
��ȹ����
(Planning)
�ΰ�����-������ ������Ʈ�� �߽����� : Nils J.Nilsson ����, ���߹�. ������. �ɱ���. �庴Ź ����, �����ع̵��, 2000 (���� : Artificial Intelligence : A New Synthesis 1998), Page 405~434
1. STRIPS ��ȹ���� �ý��� (STRIPS Planning System)
(1) ���¿� ��ǥ�� ��� (Describing States and Goals)
(2) ������ Ž�� ��� (Forward Search Methods)
(3) ����� STRIPS (Recursive STRIPS)
(4) ����ð� ������ ������ ��ȹ (Plans with Run-Time Conditionals)
(5) ������ �̻� (The Sussman Anomaly)
(6) ������ Ž�� ��� (Backward Search Methods)
2. ��ȹ������ �κ� ���� ��ȹ���� (Plan Spaces and Partial-Order Planning)
3. ������ ��ȹ���� (Hierarchical Planning)
(2) ������ ��ȹ������ �κ� ���� ��ȹ������ ���� (Combining Hierarchical and Partial-Order Planning)
5. �������� �� ��� (Additional Readings and Discussion)
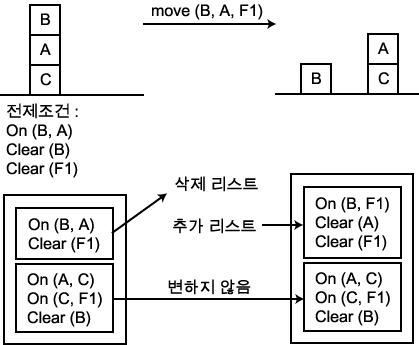
������ ������ �ذ��ϴ� ���� ��� ���� �ϳ��� ���°��� ���� ����� ��Ȳ������ ���� ����� ȥ���ϴ� ���̴�. 7 �忡�� Ư¡����� ���°����� ������ �� ������ ��ó�� �� ȥ���� �Ǽ��� ������ ������ ����ϴ� ��������� �� ��ü�� ������ �����̶�� ������ �Ѵ�. ���� ���, ���ϼ��迡�� �� 1 �� ���� �Ͱ� ���� ���� C ���� ���� A �� �ְ�, �ٽ� �� ���� ���� B �� ������ �Ǽ��� ���´� ������ ���� ����ȴ�.
On (B, A)
On
(A, C)
On (C, F1)
Clear (B)
Clear (F1)
�� 1 �ϳ��� ���� ���
�� ���� �Ǽ��� ������ �� ������ ����ϴµ�, �� ������ �� ���� �ǵ��ϴ� ���谡 ���� ��� ���¿� ���ؼ� ���� �����DZ� �����̴�. ���� �ٸ� ������ �����ϰ� �� ������ ���� ����� ���� �ٸ� Ư���� ������ ���� ���¸� ����� ��, �� ������ �����ϰ� ������ ������ ������ ��� ���¸� �����ؾ� �� ���̴�.
�� �忡�� ������ �����ϰ� �� �ʱ��� ��ȹ���� ��������� �Ǽ��� ������ ������ ����ϴ� ���� ������Ʈ�� �ൿ�� ���� ���� �� �ִ� �ڷ� ������ �����Ѵ�. ��ǥ�� �����ϴ� �Ǽ��� ������ ������ ����ϴ� �ϳ��� �ڷ� ������ ã�� ����, �� �ڷ� ������ ������ Ž���ϱ� ���� ����� ����� ���̴�. �� �ڷ� ������ ���� ���� ���� Ž���� �� ���, �� �ڷ� ������ ��ȹ���� ������ ���°� �ȴ�. ��ȹ������ ���� ���¿� �Ǽ��� ���¸� �����ϱ� ���� ������ ���ڸ� ���� ��� (state description) �̶�� �� ���̴�.
������ �� �ʿ䰡 ����
��� ������� ������� ���ϱ� ����, �ൿ �� ���� ��� (before-action state description)
�� �ൿ �� ���� ��� (after-action state description) ��θ� ���� ���ͷ� (ground
literal) �� ������ (�Ǵ� ����) ���� �����Ѵ�. ������ �� ���� ���ܰ� ���Ǵµ�,
���� ����� ��� ���¿��� ���� �Ǵ� ������ �� (���� ���, On (x, y) �� (y =
F1) �� ��Clear (y)) �� ������ �� �ִٴ� ���̴�. ��ǥ�� ���ͷ��� ������ (����
�����簡 ���� �� ����) ���� �����Ѵ�. ������ 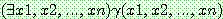 ������ ��ǥ wff �� ������
������ ��ǥ wff �� ������ 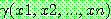 ���� ���� ��� ������ ���� ���� (existential quantification) �� �Ǿ� �ִٰ�
�����Ѵ�. ���� ���� ���� ����� �̿��ؼ� �̷��� ������ ���� ���� ���� ������,
������ �Ѵ� �ϴ��� ��̷ο� ��ȹ ���� �������� ���� �ذ��� �� �ִ�.
