 자극으로
제시했을 때 피험자들이 그 단어를 얼마나 빨리
재인하는가였다. 두 문장 모두에서 oil 의 위치는 문장 끝에서
네 번째이며 그 뒤에는 같은 단어들이 나오도록 교묘하게
만들어졌다. 사실상, 캐플란은 테이프를 이어서 피험자들이
어떤 문장을 듣건 간에 마지막 네 단어들은 같은 녹음으로
듣도록 하였다. 그러나, 문장 1 에서 oil 은 마지막 구성 성분인
oil prints are rare 의 일부인 반면, 문장 2 에서는 oil 이
첫 번째 구성 성분인 now that artists are working in oil 의
일부이다. 캐플란은 피험자들이 문장 1 에서 oil 을 더 빨리
재인할 것이라고 예언했는데 그 이유는 oil 이 포함된 마지막
구성 성분에 대한 표상이 기억에 계속 활성화 상태로 있기
때문이다. 그의 예언대로 탐사 단어는 그것이 마지막 구성
성분에 있을 때 더 빨리 재인되었다.
| 피험자들은 문장의 의미를 처리할 때 한 번에 한 구씩 다루며, 그 구의 의미를 처리하고 있는 동안에만 그 구에 접근할 수 있다. |
언어 처리 연구에서 드러난 한 주요 원리는 해석의 즉각성 (immediacy of interpretation) 원리이다. 기본적으로, 이 원리는 사람들이 각 단어에 도달하면서 그로부터 가능한 많은 의미를 추출하려 하고 한 단어를 해석학 위하여 문장의 끝까지 또는 구의 끝까지 기다리지 않음을 뜻한다. 예를 들면, 저스트와 카펜터 (Just & Carpenter, 1980) 는 피험자들이 문장을 읽을 때 그들의 안구 운동을 연구했다. 문장을 읽을 때 피험자들은 보통 거의 매 단어에 눈을 고정시킨다. 저스트와 카펜터는 피험자들이 한 단어에 눈을 고정시키는 시간이 기본적으로 그 단어가 제공하는 정보의 양에 비례함을 발견하였다. 문장에 어떤 낯설거나 놀라운 단어가 있으면, 그들은 그 단어에서 잠시 멈춘다. 사람들은 그런 단어가 있는 구의 끝에서도 오래 머뭇거린다. 그림 4 는 어떤 과학 글귀를 읽는 한 대학생의 안구 고정 패턴을 보여 준다. 각 문장에서 응시 지점은 해당 지점 위에 동그라미로 표시되어 있다. 응시 순서는 engine contains 에서의 세 번의 응시를 제외하고는 왼쪽에서 오른쪽 방향이다. The 또는 to 와 같이 중요하지 않은 기능어들은 스쳐 지나 가거나, 거의 처리되지 못한다. Flywheel 이라는 단어에서 소비한 시간을 주목하라. 피험자는 이 단어의 뜻을 생각하기 위하여 문장 끝까지 기다리지 않는다. 이번에는 정보가가 큰 형용사 mechanical 에 소비된 시간을 다시 보면, 피험자는 그 뜻을 생각하기 위하여 명사구의 끝까지 기다리지 않는다.
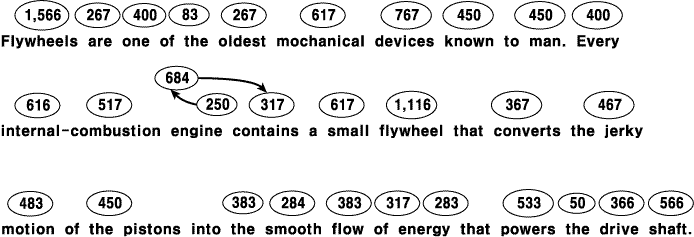
그림 4 속도 조절 바퀴 (flywheel) 에 대한 전문적 논문에서 한 대학생이 첫 두 문장의 단어들을 읽는 데 걸린 시간. 단어 위에 표시된 시간의 단위는 msec 이다. 이 독자는 왼쪽에서 오른쪽으로 문장을 읽는 과정에서 앞부분에서 한 번의 역행 고정을 나타냈다. (Just & Carpenter, 1980.)
저스트와 카펜터 (Just & Carpenter, 1987) 는 산출 규칙 모형을 제안하였는데, 이 모형은 각 단어가 그로부터 최대한의 정보를 추출하기 위하여 하나 또는 그 이상의 산출 규칙을 불러일으킨다고 가정한다. 이 모형은 the bad senator 와 같은 명사구의 구조 분석을 위해 다음과 같은 산출 규칙을 포함하며,
만일 당면한 단어가 한정사이면,
그러면 대상 기술의 처리를 준비하라.
만일 대상 기술을 처리하는데
현재의 단어가 형용사이면,
그러면 형용사의 의미를 대상 기술에 추가하라.
만일 대상 기술을 처리하는데
현재의 단어가 명사이면,
그러면 명사의 의미를 대상 기술에 추가하고
명사의 의미를 더 큰 발화에 통합시켜라.
각각의 산출은 각 단어의 의미를 명사구 해석으로 발전시키기 위해 통합한다.
이러한 처리의 즉각성은 사람들이 주 동사를 만나기 훨씬 전에 문장의 해석을 이미 시작함을 뜻한다. 이것은 확실히 문장의 맨 끝에 동사가 있는 독일어와 같은 언어를 말하는 사람들의 경험이다. 언어의 구조상 동사가 끝에 오는 경우가 드문 영어에서도 그런 것들이 경험된다. 다음과 같은 문장을 처리할 때 어떤 일이 발생하는지 보자 :
• It was president whom the terrorist from Middle East
shot.
(중동 출신의 테러리스트가 저격한 사람은 대통령이었다)
사람들은 shot 에 도달하기 전에 이미 대통령과 테러리스트 간에 어떤 일이 발생할지를 부분 모형으로 구축했다.
문장 처리가 단어 수준에서 이루어진다면, 구 구조 경계의
중요성을 밝혀 준 모든 증거들이
이상하게 보일 수도 있다. 이 증거는 문장의 의미가 구 구조를
단위로 정의된다는 사실을 반영하므로, 청자들이 각
단어로부터 모든 것을 추출하려 한다 해도, 그들이 문장
끝에서만 끼워 넣을 수 있는 어떤 것이 있다. 따라서,
사람들은 구가 끝날 때까지는 처리하지 못하는 정보가 있기
때문에 구 경계에서 쉬는 경향이 있다. 사람들은 처리 중에
있는 구의 표상을 계속 유지해야 하는데 그 이유는 그 의미
해석이 달라서 그 구를 재해석해야 하는 경우가 있기
때문이다. 그라프와 토레이가 했던 것과 같은 실험 조작이
중요한데 이 조작들은 독자에게 구의 끝을 표시해 주기
때문이다. 저스트와 카펜터는 읽기 학습시 피험자들이 그 구가
전달하는 의미를 파악하기 위하여 구의 끝에서 시간을 보내는
경향이 있음을 발견하였다. 비슷한 의미 파악 시간을 그림 2 의 읽기 패턴에서 볼 수 있다.
| 문장 처리에서, 사람들은 각 단어로부터 가능한 한 많은 정보를 추출하려고 하며 각 구의 끝에서 추가 의미를 파악하는 데 시간을 보낸다. |
문장 구조 분석의 기본 과제는 전 문장의 의미를 파악하기 위하여 개별 단어의 의미를 조합하는 것이다. 사람들이 과제를 수행하도록 도와 주는 두 기본 정보원이 있다. 그 하나는 어순이다. 예를 들면, 다음 두 문장은 같은 단어들로 구성되지만 그 의미가 매우 다르다 :
• The dog bit the cat. (개가 고양이를 물었다.)
• The cat bit the dog. (고양이가 개를 물었다.)
문장의 의미 파악을 위한 다른 정보는 a 나 who 와 같이 구조 분석에 중요한 기능어의 활용에서 온다. 그 이유는 이들이 명사구 또는 관계절과 같은 다양한 유형의 구성 성분을 표시하기 때문이다 :
1. The boy whom the girl liked was sick.
(소녀가 좋아했던 소년이 아팠다.)
2. The boy the girl liked was sick.
(소녀가 좋아했던 소년이 아팠다.)
3. The boy the girl and the dog were sick.
(소년과 소녀와 개가 아팠다.)
문장 1 과 2 는 2 에서 whom 이 삭제된 것을 제외하면 똑같다. 문장 2 가 더 짧지만, 축소의 대가로 그 문장의 해석을 돕는 단서가 빠졌다. The boy the girl 의 경우 문장 2 처럼 관계절이 있는지 또는 문장 3 처럼 접속사가 있는지 애매하다. 만일 whom 과 같은 기능어들이 문장의 구조 분석 방식을 드러낸다면, 문장 2 와 같은 구성이 문장 1 과 비슷한 구성보다 분석하기 더 어려워야 한다.
헤이크스와 포스(Hakes & Foss, 1970 ; Hakes, 1972) 는 이 예언을 음소 추적 과제 (phoneme - monitoring task) 에서 검증하였다. 그들은 다음과 같은 이중 내포 문장을 사용하였다 :
4. The zebra which the lion that the gorilla chased killed
was running.
(고릴라가 뒤쫓던 사자가 죽인 얼룩말이 달리고
있었다.)
5. The zebra the lion the gorilla chased killed was
running.
(고릴라가 뒤쫓던 사자가 죽인 얼룩말이 달리고
있었다.)