���� ���� ��� ������ ���� ���� (existential quantification) �� �Ǿ� �ִٰ�
�����Ѵ�. ���� ���� ���� ����� �̿��ؼ� �̷��� ������ ���� ���� ���� ������,
������ �Ѵ� �ϴ��� ��̷ο� ��ȹ ���� �������� ���� �ذ��� �� �ִ�.
�־��� ��ǥ wff 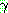 �� ���� Ž�� ���������
�� ���� Ž�� ���������  �� �����ϴ� ���� ��� �� ǥ���Ǵ� �Ǽ��� ���¸� �����ϴ� �Ϸ��� �ൿ��
������ �Ѵ�. �̶� ���� ����� ��ǥ�� ������Ų�� (satisfy) �� �Ѵ�. ���ѵ� ���¿�
��ǥ wff �� ���Ͽ�
�� �����ϴ� ���� ��� �� ǥ���Ǵ� �Ǽ��� ���¸� �����ϴ� �Ϸ��� �ൿ��
������ �Ѵ�. �̶� ���� ����� ��ǥ�� ������Ų�� (satisfy) �� �Ѵ�. ���ѵ� ���¿�
��ǥ wff �� ���Ͽ�  �� �����ϴ� ���� ġȯ �� �� �����Ͽ�
�� �����ϴ� ���� ġȯ �� �� �����Ͽ�  ��
�� 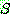 �� ��Ÿ���� ��� ���ʸ��ͷ��� �������� �� ���̴�.
�� ��Ÿ���� ��� ���ʸ��ͷ��� �������� �� ���̴�.  �� �����ϴ��� �ƴ����� �����Ϸ��� ����
�� �����ϴ��� �ƴ����� �����Ϸ��� ���� 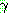 �� ó�� ���ͷ���
�� ó�� ���ͷ��� 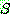 �� ���ͷ��� ����ȭ ��Ű�� (unify), ���⼭ ������ ����ȭ ġȯ (unifying
substitution) ��
�� ���ͷ��� ����ȭ ��Ű�� (unify), ���⼭ ������ ����ȭ ġȯ (unifying
substitution) �� 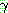 �� ������ ���ͷ��� �����Ų ������ �ϸ� �ȴ� (�� ������ PROLOG �ؼ��
�� (cluse) �� ��ü (body) �� ��� (fact) �� ����ȭ�� �� �ִ��� �Ųٷ� ��ǥ����
�����ϴ� ������ Ž�� (forward search) �Ųٷ� ��ǥ���� �����Ͽ� �ʱ� ���·� ����Ǵ�
������� (backward search) �� �ִ�. � ���ڵ��� ������ Ž���� ���� ��ȹ����
(progression planning) �̶� �ϰ� ������ Ž���� ȸ�Ͱ�ȹ ���� (regression planning)
�̶�� �Ѵ�. ������ Ž���� ���ؼ� ���� �����ϰ��� �Ѵ�.
�� ������ ���ͷ��� �����Ų ������ �ϸ� �ȴ� (�� ������ PROLOG �ؼ��
�� (cluse) �� ��ü (body) �� ��� (fact) �� ����ȭ�� �� �ִ��� �Ųٷ� ��ǥ����
�����ϴ� ������ Ž�� (forward search) �Ųٷ� ��ǥ���� �����Ͽ� �ʱ� ���·� ����Ǵ�
������� (backward search) �� �ִ�. � ���ڵ��� ������ Ž���� ���� ��ȹ����
(progression planning) �̶� �ϰ� ������ Ž���� ȸ�Ͱ�ȹ ���� (regression planning)
�̶�� �Ѵ�. ������ Ž���� ���ؼ� ���� �����ϰ��� �Ѵ�.