문장 5 는 관계 대명사를 생략하고 있으므로 명사로 연결된 구조를 가진 문장들과 쉽게 혼동된다. 피험자들은 동시에 두 과제를 수행했다. 한 과제는 문장을 이해하여 다른 말로 바꾸는 과제였다. 다른 과제는 한 음소 – 이 경우 [g] (gorilla 를 발음할 때처럼) 에 귀를 기울이는 것이었다. 연구자들은 이해하기 어려운 문장일수록 표적 음소의 탐지 시간이 더 길어질 것이라고 예언하였는데, 그 이유는 이해 과제를 수행하고 남은 여분의 주의로 추적 과제를 해야 하기 때문이다. 실상, 이 예언은 지지되었다. 즉, 피험자들이 문장 5 처럼 관계 대명사가 생략된 문장에서 [g] 를 파악하는 데 더 오랜 시간이 걸렸다.
영어의 지배적인 통사 단서는 어순이다. 예를 들면, 행위자가 행위 동사 이전에 나타난다. 다른 언어들은 어순에 비교적 덜 의존하고 대신에 의미의 역할을 나타내는 어형 변화를 쓴다. 어떤 영어 대명사에는 그러한 어형 변화 체계의 흔적이 다소 남아 있다. 예를 들면, he 와 him, I 와 me 등등은 행위자와 대상을 표시한다. 맥도널드 (McDonald, 1984) 는 영어를 풍부한 어형 변화 체계를 가진 독일어와 비교했다. 그녀는 영어를 쓰는 피험자들에게 다음 문장들을 해석시켰다 :
6. Him kicked the girl.
7. The girl kicked he.
어순 당서는 한 해석을, 어형 변화 단서는 다른 해석을
시사한다. 영어 화자들은 어순 단서를 써서, 문자 6 에서 him
을 행위자로 그리고 girl 을 대상으로 해석한다. 독일어
화자는 이에 해당하는 독일어 문장을 반대로 해석한다.
흥미롭게도 독일어 - 영어 2 개 국어를 쓰는 사람은 그 영어
문장을 독일어 문장처럼, 즉 문장 6 에서 him 에 대상의
역할을 그리고 girl 에 행위자의 역할을 부여하였다.
| 이해자들은 문장을 이해할 때 어순과 어형 변화라는 통사 단서들을 쓴다. |
위에서처럼, 사람들은 문장을 이해할 때 통사 구조를 쓰는 것이 분명하지만, 단어들의 의미를 활용하기도 한다. 단어들을 어떻게 배열해야 뜻이 통하는지 알기만 하면, 그 단어들의 의미를 파악할 수 있다. 타잔이 Jane fruit eat 라고 말할 때, 이 문장이 영어의 통사와 일치하지 않지만 그가 뜻하는 바가 무엇인지 알 수 있다. 먹는 사람과 먹을 수 있는 대상 간에 성립되는 관계를 아는 것이다.
사람들이 언어 이해에서 이러한 의미 방략을 쓴다는 증거는 상당히 많다. 스트로너와 넬슨 (Strohner & Nelson, 1974) 은 2 세와 3 세 아동들에게 다음 두 문장의 내용을 동물 인형을 사용해서 표현하게 하였다.
• The cat chased the mouse. (고양이가 쥐를 뒤쫓았다.)
• The mouse chased the cat. (쥐가 고양이를 뒤쫓았다.)
아동들은 두 문장 모두를 고양이가 쥐를 뒤쫓는 것으로 해석했으며, 이것은 고양이와 쥐에 대한 그들의 사전 지식과 일치한다. 이처럼 어린 아동들은 통사 패턴보다는 의미 패턴에 더 의존하고 있다.
필렌바움(Fillenbaum, 1971, 1974) 은 성인들에게 다음과 같이 '고약한' 항목들이 포함된 문장들의 말을 바꾸도록 하였다 :
• John was buried and died. (존은 땅에 묻혔고 그리고 죽었다.)
60 퍼센트 이상의 피험자들이 더 관습적 의미를 주는 문장을 바꾸었다. 예를 들면, 위의 문장을 'John died first and then was buried' 라고 표시했다. 그러나, 그러한 구성을 정상적 통사로 해석하면 첫째 활동이 둘째 활동 이전에 발생한 것으로 해석될 것이다 :
• John had a drink and went to the party (존은 술을 마시고 파티에 갔다) 는
• John went to the party and had a drink (존은 파티에 가서 술을 마셨다) 와 반대로 해석된다.
따라서, 의미 원리가 통사원리와 갈등적 관계에 놓이게 되면
의미 원리가 때로는 (언제나 그렇지는 않지만) 그 문장의
해석을 결정한다.
| 때로는 사람들이 문장 내 단어들에 대해 그럴듯한 의미 해석에 의존한다. |
청자는 문장을 이해할 때 통사와 의미 정보 모두를 조합하는 듯하다. 타일러와 마슬렌 윌슨 (Tyler & Marslen - Wilson, 1977) 은 피험자들에게 다음과 같은 불완전한 문장들을 완성하도록 하였다 :
1. If you walk too near runway, landing planes are
(활주로에 너무 가까이 가면, 착륙하는 비행기들이 ~ )
2. If you've been trained as a pilot, landing planes are
(조종사로 훈련 받았으면, 착륙하는 비행기들이 ~)
landing planes 라는 구 자체가 중의적이다. 그 구는 planes that are landing (착륙하는 비행기들) 또는 land planes (비행기를 착륙시키기) 를 뜻할 수 있다. 복수형 동사 are 가 뒤따르므로, 그것은 첫째 의미에 해당한다. 이처럼, 통사 제약이 중의적 구의 의미를 결정한다. 1 의 사전 맥락은 이 의미와 일치하지만, 2 의 사전 맥락은 그렇지 못하다. 피험자들이 더 적은 시간 안에 문장 1 을 완성시키는 것은 사전 맥락의 의미 그리고 landing planes 의 중의성을 제거하기 위한 통사로 모두를 쓰고 있음을 뜻한다. 이 요인들이 갈등적일 때, 이해가 떨어진다. (주석 : 타일러와 마슬렌 윌슨의 원래 실험은 Townsend & Bever (1982) 그리고 Cowart (1983 로부터 방법론적으로 문제점을 지적 받았다. 이에 대한 반응은 Marslen-Wilson & Tyler (1987) 를 참조할 것.)
베이츠 등 (Bates, MacWhinney, Devesocvi, & Smith, 1982) 은 통사의 의미의 조합을 다른 실험 과제로 살펴 보았다. 피험자들은 다음과 같은 단어열을 해석하였다 :
•Chased the dog the eraser
만일 꼭 해야 한다면, 이 단어열에 어떤 의미를 부여하겠는가? 목적어가 동사 뒤에 온다는 통사적 사실은 쫓기는 것은 개이고 쫓는 것은 지우개임을 함축한다. 그러나, 의미를 따지면 그 반대이다. 사실상, 미국인 화자들은 통사와의 조화를 더 선호하지만, 때로는 의미 해석을 채택하기도 한다. 즉, 다수가 The erased the dog 이라고 말하지만, The dog chased the eraser 라고 말하는 소수도 있다. 한편, 다음과 같은 경우,
• Chased the dog eraser the dog
청자들 모두는 The dog chased the eraser 하는 해석에 동의한다.
베이츠 등의 연구에서 재미있는 것은 미국인들을 이탈리아인들과 비교한 부분이었다. 통사 단서들이 의미 단서들과 갈등적일 때, 이탈리아인들은 의미 단서와 조화되는 경향을 보이는 한편, 미국인들은 통사 단서를 선호하는 경향을 보였다. 가장 결정적 사례는 다음과 같았다 :
• The eraser bites the dog
이 문장을 이탈리아어로 바꾸면 다음과 같다.
• La gomma morde il cane
미국인들은 거의 대부분 통사를 따르므로 이 문장을 지우개가 물어뜯는 행동을 한다는 의미로 해석했다. 대조적으로, 이탈리아인들은 의미를 선호해 개가 물어뜯는 행동을 한다고 해석했다. 그러나, 이탈리아어도 영어처럼 주어 – 동사 - 목적어로 구분되는 통사가 있다.
따라서, 청자들은 문장 해석에서 의미와 통사 단서 모두를
조합하고 있음을 알 수 있다. 더욱이, 언어에 따라 이 두
유형의 단서들의 비중이 다르다. 이런 저런 증거가
이탈리아인들이 미국인들에 비해 의미 단서에 더 많은 비중을
두고 있음을 시사한다.
| 사람들은 문장의 의미를 해석할 때 통사와 의미 단서 모두를 통합한다. |
문장을 해석하려면 통사와 의미를 조합해야 하는 것이 분명하지만, 이 조합이 발생하는 방식을 둘러싸고 상당한 논란이 있다. 언어 단원성 (앞 장의 논의를 참조) 을 주장하는 입장은 처음에는 단순히 통사 처리를 하다가 나중에 의미 요인이 개입된다고 주장한다. 그 이유는 통사는 그 자체가 빠르게 작용하는 언어 특유 모듈의 일부이기 때문이다. 대조적으로, 의미를 생각하기 위해서는 개인의 세상 지식을 모두 활용해야 하는데, 이는 언어 고유의 어떤 것을 훨씬 능가한다. 단원성 입장의 반대는 상호 작용 처리 (interactive processing) 를 주장하는 입장으로서, 통사와 의미가 처리의 모든 수준에서 조합된다고 주장한다.
방금 개관한 타일러와 마슬렌 윌슨, 그리고 베이츠 등의 실험들은 의미 고찰이 해석에서 중요한 역할을 하지만, 그 의미 고찰이 어떻게 그렇게 빨리 작용하게 되는지 의문을 남긴다. 이미 언급하였듯이, 단원성 입장은 피험자들이 처음에는 단지 통사 요인만 써서 분석하고 그 후 의미 요인을 사용한다고 주장한다. 이를 단어 하나하나를 축어적으로 읽은 자료로 밝힐 수 있다. 예를 들면, 페레이라와 클리프턴 (Ferreira & Clifton, 1986) 은 피험자들에게 다음과 같은 문장을 읽게 하였다 :
1. The woman painted by the artist was very attractive to
look at.
(화가가 그린 그 여성은 보기에 매우
매력적이었다.)
2. The woman that was painted by the artist was very
attractive to look at.
(화가가 그린 그 여성은 보기에 매우
매력적이었다.)
3. The sign painted by the artist was very attractive to
look at.
(화가가 그린 표지는 보기에 매우
매력적이었다.)
4. The sign that was painted by the artist was very
attractive to look at.
(화가가 그린 표지는 보기에 매우
매력적이었다.)
연구자들은 사람들이 행위자 - 행위 조합으로서 The woman painted 와 같은 명사 - 동사 조합을 자연스럽게 약호화하는 경향을 주목했다. 이에 대한 증거로 피험자들이 둘째 문장 보다 첫째 문장에서 by the artist 를 읽는 데 시간이 더 걸렸다. 그 이유는 행위자 - 행위에 관한 그들의 해석이 첫째 문장에서 틀렸으므로 재해석해야 하지만 한편 둘째 문장에서 통사 단서 that was 가 그들로 하여금 틀린 해석을 다시 하지 않도록 막아 주기 때문이다.
페레이라와 클리프턴 실험의 주요 관심은 문장 3 과 4 에 있었다. 의미 요인들은 문장 3 의 행위자 - 행위의 해석을 제거해야 하는데, 표지 (sign) 가 살아 있는 주체가 될 수 없고 그리는 행위에 종속되어 있기 때문이다. 그럼에도 불구하고, 피험자들은 문장 3 에서 by the artist 를 읽는 데 문장 1 만큼 오래 걸렸으며 의미가 분명한 문장 2 또는 4 보다 더 오래 걸렸다. 이처럼, 연구자의 주장대로, 피험자들이 처음에 통사 요인만으로는 The sign painted 가 오역되므로 오역을 바로잡기 위해 by the artist 구의 통사 단서를 쓴다. 이처럼, 의미 요인들이 그 기능을 다해 오역을 피하게 할 수 있었던 반면, 피험자들은 통사 단서만을 사용해서 초기 처리를 하는 듯하다.
이런 실험들 (Rayner, Carlson, & Frazier, 1983 참조) 이 언어의 단원성을 지지하는 증거로 간주되어 왔다. 여기서 논지는 초기의 언어 처리는 소위 통사라는 언어 특유의 어떤 것을 활용하고, 세상에 대한 다른 일반적, 비언어적 지식 (예를 들어, 표지가 무엇을 그릴 수 없다는) 은 무시한다는 것이다. 그러나, 다른 사람들 (예 : McCelland, 1987) 은 이 결과가 영어에서 약한 의미 단서에 매우 강한 통사 단서 (명사-동사 연결을 행위자 - 행위로 해석하려는 경향성) 를 배치할 때 생긴다고 주장하였다.
타라반과 맥클레랜드(Taraban & McClelland, 1988) 는 통사 단서가 약할 때 의미 단서가 효력이 있는 실험을 보고한다. 그들은 다음과 같은 문장들을 사용하였다 :
1. The spy saw the cop with binoculars.
(스파이는 경찰을 쌍안경으로 보았다.)
2. The spy saw the cop with d revolver.
(스파이는 권총을 가진 경찰을 보았다.)
3. The reporter exposed corruption in the article.
(기자는 기사에서 부패를 폭로하였다.)
4. The reporter exposed corruption in the government.
(기자는 정부의 부패를 폭로하였다.)
여기서 문장 1 과 3 의 마지막 전치사 구는 주 문장의 일부이지만, 문장 2 와 4 에서는 명사구의 일부이다.
통사의 입장에서 보면, 이 전치사구를 주 문장으로 일부로
간주하면 더 쉽게 해석되면 (Frazier, 1979) 그리고 실제로
피험자들이 문장 1 에서 binocular 를 읽는 시간이 문장 2
에서 revolver 를 읽는 시간보다 적게 걸렸다. 이것은 그들이
통사적으로 선호하는 해석을 먼저 시도함을 반영한다. 그러나,
피험자들이 문장 4 의 government 를 문장 3 의 article보다
더 빨리 읽을 수 있다. 평정법을 이용한 연구에서 타라반과
맥클레랜드는 빨리 읽혀지는 구성은 그 문장 맥락이 주어졌을
때 기대되는 구성임을 보여 주었다. 피험자들은 The spy saw
the cop 문장에서 전치사구가 주 문장의 일부일 것임을
기대하지만, The reporter exposed corruption 에서는 반대의
기대를 가진다. 따라서, 이 경우, 해석은 통사가 아닌 기대의
주도로 진행된다.
| 단원성 입장은 문장의 초기 해석을 이끌어내는 데 보통 통사 단서만이 쓰이고 그 다음에 의미 단서가 쓰인다고 주장한다. |
페레이라와 클리프턴의 연구를 포함하여 지금까지 개관된 연구들은 중의성이 언어 이해자가 다루어야 하는 한 문제임을 보여 준다. 둘 또는 세 가지 해석이 가능한 문장들이 있는데 단어들이 중의적이거나 통사 구성이 중의적인 경우이다. 그러한 문장 예들을 보자 :
• John went to the bank.
(존은 은행으로 / 강둑으로 갔다.)
• Flying planers can be dangerous.
(비행기 타기는 / 날고 있는 비행기는 위험할 수
있다.)
일시적 중의성과 영구적 중의성을 또한 구분할 필요가 있다. 위의 문장들은 영구적 중의성의 예이다. 즉, 중의성은 문장 끝까지 남아 있다. 일시적 중의성 (transient ambiguity) 은 일시적으로는 모호하지만 다음과 같이 문장 끝에 가서는 전혀 모호하지 않은 문장을 말한다 :
• The old train the young. (노인들이 젊은이들을 훈련시킨다.)
train 까지 가도, old 가 명사인지 형용사인지 불분명하다. train 을 명사로 하여 다음과 같은 문장으로 계속 이어질 수 있었다 :
• The old train left the station. (낡은 기차가 정거장을 떠났다.)
여기서 중의성은 문장 끝에서 해소된다.
일시적 중의성은 언어에 매우 널리 퍼져 있으며, 앞서 본 처리의 즉각성과 심각한 상호작용을 일으키기도 한다. 처리의 즉각성은 단어 또는 구를 즉각적으로 해석할 필요가 있음을 함축하지만, 일시적 중의성은 정확한 해석을 즉각적으로 알기 어려움을 함축한다.
다음 문장을 보자 :
• The horse raced past the barn fell. (창고를 지나 달리던 말이 넘어졌다.)
많은 사람들이 이 문장에 대하여 처음 내린 해석과는 다른 해석을 내리는 이중 입장을 취한다. 이런 문장들을 정원 통로 문장 (garden-path sentences) 이라고 말하는데, 그 이유는 어떤 지점에서 한 가지 해석을 하지만 다른 지점에서 그 해석이 틀렸음을 알게 되기 때문이다. 예를 들면, 위의 문장에서 많은 사람들은 raced 를 문장의 주동사로 해석한다. 정원 통로 문장이 있다는 것은 해석의 즉각성 원리에 관한 중요한 증거 중 하나로 생각된다. 사람들은 중의성이 제기되는 지점에서 그러한 문장의 해석을 중의성이 해결될 때까지 미룰 수도 있지만, 미루지 않는다.
문장에서 통사적 중의성이 제기되는 지점에 도달하면, 무엇이 해석을 결정하는가? 강력한 원리로서 최소 부착의 원리 (principle of minimal attachment) 가 있다. 이 원리는 기본적으로 사람들이 구 구조를 최소한으로 복잡하게 만드는 방식으로 문장을 해석한다고 말한다. 모든 문장들이 주동사를 포함하기 때문에, 이는 horse 를 수식하는 관계절을 만들기보다는 reced 를 주 문장에 포함시켜 해석함을 뜻한다.
같은 해석 원리가 앞에서 개관한 페레이라와 클리프턴이 쓴 실험 재료에 적용된다. 연구자들이 다음과 같은 문장을 제시하였을 때,
• The woman painted by the artist was very attractive to look at.
피험자들은 The woman painted 를 행위자 - 행위로 해석하였으나, by the artist 를 읽고 해석을 철회해야 했다. 최소 부착의 원리는 이를 예언하는데 그 이유는 관계절 보다 행위자-행위 해석을 가정하는 편이 더 간단하기 때문이다. Horse raced 의 예와는 달리, The woman painted 문장을 읽은 많은 사람들은 그들이 자신의 해석을 바꾼 것조차 모르고 있다. 그럼에도 불구하고, 그들의 읽기 시간은 정말로 그들의 이중 입장을 보여 준다. 한 가지 해석을 즉각 내리고, 필요하면 후속해서 재해석을 내리는 현상은 읽기 시간을 다룬 여러 연구에서 관찰되었다 (예 :Frazier & Rayner, 1982 ; Rayner, Carlson, & Frazier, 1983 ; Taraban & McCelland 1988).
사람들이 horse raced 와 같은 문장에서는 재해석을 깨닫지만,
woman painted 와 같은 문장에서는 재해석을 깨닫지 못하는
이유는 무엇일까? 만일 통사적 중의성이 그 중의성을 포함하고
있는 구 안에서 해결되면, 구 가지 해석을 고려했던 것조차
깨닫지 못한다. 중의적 구 밖으로 해결을 미루는 경우에만
그것을 재해석할 필요를 느낀다. 따라서, woman painted 의
예에서, 중의성은 절이 끝나기 전에 해결되므로 많은 사람들은
중의성의 존재를 깨닫지 못한다. 대조적으로, horse raced 의
예에서, 이 구는 성공적으로 완료되나 - the horse raced past
the barn 처럼 – 단지 나중에서야 부정된다.
| 이해자들이 문장에서 중의적인 지점에 오면, 그들은 나중에 부정될 경우 철회해야 하는 해석을 택한다. |
앞서 최소 부착의 원리에 관한 논의는 피험자들이 통사적 중의성을 어떻게 다루는지에 관심을 두었다. 한 단어가 두 가지 뜻을 갖는 어휘 중의성의 경우, 두 문장을 해석하는 데 구조상의 차이가 없으므로, 최소 부착의 원리가 의미 선택에 기여하지 못한다. 예를 들어, 스위니 (Swinney, 1979) 의 실험들은 중의적 단어들이 그 중의성을 어떻게 벗어나는지를 밝혀 준다. 그는 피험자들에게 다음과 같은 문장들을 들려 주었다.