���� ����� ������
���ؼ� �������� Ž���� �ϱ� ���ؼ��� �ൿ�� �����ϴ� ������ (operator) �� �ʿ��ѵ�
�� �����ڴ� �ൿ �� ���� ����� �ൿ �� ���� ����� �ٲ۴�. �� Ž���� ��ǥ wff
��  �� ���Ͽ�
�� ���Ͽ�  �� �����ϴ� ���� ���
�� �����ϴ� ���� ���  �� �����ϸ� ���������� ������ �ȴ�. �� �����ڵ��� (STRIPS [Fikes &
Nilsson 1971, Kikes, Hart & Nilsson 1972] �� �Ҹ��� �ý����� �����ڿ� �����
�д�. STRIPS �����ڴ� ������ ���� �� �κ����� �����ȴ�.
�� �����ϸ� ���������� ������ �ȴ�. �� �����ڵ��� (STRIPS [Fikes &
Nilsson 1971, Kikes, Hart & Nilsson 1972] �� �Ҹ��� �ý����� �����ڿ� �����
�д�. STRIPS �����ڴ� ������ ���� �� �κ����� �����ȴ�.
1. �������� �������� (precondition) ���� �Ҹ��� ���� ���ͷ��� ���� PC. �����ڿ� �����Ǵ� �ൿ�� PC �� �ִ� ��� ���ͷ��� �ൿ �� ���� ������� �ִ� �� ���¿����� ����� �� �ִ�.
2. ���� ����Ʈ (delete list) �� �Ҹ��� ���� ���ͷ��� ���� D.
3. �߰� ����Ʈ (add list) �� �Ҹ��� ���� ���ͷ��� ���� A.
�ൿ �� ���� ����� �����ϱ� ���ؼ��� ���� �ൿ �� ���� ������� D �� �ִ� ���ͷ��� �����ϰ� A �� �ִ� ���ͷ��� �߰��Ѵ�. D ���� ����� ���� ��� ���ͷ��� �ൿ �� ���� ����� �̿��ȴ�. �� �̿� (carryover) �� STRIPS ���� (STRIPS assumption) �̶�� �θ��� ������ ������ �ذ��ϴ� �� ���� ����� �ȴ�.
STRIPS �����ڴ� �밳 �ൿ ��Ű���� �����Ǵ� ��Ű���� ���� ���ǵȴ�. STRIPS ��Ģ (STRIPS rule) �̶� �Ҹ��� ������ ��Ű���� ���������� ������, �� ��Ģ�� ���� ��� (ground instance) �� ���� �����ڿ� �����ȴ�. �������� x, y, z �� ������ STRIPS ��Ģ�� �� ���� ��� ������ ����.
move (x, y, z)
PC
: On (x, y) �� Clear (x) �� Clear (z)
D : Clear (z), On (x, y)
A :
On (x, z), Clear (y), Clear (F1)
(���⼭ Clear (F1) �� ���� �߰� ����Ʈ�� ���������� ���Խ��״µ�, �̰��� ���� z �� F1 �̶�� Clear (F1) �� �����ǹǷ� Clear (F1) �� �� ���̷��� �װ��� �߰� ����Ʈ�� �־�� �ϱ� �����̴�). ���� B �� ���� A ���� �ٴ� (floor) ���� �ű�� �ൿ�� ���� �� STRIPS ��Ģ�� �� ��ʸ� �� 2 ���� �����ְ� �ִ�.
STRIPS ��Ģ ��ü��
���������� ��ǥ�� ǥ���ϴ� ����, �� ���ͷ��� �������� ���¸� �����ٴ� �Ϳ� ������
�ʿ䰡 �ִ�. PC �� ��ǥ wff �� �ؼ��� ��, PC �� �ִ� ���������� ���� �����Ǿ�
�ִٰ� �����Ѵ�. PC �� �� ���� ��� (��ǥ�� ���ֵǴ�) �� � ���� ����� ����
�����ȴٸ� STRIPS ��Ģ�� �� ��ʸ� �� ���� ���  �� ������ �� �ִ�. ���� ����Ѵ��, �̷��� ��ʴ� PC �� �ִ� �� ���ͷ���
���±���� �ִ� ���ͷ��� ���ʴ�� ����ȭ���� ���� �� �ִµ�, �̶� ����ȭ ġȯ��
PC �� ������ ���ͷ��� �����Ų��. ���� ����, ���� ������ ������ ��� (applicable
operator instance) �� �� ������ ����� ����� ġȯ�� STRIPS ��Ģ�� ��� ��ҿ�
�����Ͽ� ���� �� �ִ�. ��Ģ�� �̷��� ġȯ�� �����Ͽ� �� ����� �� �� ��Ģ��
���� ��ʰ� �ǵ��� �ۼ��Ǿ�� �Ѵ�. ��, D �� A ���� PC �� ��Ÿ���� �ʴ� ����������
���� �� ����. �� 2 ���� STRIPS �������� ������ �����ϰ� �ִ�.