• The man was not surprised when he found several
spiders, roaches, and other bugs in the corner of the
room.
(그 남자는 방구석에서 거미, 바퀴벌레, 그리고 다른 벌레들을
발견했을 때, 별로 놀라지 않았다.)
스위니는 중의적 단어bugs (벌레 또는 전기 도청 장치를 뜻함) 에 관심이 있었다. 이 단어
를 들려 준 직후, 스크린에 글자열이 제시되었으며, 피험자의 과제는 그 글자열이 단어인지아닌지를 판단하는 것이었다. 예를 들면, ant 를 보면 예라고 답해야 하고, ont 를 보면 아니오라고 답해야 한다. 이것은 활성화 확산 기제를 논의할 때 6 장에서 소개한 어휘 판단과제이다. 스위니는 bugs 가 어휘 판단을 어떤 식으로 점화할 것인지에 관심이 있었다.
중요한 비교는 피험자들이bugs 에 뒤이어 spy, ant 또는 sew
를 판단하는 경우를 포함한다. Ant 는 bugs 의 점화 단어이고,
spy 는 비점화된 의미와 관련된다. sew 는 중립적 통제
조건이다. 판단해야 할 단어가 점화 단어인 bugs 가 제시된
후, 400 ms 이내에 제시되면 spy 와 ant 모두의 재인이
빨라졌다. 이처럼, bugs 제시는 그 의미들과 연상 내용 모두들
즉각적으로 활성화시킨다. 만일 점화 단어를 제시한 후 700 ms
를 기다리면 관련 단어인 ant 에만 촉진 현상이 나타난다.
정확한 의미가 이 시간 내에서 선택되고 다른 의미가 비활성화되는 듯하다. 따라서, 중의적 단어의 두 의미는 순간적으로
활성화되지만, 맥락이 적절한 의미를 선택하기 위해 매우 빨리
작용한다.
| 중의적 단어가 제시되면, 피험자들은 700 ms 이내에 특정한 의미를 선택한다. |
지금까지 이해자가 단어열로부터 그 열의 의미 해석에 이르기까지 경험하는 과정에 초점을 두었다. 이 해석의 복잡성에 영향을 주는 요인들 (중의성, 통사 단서의 존재)이 이해 과정에 영향을 미침을 보았다. 그러나, 이해가 해석 결과의 복잡성에 의해서도 영향을 받는다. 이를 측정하기 위한 한 방법은 의미의 표상을 명제의 수로 세는 것이다. 예를 들면, 킨치와 키넌 (Kintsch & Keenann, 1973) 은 다음 두 문장의 이해를 비교하였다 :
1. Romulus, the legendary founder of Rome, took the women of the Sabine force. (로마를 창설한 전설적인 인물인 로물로스는 폭력으로 사빈의 여인들을 빼앗았다.)
2. Cleopatra's downfally lay in her foolish trust in the fickle political figures of the human world. (클레오파트라의 멸망은 인간 세상의 변덕스러운 정치적 인물들을 어리석게 신뢰한 데 있다.)
킨치의 명제 분석에 따르면(5 장 참조) 문장 1 은 네 개의 명제들로 구성 된다 :
• (빼앗았다. 로물로스, 여인들, 폭력으로)
• (창설하다, 로물로스, 로마)
• (전설적이다, 로물로스)
• (사빈, 여인들)
둘째 문장은 여덟 개의 명제들로 구성된다.
• (왜냐하면, a, b)
(주석
: a 와 b 는 둘째 및 셋 째 명제가
첫째 명제에 대한 논항으로 발생함을 나타낸다. 이 책 157 -
160 쪽에 있는 명제의 위계적 체제화에 관한 논의를
참조하라.)
• (멸망했다, 클레오파트라) = a
• (신뢰하다, 클레오파트라, 인물들) = b
• (어리석다, 신뢰하다)
• (변덕스럽다, 인물들)
• (정치적이다, 인물들)
• (부분이다, 인물들, 세상)
• (인간, 세상)
이 두 문장이 명제 수에서는 다르지만, 길이나 다른 면에서
비슷하다. 킨치와 키넌은 피험자들이 시간을 더 들여 둘째
문장을 읽었음을 발견했다. 이 결과는 그 문장에서 더 많은
명제들을 추출해야 한다는 사실을 반영한다.
| 이해 시간은 문장에서 소통되는 명제 수와 함께 증가한다. |
문자의 구조가 일단 분석되고 그 의미가 표상된 후, 어떤 일이 발생하는가? 청자가 그 의미를 단순히 수동적으로 기록하는 일은 드물다. 만일 그 문장이 의문문이거나 명령문이면, 화자는 청자가 반응으로 어떤 행위를 취하기를 기대한다. 그러나, 서술문의 경우에도 문장을 단순히 등록하는 것 이상으로 해야 할 일이 더 있다. 앞서 나온 다음 문장을 보자 :
• 클레오파트라의 멸망은 인간 세상의 변덕스러운 정치적 인물들을 어리석게 신뢰한 데 있다.
이 문자의 구조를 분석한 결과 드러난 면제 표상들이 앞에서 제시되었다. 그러나, 이 문장을 이해하려는 독자는 이 명제 표상을 능가할 가능성이 있다. 독자는 안토니와 클레오파트라의 로맨스를 미화할 수 있고, 안토니가 언급되는 정치적 인물 중 하나가 아닌지 생각할 수 있고, 클레오파트라의 자살로 멸망을 정교화하는 것 등이다. 문장을 정말로 제대로 이해하려면 이러한 추리와 연결이 필요하다. 6 장에서는 이 같은 정교화 과정이 어떻게 해서 더 향상된 기억을 초래하는지를 논의했다. 여기서는 사람들이 문자 그대로의 의미를 쓸 만한 다른 의미로 바꾸는 어떤 기제를 논의하겠다.
언어 메시지는 많은 것을 말하지 않고 남겨둔 상태이므로, 이해자는 이런 빠진 정보를 부분적으로 보충해야 한다. 예를 들면, 다음 문장을 보자.
• Alice pounded in the nail until the board was safely
secured.
(엘리스는 나무판이 안전하게 될 때까지 못을
내리쳤다)
엘리스가 망치를 사용했다고 명시되지 않았는데도 독자들은 그녀가 망치를 사용했다고 추리하는가? 사람들이 나중에 그 문장을 회상하라는 요청을 받으면, 그들은 자주 망치를 회상한다. 이 결과는 추리가 처음 읽을 때 이루어지는지 또는 회상 할 때 이루어지는지를 쟁점으로 남긴다 (7 장에서의 논의를 참조). 매쿤과 래트클리프 (Mckoon & Ratchcliff, 1981) 는 어떤 상황에서는 피험자들이 덩이글을 읽을 때 그런 추리를 한다는 증거를 발견하였다. 그들은 피험자들에게 다음과 같이 시작하는 다섯 개의 연속된 문장을 읽게 하였다 :
1. Bobby got a saw, hammer, screwdriver, and a square from
the toolbox.
(보비는 연장통에서 톱, 망치, 드라이버, 그리고
직각자를 꺼냈다.)
피험자는 세 문장을 더 읽고 마지막 핵심 문장을 읽었다.
2. The Bobby pounded the boards together with nails.
(그리고 바비는 나무판들을 못으로 함께 박았다.)
마지막 문장을 읽은 직후, 피험자들은 검사 단어를 제시 받고 그 단어가 그 단락에서 나왔는지를 질문 받았다. 피험자들은 마지막 문장으로 다음 3 번 문장을 받았을 때 보다 2번 문장을 받았을 때 망치를 더 많이 보았다고 보고하였다 :
3. Then Bobby stuck the boards together with glue.
(그리고 바비는 나무판을 고무줄로 함께 붙였다.)
따라서, 매쿤과 래트클리프는 피험자들이 망치를 'pounding' 이 들어 있는 문장에서 추리했다고 결론을 내렸다, 그러나, 만일 문장 1 이 망치의 존재를 나타내지 않았다면, 피험자들이 문장 2 를 읽고도 망치를 추리하지 못한다.
때로는 사람들이 추리를 하는 상황이 완벽하지 못하다. 싱어 (Singer, 1980) 는 피험자들이 다음 세 문장 중 하나를 학습하도록 하였다 :
1. 투수는 공을 1 루로 던졌다. 주자는 1 루와 2 루 중간에 있었다.
2. 투수는 1 루로 공을 던졌다. 공은 외야로 날라갔다.
3. 투수는 1 루로 던졌다. 주자는 1 루와 2 루 중간에 있었다.
그리고 그는 피험자들에게 다음 문장의 진실 여부를 판단하도록 하였다.
• 투수는 공을 던졌다.
피험자들이 명시적으로 주장된 문장 1 을 학습했든 함축된
의미로 나타난 문장 2 를 학습했든 그들 모두가 똑같이 검사
문장을 빠르게 판단했으나, 역시 함축된 의미로 문장 3 을
학습한 피험자들은 이를 검증하는데 4 분의 1 초가 더 느렸다.
문장 2 와 3 의 차이는 2 의 경우, 두 문장을 연결하기
위해 추리가 필수적이었다. 그 내용이 특별히 뚜렷한 재료를
포함하고 있을 때 (매쿤과 래트클리프의 실험처럼) 또는
이해자가 재료에 특별히 관심이 있을 때, 추리가 일어날
가능성은 더 커진다고 주장했다. 6 장에서 덩이글 재료에 대한
기억은 만일 독자가 의식적으로 추리 과정에 적극 참여하면
증진된다는 증거를 회상하라. 이것은 정상적 읽기 행동이 그런
추리 과정을 포함하지 않을 수도 있음을 함축한다.
| 덩이글 재료에서 추리는 단지 이따금씩 이루어진다. |
언어 처리의 다른 면은 지시어 (reference) 해결을 포함한다.
언어소통에서 어떤 표현은 같은 것을 언급하므로, 이해자는 이
공통의 지시어를 파악해야 한다. 예를 들면, 애보트와
카스텔로 (Abbott & Costello) 간의 고전적 대화를 보자 :
|
애보트 : |
이상하게 보이지만 그들은 요즈음 구기 선수들에게 특이한 이름을 붙여 주는 것같아. |
| 카스텔로 : |
우스운 이름들? |
| 에보트 : |
별명, 별명 말이야. 이제부터 세인트 루이스 팀의 누구가 첫째이고, 무엇이 둘 째고, 나는 몰라가 셋째야. |
| 카스텔로 : |
그게 내가 알고자 했던 거야. 나는 네가 내게 세인트 루이스 팀 선수들의 이름들을 말해 주었으면 좋겠어. |
| 에보트 : |
지금 말해 주고 잇잖아. 누구가 첫째이고, 무엇이 둘째이고, 나는 몰라가 셋째야. |
| 카스텔로 : |
너 그 친구들의 이름을 아니? |
| 에보트 : |
응 |
| 카스텔로 : |
자, 그러면, 누구가 처음 뛰지? |
| 에보트 : |
응 |
| 카스텔로 : |
1 루에 있는 친구 이름이 무엇이냐는 뜻이야. |
| 애보트 : |
누구. |
| 카스텔로 : |
1 루에 있는 녀석. |
| 에보트 : |
누가가 1 루에 있어. |
| 카스텔로 : |
그런데, 너는 내게 무엇을 묻고 있니? |
| 애보트 : |
나는 네게 묻고 잇지 않아 – 나는 네게 말해 주고 있어. 누구나 1 루에 있어. |
| 카스텔로 : |
나는 네게 묻고 있어 – 누구가 1 루에 있니? |
| 애보트 : |
그게 바로 그 사람 이름이야. |
| 카스텔로 : |
누구가 그 사람 이름이야? |
| 애보트 : |
응. |
이 대화에서 유머는 카스텔로가 누구와 1 루에 있는 녀석이란 표현이 같은 지시어임을 깨닫지 못한다는 사실에 있다. 보통, 지시어를 깨닫는 데는 거의 어려움이 없다 (그러므로 궁극적으로 유머를 즐길 기회를 놓치고 만다.). 지시어 해소 문제에 사용되는 원리들이 차차 이해되고 있다. 영어에서 한 언어 단서는 정관사 the 와 부정관사 a 간의 차이에 의존하는 것이다. 정관사 the 는 이해자가 명사구의 지시어를 알아야 할 때, 한편 부정 관사 a 는 새 물체를 소개할 때 쓰인다. 다음 문장들 간의 차이를 비교해 보자 :
1. Last night I saw the moon. (지난 밤 나는 달을 보았어.)
2. Last night I saw a moon. (지난 밤 나는 달 하나를 보았어)
문장 1 은 전과 다름 없이 같은 달을 본 보편적인 사건임을 나타내지만 2 는 새 달을 보았음을 명백히 함축하고 있다. 이해자들이 문장 내의 이 같은 작은 차이로 소통되는 의미에 매우 예민함을 보여 주는 증거가 상당히 많다. 하빌랜드와 클라크 (Haviland & Clark, 1974) 는 이 문제에 초점을 둔 실험을 보고한다. 그들은 다음과 같은 두 문장 쌍들의 이해 시간을 비교했다 :
3. Ed wad given an alligator for his birthday. The alligator was his favorite present. (에드는 그의 생일 선물로 악어를 받았다. 그 악어는 그가 가장 좋아하는 선물이었다.)
4. Ed wanted an alligator for his birthday. The alligator was his favorite present. (에드는 그의 생일 선물로 악어를 원했다. 그 악어는 그가 가장 좋아하는 선물이었다.)
두 쌍의 문장 모두에서 둘째 문장은 같다. 3 은 악어에 대항 특정 선행사를 첫 문장에 도입한다. 한편, 4 는 악어가 첫 문장에서 언급되지만, 특정 악어를 가정하지 않는다. 따라서, 4 의 첫 문장에서 악어에 대한 선행사가 없다. 4 의 둘째 문장에 있는 정관사 the 는 특정 선행사를 가정한다. 그러므로, 피험자들이 3 이 아닌 4 의 둘째 문장에서 어려움을 겪을 것으로 예상된다. 이 실험에서 피험자들은 그런 문장 쌍들을 한 번에 하나씩 보았다. 각 문장을 이해한 후 그들은 단추를 눌렀다. 둘째 문장이 제시될 때부터 단추를 누르기까지가 이해에 걸린 시간으로 측정되었다. 선행사가 있는 3 의 둘째 문장을 이해하는 데는 평균 1.031 ms가 걸렸지만, 정관사를 포함한 명사구의 선행사가 없는 4 의 둘째 문장을 이해하는 데는 1,168 ms 가 걸렸다. 따라서, 선행사가 없었을 때 이해는 1/10 초가 더 걸렸다.
로프터스와 자니 (Loftus & Zanni, 1975) 는 관사의 선택이 청자의 신념에 영향을 줄 수 있음을 보여 주는 실험을 하였다. 그들은 피험자들에게 자동차 사고 장면을 영화로 보여 주고 몇가지 질문을 하였다. 어떤 피험자들은 다음과 같은 질문을 받았다 :
5. Did you see a broken headlight ? (당신은 깨진 헤드라이트를 보았습니까?)
다른 피험자들은 다음 질문을 받았다 :
6. Did you see the broken headlight ? (당신은 깨진 그 헤드라이트를 보았습니까?)
실상, 영화 장면에는 깨진 헤드라이트가 없었으나, 질문 6 은
정관사를 쓰므로, 깨진 헤드라이트의 존재를 가정한다.
피험자들이 6 으로 질문을 받았을 때, 예 반응이 더 많았다.
연구자들이 주목했듯이. 이 발견은 목격자 증언에서 질문의
중요성을 일축한다.
| 이해자들은 정관사 the 가 그 명사가 지시하는 대상의 존재를 함축한다고 생각한다. |
지시어 처리의 다른 면은 대명사의 해석에 관한 문제이다. She 와 같은 대명사를 들으면, 누가 언급되는지가 중요하다. 몇 명이 이미 언급되었으면, 그들 모두가 지시 대명사의 후보들이다. 저스트와 카펜터 (Just & Carpenter, 1987) 는 지시 대명사를 해결하는 몇 가지 근거를 주장했다 :
1. 가장 간단한 방법 중 하나는 주 또는 성별 단서를 사용하는 것이다. 다음 문장을 보면,
• 멜빈, 수전 및 그들의 자녀들은 (그가, 그녀가, 그들이) 졸립기 시작할 때 떠났다.
각각의 가능한 대명사는 고유한 지시어를 가진다.
2. 지시 대명사에 대한 통사 단서는 대명사들이 동일한 문법적 역할을 하는 대상 (예 : 주어 대 목적어)을 가리키는 경향이 있다고 한다. 다음 문장을 보자.
• 플로이드는 버트를 때린 다음 그는 그를 발로 찼다.
사람들은 주어 그는 플로이드이고 , 목적어 그는 버트임에 동의한다.
3. 가장 최근에 언급된 사람을 선호하는 강한 신근성 효과가 있다. 다음 문장을 보면,
• 도로시아는 파이를 먹었고, 에텔은 케이크를 먹었고, 나중에 그녀는 커피를 마셨다.
사람들은 그녀가 아마 에텔을 가리킨다고 동의할 것이다.
4. 마지막으로, 사람들은 세상 지식을 써서 지시어를 정할 수 있다. 다음 문장을 보자 :
• 톰은 빌에게 소리쳤는데 그가 커피를 쏟았기 때문이다.
• 톰은 빌에게 소리쳤는데 그가 머리가 아팠기 때문이다.
사람들은 첫 문장에서 그는 빌이라는 데 동의하는데, 그 이유는 사람들은 실수를 저지른 사람을 보통 꾸짖기 때문이며, 한편 둘째 문장에서 그는 톰을 가리키는데 그 이유는 사람들이 머리가 아프면 까다로워지기 때문이다.
앞서 언급된 해석의 즉각성 원리와 병행하여, 사람들은 대명사를 접하게 되면 곧 그 지시어를 지정하려는 경향이 있다. 예를 들면, 눈의 고정 (eye fixation) 에 관한 연구들 (Carpenter & Just, 1977 : Ehrlich & Rayner, 1983 ; Just & Carpenter, 1987) 은 사람들이 대명사에서는 그 이전의 고정보다 더 오래 쉬는 경향을 발견했다. 에를리히와 레이너 (Ehrlich & Rayner, 1983) 도 피험자들이 지시어가 해결되면 다음 고정으로 흘러 넘어가는 경향을 발견하였다. 이에 관한 그들의 증거로 피험자들은 그 대명사 다음에 문장을 거슬러 올라가서 그 대명사의 지시어에서 다음 고정 시간을 많이 보낸다는 것이었다.