�� ������ �� �ִ�. ���� ����Ѵ��, �̷��� ��ʴ� PC �� �ִ� �� ���ͷ���
���±���� �ִ� ���ͷ��� ���ʴ�� ����ȭ���� ���� �� �ִµ�, �̶� ����ȭ ġȯ��
PC �� ������ ���ͷ��� �����Ų��. ���� ����, ���� ������ ������ ��� (applicable
operator instance) �� �� ������ ����� ����� ġȯ�� STRIPS ��Ģ�� ��� ��ҿ�
�����Ͽ� ���� �� �ִ�. ��Ģ�� �̷��� ġȯ�� �����Ͽ� �� ����� �� �� ��Ģ��
���� ��ʰ� �ǵ��� �ۼ��Ǿ�� �Ѵ�. ��, D �� A ���� PC �� ��Ÿ���� �ʴ� ����������
���� �� ����. �� 2 ���� STRIPS �������� ������ �����ϰ� �ִ�.
�� 2 STRIPS ������

�� 3 ������ Ž��
������ Ž�� ���������
STRIPS ��Ģ�� ��ʸ� ��ǥ wff �� ������Ű�� ���� ����� ����� ������ �����Ͽ�
���ο� ���� ����� �����Ѵ�. �� 3 �� ������ Ž���� ���� ������ Ž�� ������
�Ϻθ� ��Ÿ������. ���� ����� �ִ� ��κ��� ���ͷ��� STRIPS �����ڸ� ������ѵ�
������ �ʱ� ������ ��ȭ�� �� �����Ѵٸ� ������ Ž���� ���������� ������ ��
�ִ� (��ǥ ���±����� ����� �����ϴ� ������ 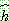 �� �ൿ�� ����� �ݿ��ϴ� ������
�� �ൿ�� ����� �ݿ��ϴ� ������ 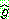 �� �̿��Ͽ� A* Ž���� ����� ���� �ִ�). ��Ȳ ������ ���ϸ�
�ൿ�� ������ �Ŀ��� � ����� ������ �ʴ´ٴ� ���� ������ �ʿ䰡 ���ٴ� �Ϳ�
�����ؾ� �Ѵ�. STRIPS ������ �̰��� ó���� �ش�.
�� �̿��Ͽ� A* Ž���� ����� ���� �ִ�). ��Ȳ ������ ���ϸ�
�ൿ�� ������ �Ŀ��� � ����� ������ �ʴ´ٴ� ���� ������ �ʿ䰡 ���ٴ� �Ϳ�
�����ؾ� �Ѵ�. STRIPS ������ �̰��� ó���� �ش�.
� ��Ģ�� � ��ʸ� �����ؾ� �ϴ����� ���� ����ƽ�� ���ٸ� ������ Ž���� ���� ����� ��Ģ�� ���ڰ� ���� ���� ���뿡���� ���������̴�. ������ Ž���� ���� ȿ�������� ����� �� ���� ����� ��ǥ ���� ����� ���� Ž���� ������ ���� �� �ִ� Ž�������� �� (islands) �� �����س��� ���̴�. ���� ������ ���� �����ϰ� Ȱ���ϱ� ���� ����� ����Ѵ�.
�츮�� ���⼭ �����ϴ� �Ͱ� ���� ��ǥ������ ���ͷ��� ���������� �����Ǿ��� ���� �������� (divide-and-conquer) ����ƽ�� �̿��Ͽ� ������ Ž���� �� �� �ִ�. ����, ������ ���� (conjunct) ���� �ϳ��� �ذ��ϰ�, �� ������ �ٸ� ������ ���ڸ� �ϳ��� ��� �ذ��Ѵ�. ������ ���� �� �ϳ��� ������ ���� ����� Ž�������� �ϳ��� �� (island) �� ��Ÿ����. �켱������ �� ���� �������� �۾��� �����ϴµ�, �����Ǵ� ������ ���ڰ� �����Ǵ� ���� ����� �����ϴ� �����ڸ� �����Ų��. ���� ����, �� �ٸ� ���� ���� �۾��� �����ϰ�, �̷��� ������ ����Ѵ�. ���� ���߿� ���� ������ ���ڿ� ���� ���� ���� ������ ���ڰ� öȸ�� (disachieved) ���� �ִ�.