코베트와 장(Corbett & Chang, 1983) 은 피험자들이 하나의 지시어에 대하여 여러 후보를 생각한다는 증거를 찾았다. 그들은 피험자들에게 다음 문장을 읽게 하였다 :
• 스콧은 워렌의 농구공을 빼앗았으며 그는 점프 슛을 넣었다.
이 문장을 읽은 후 피험자들은 탐사 단어를 보고 그 단어가 문장에 있었는지를 정해야 했다. 연구자들은 스콧 또는 워렌을 재인하는 시간이 문장을 읽은 후 점차 감소함을 발견하였다. 그들은 피험자들에게 대명사의 지시어를 정하지 않아도 되는 다음 통제 문장도 읽게 하였다 :
• 스콧은 워렌의 농구공을 빼앗았으며 스콧은 점프 슛을 넣었다.
이 경우 스콧의 재인만이 촉진되었다. 워렌은 첫 문장에서만 촉진되었는데, 그 이유는 워렌을 그에 대한 지시어로 고려해야 했기 때문이다.
쳉과 코베트의 연구 그리고 에를리히와 레이너의 연구 모두는
지시 대명사의 해결은 대명사 자체를 읽은 후에도 지속됨을
나타낸다. 이것은 처리가 항상 해석의 즉각성 원리가
적용되듯이 그렇게 즉각적이지 않음을 뜻한다. 지시 대명사의
처리는 나중의 고정으로 흘러 넘어가며 (Ehrlich &
Rayner), 문장 끝에서 선택되지 않은 지시어는 여전히
점화되어 있다 (Cheng & Corbett).
| 이해자들은 대명사의 지시어로 여러 가능한 후보를 고려하며 한 지시어를 택할 때 통사 및 의미 단서를 사용한다. |
부정문들은 긍정문을 전제로 그 반대를 주장하는 것으로 보인다. 예를 들면, 존은 사기꾼이 아니다 는 존은 사기꾼이다 를 전제로 하는 것이 합리적이지만 그 가정이 틀렸음을 주장한다. 다른 예로서, 기분이 어떻니? 라는 질문에 대하여 건강한 친구의 답을 다음 네 가지로 생각해 보자 :
1. 좋아.
2. 나쁜데.
3. 좋지 않은데.
4. 나쁘지 않은데.
1 에서 3 까지의 답들은 언어학적으로 유별나지 않지만, 4 는 특이해 보인다. 부정문을 써서, 친구의 건강이 나쁘다는 생각을 온당하다고 가정한다. 대조적으로, 3 의 부정은 수용할 만한데, 그 이유는 친구가 건강하다는 가정이 온당하기 때문이다.
클라크와 체이스 (Chase & Clark, 1972 ; Clark & Chase, 1972 ; Clark, 1974) 는 부정어 검증을 여러 실험에서 다루었다 (Trabasso, Rollins, & Shaughnessy, 1971 : Carpenter & Just, 1975 참조). 어떤 실험에서, 그들은 피험자들에게 그림 5 에 있는 카드를 제시하고 다음 네 문장 중 하나의 진위를 판단하게 하였다 :
1. 별표가 더하기표 위에 있다 — 참 긍정
2. 더하기표가 별표 위에 있다 — 거짓 긍정
3. 더하기표는 별표 위에 있지 않다 — 참 부정
4. 별표는 더하기표 위에 있지 않다 — 거짓 부정
참과 거짓은 문장이 그림과 일치하는지를, 긍정과 부정은 문장 구조가 부정 요소를 포함하는지를 나타낸다. 문장 1 과 2 는 간단한 주장을 내포하지만, 문장 3 과 4 는 가정과 가정
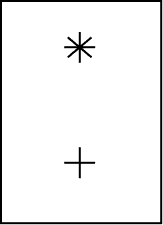
그림 5 클라크와 체이스의 문장 검증 실험에서 피험자들에게 제시된 카드. 피험자들은 긍정 단문과 부정 단문이 이 패턴을 정확하게 묘사하는지 판단해야 했다.
하에 이 가정이 틀렸음을 주장하며, 문장 4 는 별표가 더하기표 위에 있다는 가정하에 이 가정이 틀렸음을 주장한다. 크라크와 체이스는 피험자들이 가정을 먼저 점검한 후 부정어를 처리할 것이라고 생각했다. 문장 3에서는 가정이 그림과 맞지 않지만, 문장 4 에서는 가정이 실제의 그림과 맞는다. 가정이 그림과 맞지 않으면 처리가 늦을 것이라고 생각하고, 연구자들은 피험자들이 거짓 부정인 문장 4 보다 참 부정인 문장 3 에 더 늦게 반응할 것으로 예측했다. 대조적으로, 피험자들이 참 긍정인 문장 보다 거짓 긍정인 문장 2 를 처리하는 데 더 오래 걸려야 하는데, 그 이유는 문장 2 의 주장이 그림과 맞지 않기 때문이다. 실상, 문장 2 와 1 간의 차이는 문장 3 과 4 간의 차이와 같다고 보아야 하는데, 그 이유는 두 경우 모두에서 차이는 주장이 그림과 맞지 않기 때문에 걸리는 초과 시간을 나타내기 때문이다.
클라크와 체이스는 이 자료에 대해 간단하면서도 우아한 수리 모형을 개발하였다. 그들은 문장 3 과의 처리가 문장 1 과 2 의 처리보다 N 시간 단위만큼 더 든다고 가정했는데, 그 이유는 3 과 4 는 더 복잡한 가정과 부정의 구조를 가지고 있기 때문이었다. 그들은 도한 그림이 주장과 맞지 않기 때문에 문장 2 를 처리하는데 문장 1 보다 M 시간 단위가 더 들고, 마찬가지로 그림과 가정이 맞지 않기 때문에 문장 3 의 처리가 4 보다 M 시간 단위만큼 더 든다고 가정했다. 마지막으로 문장 1 과 같은 참 긍정을 처리하는 데 T 시간 단위가 걸린다고 가정하자. T 는 부정어가 없고 가정이 그림과 맞는 경우에 걸린 시간을 나타낸다. 3 과 같은 문장 처리에 걸린 시간을 계산해 보자. 이 문장은 가정과 부정의 복잡한 구조를 가지고 있으므로 N 시간 단위를 요하고, 가정이 그림과 맞지 않으므로 M 시간 단위를 요한다. 그러므로 전체 처리 시간은 T + M + N 이 되어야 한다. 표 1 은 그들의 실험에 실험에서 관찰된 자료와 예언된 시간을 나타낸다. 이 실험에서 T, M 및 N 에 대한 최선의 예언치는 T = 1,469 ms, M = 246 ms, 그리고 N = 320 ms 로서 얻어진 자료로부터 추정될 수 있다. 표를 보면, 예언치와 관찰된 시간이 잘 들어맞음을 알 수 있다. 특히, 참 부정과 거짓 부정 간의 차이는 참 긍정과 거짓 긍정 간의 차이에 가깝다. 이 발견은 피험자들이 부정문을 처리할 때 그 가정을 추출해서 그것을 그림과 맞추어 본다는 가설을 지지한다.
표 1 실험 검증에서 관찰된 그리고 예언된 반응 시간
|
조건 |
관찰된 시간 |
식 |
예측된 시간 |
|
참 긍정 거짓 긍정 참 부정 거짓 부정 |
1,463 msec 1,722 msec 2,028 msec 1,796 msec |
T T + M T + M + N T + N |
1,469 msec 1,715 msec 2,035 msec 1,789 msec |
| 이해자들은 부정어를 처리할 때 거기에 포함된 가정을 먼저 다룬 다음 부정을 처리한다. |
지금까지의 논의는 하나의 문장 이해에 초점을 맞추어 왔다. 문장들은 흔히 교과서를 읽는 것처럼, 더 큰 맥락에서 처리된다. 이제 덩이글 이라는 큰 구조를 활용하는 과정에 미치는 효과들을 살펴보자.
덩이글도 문장처럼 어떤 패턴에 따라 구성되는데, 이 패턴은 문장과 관련된 패턴보다 유연하다. 1970 년대에 많은 연구들이 덩이글이 구성되는 방식을 다루었다 (예 : Grimes, 1975 ; Kintsch ; 1977 ; Kintsch & van Dijk, 1976 ; Mandler & Johnson, 1977 ; Meyer, 1974 ; Rumelhart, 1975 ; Thorndyke, 1977 ; van Dijk, 1977 ; van Dijk & Kintsch. 1976). 연구자들은 거듭 일어나는 여러 가지 관계들이 문장들을 텍스트라는 큰 덩이글로 체제화함을 주시해 왔다. 표 2 에는 알려진 몇몇 관계가 정리되어 있다. 이 구성 관계는 문장이 전체 덩이글과 어떻게 관련되는지를 밝혀 준다. 예를 들면, 표에서 첫째 덩이 구조 (반응) 는 독자로 하여금 다른 문장들이 제기한 문제 해결의 일부로서 여러 문장들이 서로 관계되도록 한다. 이런 관계는 덩이글의 어느 수준에서든 일어난다. 즉, 한 단락을 구성하는 주된 관계가 표에 나와 있는 여덟 개 유형 중 어느 하나일 수 있다. 한 단락 내에서 하위 논점들도 이 관계들 중 어느 한 유형으로 체제화될 수 있다.
표 2 한 덩이글 내 문장들 간의 가능한 관계 유형.
|
관계 유형 |
한 주일 후 회상 |
|
1. 반응
2. 특수성 3. 설명 4. 증거 5. 연속 6. 원인 7. 목표 8. 집합
|
질문이 제시되고 답이 뒤따르거나, 또는 문제가 제시되고 해결이 뒤따른다. 좀더 일반적인 논점 뒤 어떤 특수한 정보가 제공된다. 논점에 관한 설명이 제공된다. 논점을 지지하기 위해 증거가 제공된다. 논점들이 일련의 세트로 순서대로 제시된다. 한 사건이 또 다른 사건의 원인으로 제시된다. 한 사건이 또 다른 사건의 목표로 제시된다. 논점들의 엉성한 구조가 제시된다 (이것은 실제로 체제화 관계가 없는 경우에 해당한다). |
표 3 의 관계들이 어떻게 사용되는지 보기 위해, 메이어 (Meyer, 1974) 가 다음 단락을 분석한 것을 보기로 하자 :
오늘날 시장에서 살 수 있는 다양한 색깔의 앵무새들은 연두색 몸과 노란색 얼굴의 앵무새들을 색깔 돌연 변이시켜 그 자손들을 세심하게 번식시켜 얻은 결과이다. 연한 연두색 몸과 노란 얼굴색의 조합은 원래 서식지인 호주 앵무새의 색깔이다. 자연주의자가 존 굴드 (John Gould) 가 1840 년에 처음으로 호주에서 유럽으로 살아 있는 앵무새를 가져왔다. 처음의 색깔 돌연 변이는 1872 년 벨기에에서 나타났으며 이 새들은 완전히 노랑이었다. 미국에서 가장 흔한 앵무새 색깔은 파랑색이다. 이 들은 파랑색 몸과 흰색 얼굴을 가지고 있으며, 이 색깔 돌연 변이는 1878 년 유럽에서 발생하였다. 호주산 앵무새 협회 색깔 및 기술 협의회가 정리한 앵무새의 색깔은 66 가지가 넘는다. 원래의 연두색 몸과 노란색 얼굴 이외에 보라, 파랑, 회색, 초록, 노랑 및 흰색 등 다양한 색깔의 앵무새들이 있다. (p. 61)
표 3 에는 이 단락을 대략 분석한 내용이 나와 있다. 이 분석은 여러 사실들을 주요 논점들로 체제화하고 있다. 이 단락에서 가장 높은 수준의 체제화 관계는 설명이다 (표 12.2에서 항목3). 특히, 이 설명에서 주요 논점은 (A) 색깔 돌연 변이를 세심하게 번식시켜 왔다는 것과 (B) 앵무새 색깔의 다양성이 매우 크다는 것이며, A 는 B 의 설명이다. A 에는 앵무새 번식의 역사를 통해 몇몇 사건들이 체제화 되어 있다. 이 체제화는 연속적 관계의 한 예이다.
표 3 앵무새 단락의 분석
|
1. A 는 B 를 설명한다. A.
초록색 몸과 노란색 얼굴의 앵무새는 세심한 색깔 돌연 변이를 통해
번식되었다. B.
오늘날 시장에는 다양한 색깔의 앵무새들이 있다. 이에 대한 증거는
다음과 같다. |
이 사건들 밑으로는 특정한 세부 내용들이 체제화된다.
그러므로, 예를 들면, A2 에서는 존 굴드가 자연주의자라는
사실이 체제화되어 있다. B 에서는 현재의 다양한 색깔과 그
변이의 세부 내용들에 관한 주장을 지지하는 증거가 체제화되어 있다.
| 큰 덩이글에서 명제들은 다양한 의미 관계에 따라 위계적으로 체제화될 수 있다. |
많은 연구들이 덩이글 구조의 심리적 중요성을 입증했다. 덩이글 분석에 정확히 어떤 관계 체계를 쓸 것인지에 관해 서로 다른 이론들이 제안되었으나, 그들은 위계 구조가 덩이글의 명제를 체제화한다는 데에는 동의한다. 기억 실험들은 피험자들이 그런 위계 구조에 어느 정도 반응한다는 증거를 보여 주었다.
메이어의 분석에서 예시된 위계 구조는 6 장에서 기억에 관해 공부한 위계 구조를 상기 시킨다. 거기서 인용된 자료로 미루어, 만일 피험자들이 이 위계들을 이해를 위해 쓰기만 하면 그런 위계들은 기억에 큰 효과를 줄 것이다. 메이어는 피험자들이 그런 구조에서 주요 논점 (구조상 상위 명제) 을 더 잘 기억함을 밝혔다. 예를 들면, 피험자들은 '색깔 돌연 변이를 이용한 세심한 번식' (A) 을 '존 굴드는 자연주의자였다' (A2a) 보다 더 잘 기억한다.
메이어 등 (Meyer, Brandt, & Bluth, 1978) 은 덩이글의 상위 구조, 즉 표 12. 3 에 있는 것처럼 위계상 상위 수준의 구조 관계에 관한 피험자들의 지각을 연구했다. 그들은 덩이글을 체제화하는 상위 수준의 구조를 재인하는 피험자들의 능력이 매우 다양함을 발견하였다. 더욱이, 피험자들의 상위 구조 파악 능력은 덩이글 기억의 주요 예언치였다. 9 학년들을 대상으로 이루어진 다른 연구에서, 바틀렛(Bartlett, 1978) 은 피험자의 11 퍼센트만이 덩이글 재료를 암기하기 위해 상위 구조를 의식적으로 파악해서 썼음을 발견하였다. 이러한 특수 집단의 회상 점수는 다른 학생들에 비해 두 배나 좋았다. 바틀렛은 학생들에게 상위 구조를 파악하여 쓰도록 훈련시켜 그들의 회상 점수를 두 배나 높게 만들었다.
위계 구조 이외에도, 덩이글은 인과 및 논리 구조로 체제화된다. 이것은 한 사건이 다음 사건을 야기시키는 식으로 순서가 있는 사건의 이야기 (narrative) 에서 가장 명확하다. 5 장에서 논의한 스크립트는 인과 관계를 약호화하기 위해 고안된 지식 구조이다. 인과 연쇄는 덩이글에서 명료하게 나타나지 않으므로 추리되어야 한다. 예를 들면, 뉴스 보도에서 다음과 같은 내용을 들을 수 있다 :
• 파크웨이 동쪽에서 사고가 났다. 차들은 윌킨스를 지나 다른 길로 가고 있다.
첫째 사실을 둘째 사실의 원인으로 추리하는 것은 청자에게 달렸다. 키넌 등은 둘째 문장을 처리할 때 두 문장 간을 인과 관계로 연결시키는 확률 효과를 다루었다. 그들은 피험자들에게 다음 문장 중 하나를 첫 문장으로 읽게 했다 :
1a. 조이의 큰형은 그를 때리고 또 때렸다.
1b. 언덕을 달려 내려가다가, 조이는 자전거에서 떨어졌다.
1c. 조이의 미친듯한 어머니가 그에게 사납게 화를 냈다.
1d. 조이는 이웃집에 놀러 갔다.
키넌 등은 첫 문장이 다음과 같은 두 번째 문장을 읽는 시간에 미치는 효과에 관심이 있었다 :
2. 다음 날, 그의 몸은 상처투성이였다.
문장 1a 로부터 1d 는 문장 2 와 연결될 확률이 점차 낮아지는 순서로 배열되어 있다. 이와 일치하여, 문장 2 를 읽는 시간이 1a 와 같이 높은 확률의 원인이 선행할 때는 2.6 초로 1d 와 같이 낮은 확률의 원인이 선행할 때는 3.3 초로 증가했다. 다소 먼 인과 관계를 형성할 때는 시간이 오래 걸린다.
인과 관계는 회상에도 영향을 미친다. 이야기 내용 중 인과 구조상 핵심적인 부분이 더 잘 회상된다. (Black & Bern, 1981 ; Trabasso, Secco, & van den Broek, 1984). 예를 들면, 블랙과 번은 피험자들에게 다음과 같은 문장 쌍을 포함하는 이야기를 읽게 했다 :
• 고양이가 식당 테이블 위로 뛰어올랐다.
• 프레드는 고양이를 집어서 밖으로 내보냈다.
이들은 인과적으로 관계된다. 그들은 이 쌍을 다음 쌍과 대비시켰다.
• 고양이가 식탁에 몸을 부벼댔다.
• 프레드는 고양이를 집어서 밖으로 내보냈다.
이들은 일시적으로만 관련된다. 둘째 문장이 두 경우에 모두 같지만, 피험자들은 인과적으로 관련된 쌍의 문장들을 더 잘 기억했다.
손다이크(Thorndyke, 1977) 도 덩이글의 체제화가 '자연스러운' 구조와 상반될 때 그 덩이글이 잘 기억되지 않음을 밝혔다. 어떤 피험자들은 원래의 이야기를 읽었고 다른 피험자들은 문장 순서가 뒤섞인 이야기를 읽었다. 피험자들은 원래 이야기에서 85 퍼센트의 사실을 회상했으나 뒤섞인 이야기에서 32 퍼센트의 사실을 호상했다. 이것은 7 장의 결과 (Bower 등의 1969년 실험) 를 보면 예언할 수 있다.
맨들러와 존슨(Mandler & Johnson, 1977) 은 이야기의 인과 구조 회상에서 아동들이 성인들에 비해 몹시 떨어짐을 보여 주었다. 성인들은 사건들과 그 결과 들을 함께 회상하지만, 아동들은 결과를 회상하기는 하지만 그것이 어떻게 얻어졌는지는 잊는 경향이 있다. 예를 들면, 아동들은 어떤 이야기에서 버터가 녹았다는 사실을 회상해 낼 수 있지만 그 버터가 햇빛에 있었기 때문에 그런 결과가 생긴 것은 잊는다. 성인들은 이러한 간단한 인과 구조는 잘 다루지만, 덩이글의 부분들을 연결시키는 복잡한 관계를 지각하는 데는 어려움을 겪을 수 있다. 예를 들면, 여러분이 얼마나 쉽게 이 단락과 선행 단락을 연결시키는 관계를 명세할 수 있을까?
팔린스카와 브라운(Palinscar & Brown, 1984) 은 아동들을
대상으로 덩이글의 인과 구조와 같은 것을 파악해서 질문을
만드는 훈련 프로그램을 개발했다. 그들은 27 퍼센트 수준의
낮은 수행을 보이는 7 학년생들의 읽기 이해력을 56 퍼센트
수준으로 끌어올렸다. 이것은 학생들에게 덩이글의 위계
구조를 파악하는 훈련을 통해 그들의 읽기 수행을 향상 시킨
바틀렛 (Bartlett, 1978) 의 결과를 상기시킨다.
| 덩이글 재료의 기억은 그 위계 및 인과 구조에 예민하며, 사람들이 그 구조에 주의하면 기억이 향상된다. |
킨치와 반 디엑 (Kintsch & van Dijk, 1978) 은 지금까지 논의된 여러 생각들을 개인이 덩이글을 어떻게 이해하고 기억하는지를 설명하는 정보 처리 모형으로 끌어들였다. 그들의 모형은 구조 분석 과정이 덩이글을 여러 명제로 분석하는 데 적용된다고 가정하며, 그들의 분석은 명제들이 처음 파악된 후에도 덩이글을 계속 처리하는 데 초점을 두고 있다. 간단한 예로서, 킨치 (Kintsch, 1979) 가 쓴 다음의 짧은 덩이글을 보자 :
스와지 (Swazi) 부족은 소떼 문제로 이웃 부족과 전쟁중에 있었다. 병사들 중에는 두 명의 미혼 남자 카크라 (kakra) 와 그의 남동생 검 (Gum) 이 있었다. 카크라는 전쟁에서 살해되었다. (p. 6)
이 덩이글은 다음 명제들로 분석된다 :
1. (이름, 부족 1, 스와지)
2. (이웃, 부족 2, 부족 1)
3. (전쟁중이다, 부족 1, 부족 2) = a
4. (원인, a, b)
5. (다투다, 부족 1, 부족 2, 소데) =b
6. (중에는, 병사들, 남자들)
7. (수, 남자, 둘)
8. (미혼, 남자)
9. (이름, 남자 [카크라, 검])
10. (남동생, 카크라, 검)
11. (살해되었다, 카크라, 전쟁)
킨치와 반 디엑 모형에 따르면, 명제가 처리될 때, 이해자들은 새 명제들을 옛 명제들과 관련지어야 한다. 이것은 어휘들을 중복시키면 가능하다. 따라서, 명제 2 는 명제 1 과 쉽게 관련되는데, 부족 1 이라는 말이 중복되기 때문이다. 문장 내에서 명제들을 관련시키기는 보통 쉽다. 문장 경계를 넘어서 명제들을 관련시켜야 할 때 어려워진다. 위의 예에서, 명제 6 은 선행 명제와 관련시키기가 어렵다. 명제들을 관련시키려면 이해자들은 교량적 추리 (bridging inference) 를 해야 한다 (Haviland & Clark, 1974). 이 경우 교량적 추리는 명제 6 에 있는 병사들이 스와지 부족 사람들이라는 것이다. 킨치와 반 디엑에 따르면, 이런 교량적 추리를 해야 하므로 이해가 어려워진다.
킨치와 반 디엑에 따르면, 개인이 작업 기억에서 활성화 상태로 유지할 수 있는 명제 수는 용량상 한계 (그들은 평균 넷으로 본다) 가 있다 (6 장 참조). 이 용량의 한계가 두 가지 중요한 결과를 초래한다. 하나는 새 명제와 옛 덩이글이 공유하고 있는 용어가 더 이상 활성화 상태에 있지 않기 때문에 이해자는 이 둘을 관련시키지 못한다는 것이다. 앞의 지시어 논의에서 지시적 표현을 처리할 때 지시 대상이 덩이글 뒤쪽에서 발생할 경우 시간이 더 오래 걸림을 보았다. 킨치와 반 디엑에 의하면, 이것은 복귀적 탐색으로서, 이 때 이해자들은 현재의 명제와 어휘상 중복된 명제를 장기기억으로부터 찾기 위하여 과거의 명제들을 재활성화 해야 하기 때문이다.
활성화될 수 있는 명제 수의 제한으로 생기는 두 번째 결과는 회상을 포함한다. 기억에 관한 이전 연구를 언급하면서 (6 장 참조), 킨치와 반 디엑은 어떤 명제가 오래 활성화 될수록 장기 기억에서 그 명제의 약호화 강도와 궁극적 회상 확률은 더 커진다고 주장했다. 그들은 선도적 우세 방략 (leading edge strategy) 을 제안하는데, 이 방략은 피험자로 하여금 가장 최근에 처리된 명제들과 덩이글의 위계적 표상에서 가장 상위 명제들을 활성화 상태로 유지하게 한다 (예 : 표 12. 3 참조). 따라서, 소떼 문제에 관한 명제 5 를 읽고 이를 활성화 상태로 유지하고, 명제 4 를 읽고도 이를 활성화 상태로 유지하면서 전쟁 명제와 관련시킨다. 최근에 플레처 (Fletcher, 1986) 는 읽기 과정에 관한 피험자들의 프로토콜을 검토하면서, 피험자들이 위계상 상위 명제들뿐만 아니라 인과적으로 중요한 명제들도 활성화 상태로 유지한다고 밝혔다. 이것은 덩이글 구조에서의 위치와 인과적 중심성 모두가 덩이글 처리에 중요하다는 앞의 증거와 일치된다. 중심 명제를 활성화 상태로 유지하는 방략 중 한 결과는 덩이글에서 위계적으로 그리고 인과적으로 중요한 사실들이 더 잘 회상된다는 킨치와 반 디엑 모형의 예언이다. 이 예언에 관한 증거는 앞의 하위 절에 개관되었다.
킨치와 반 디엑은 독자가 덩이글 명제를 윤색하는 데 두 종류의 정교화를 쓴다고 제안하였다. 하나는 이미 논의하였던 교량적 추리로서, 이해자는 추리가 아니면 무관했을 어휘들을 추가 추리를 통하여 관련시킨다. 다른 것은 킨치와 반 디엑이 대단위 명제(macropropositions) 라고 부르는 것으로서, 덩이글 요지의 요약이다. 그러므로, 예를 들면, 이 하위 절 처음에서 읽은 덩이글의 한 요약 명제는 한 군인이 전쟁에서 살해되었다는 것이다. 이 대단위 명제는 덩이글의 세부 내용보다는 주요 논지를 더 잘 회상하게 만든다.
킨치와 비폰드(Kintsch & Vipond, 1979) 는 이 분석을
1952 년 대통령 선거에서 아이젠하워와 스티븐슨의 연설에
재미있게 적용한다. 스티븐슨이 선거에서 패배한 이유는 그의
연설이 이해하기 어려웠기 때문이라는 주장이다. 그러나, 단어
길이, 단어 빈도 및 문장 길이와 같은 표준 읽기 측정치로
비교하면, 아이젠하워의 연설이 더 어렵다. 반면, 킨치와 반
디엑의 모형을 스티븐슨의 연설에 적용하면, 몇몇의 교량적
추리와 지시어를 결정하기 위한 복귀적 탐색이 요구되지만,
아이젠하워의 연설은 그렇지 않았다. 이는 청자들이
스티븐슨의 연설에서 지시어를 통합하는 것이 매우
부담스러웠음을 함축한다.
| 킨치와 반 디엑에 의하면, 이해자는 덩이글에서 한 번에 하나의 명제를 처리하면서, 새 명제들을 활성화 상태에 있는 선도적 우위 명제들과 연결시킨다. |
이 장에서 다룬 주제의 수와 다양성은 언어 이해 영역에서 엄청나게 축적된 발전을 증언해 준다. 인지심리학이 40 년 전 행동주의의 와해로부터 나타났을 때 언어 처리에 관해 아는 것이 전혀 없었다고 말하는 것이 옳을 것이다. 이제 단어를 들은 후 시간상 100 ms 로부터 복잡한 덩이글의 큰 연속으로의 통합에 이르는 범위까지 무슨 일이 발생하는지 어느 정도 명료한 그림을 그릴 수 있다. 언어 처리 분야에 몇몇의 이론적 쟁점이 있으며, 그 중 어떤 것들은 앞서 개관에서 논의되었다 (예 : 초기 언어 처리와 나머지 인지와의 독립성 여부). 이런 쟁점이 지금까지의 인상적인 발전을 무시하게 해서는 안 된다. 이 분야의 불시는 많은 빛을 발하였다.
크라크와 클라크 (Clark & Clark, 1977) 의 언어 처리에 관한 교재가 이제는 고전이다. 저스트와 카펜터 (Just & Carpenter, 1987) 는 읽기에 초점을 둔 언어 이해에 관한 최근 문헌들을 개관하였다. 싱어 (Singer, 1990), 그리고 테일러와 테일러 (Taylor & Taylor, 1990) 의 교재도 최근에 나왔다. 가필드 (Garfield, 1987) 는 언어 이해에서 단원성 쟁점을 다룬 논문들을 포함한다. 계산론적 언어학에서 몇몇 자연어 처리 이론이 제안되었다. 좋은 참고서로는 마커스 (Marcus, 1980). 버윅과 와인버그 (Berwick & Weinberg, 1984), 캐플란과 브레스넌 (Kaplan & Bresnan, 1982), 그리고 도우티 등 (Dowty, Kartunnen, & Zwicky, 1985) 이 있다.
블랙 (Black, 1984) 은 이야기 이해 연구를 개관한다. 킨치와 반 디엑 (Kintsch & van Dijk, 1978). 그리고 반 디엑과 킨치 (Kintsh & van Kintsch, 1983) 는 그들의 이론을 기술한다. 그러한 덩이글 구조의 적용이 세상 지식을 풍부하게 통합시키기에는 지나치게 통사적이며 형식적으로 잘 정의 되지 않았다는 비평을 받았다 (Black & Wilensky, 1979).