AI ���翡�� �ʱ
���ߵ� ���� ���� �ذ��� (General Problem Solver, GPS) �� �Ҹ��� �ý��� [Newell,
Shaw, & Simon 1959, Newell & Simon 1963] ���� �̷��� ������� Ž������
���� Ȱ���Ͽ���. �� ���� ���ϴ� �����ڴ� "���� ��ǥ �м�" (means-ends
analysis) �̶� �Ҹ��� ������ ���� �ĺ��ȴ�. STRIPS ��Ģ�� �̿��� ��ȹ���� �ý��ۿ�
����Ǵ� �Ͱ� ���� �� ����� ��ǥ���ǿ� �ִ� ������ ���ڵ��� �� ��ʸ� �����ϰ�,
���� �װ��� ���ϰ� �� STRIPS ��Ģ�� �� ��ʸ� �����ϰ� �ȴ�. ���� ����,
�� ��Ģ�� �����ϴ� �� �ʿ��� ���������� �θ�ǥ (subgoal) �� �����ϰ�, �� �θ�ǥ��
������ ������ ���� �� �ĺ� ����� �̿��Ͽ� ��������� (recursively) �۾��� �����Ѵ�.
���� ����, ���� ���� ����� �����ϴ� �����ڸ� �����Ű�� �� �ٸ� ���� �ĺ��ϰ�,
�̷� ������ ��� �����Ѵ�. �� ���ν����� STRIPS �� �Ҹ��� ����� ���α���
���ʰ� �ȴ�. STRIPS �� ������ ��ǥ���� 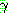 �� ������ ���� �ذ��Ѵ�.
�� ������ ���� �ذ��Ѵ�.
STRIPS (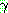 ). �� ���ν����� ���� ���ͷ��� �������� ������ ���� (global) �ڷ� ������
). �� ���ν����� ���� ���ͷ��� �������� ������ ���� (global) �ڷ� ������
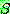 �� �̿��Ѵ�. �� �ڷ� ������ �ʱ� ���� ����� �ʱ�ȭ�ǰ� ���ν�����
����, ���� ���ν��� ���߿� ����ȴ�.
�� �̿��Ѵ�. �� �ڷ� ������ �ʱ� ���� ����� �ʱ�ȭ�ǰ� ���ν�����
����, ���� ���ν��� ���߿� ����ȴ�.
1.
repeat STRIPS �� �ַ����� ��ǥ 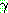 �� ������Ű�� ���� ����� ������ ������ �ݺ��ȴ�. 9 �� �ܰ��� ���� �˻翡
�� ������Ű�� ���� ����� ������ ������ �ݺ��ȴ�. 9 �� �ܰ��� ���� �˻翡
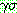 �� ������ ���� �� �Ϻ� (���� ���� ����) ��
�� ������ ���� �� �Ϻ� (���� ���� ����) �� 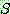 �� ��Ÿ���� ġȯ
�� ��Ÿ���� ġȯ  [��ġȯ (empty substitution) �� ���� ����] �� �����ȴ�. �˻縦 ������ ��
���� ġȯ�� �õ��� �� ������, ���� �� �˻簡 �ϳ��� �������� (backtracking
point) �� �� �� �ִ�.
[��ġȯ (empty substitution) �� ���� ����] �� �����ȴ�. �˻縦 ������ ��
���� ġȯ�� �õ��� �� ������, ���� �� �˻簡 �ϳ��� �������� (backtracking
point) �� �� �� �ִ�.
2.
 �� �����ϴ�
�� �����ϴ�  �� �� ���. �� �ٸ� �����̸� ���� ���������� �ȴ�. "���� ��ǥ �м�"
�� �� ������
�� �� ���. �� �ٸ� �����̸� ���� ���������� �ȴ�. "���� ��ǥ �м�"
�� �� ������  �� ��ǥ�� ���ϱ� ���� "�ٿ���" (reduce) �ϴ� ���� (difference)
�� ���ֵȴ�.
�� ��ǥ�� ���ϱ� ���� "�ٿ���" (reduce) �ϴ� ���� (difference)
�� ���ֵȴ�.
3.
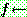 ���ͷ� �� �� �����ϴ� �߰� ����Ʈ�� ���� STRIPS ��Ģ. �̶� �� �� mgu
���ͷ� �� �� �����ϴ� �߰� ����Ʈ�� ���� STRIPS ��Ģ. �̶� �� �� mgu 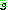 �� ����
�� ���� 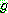 �� ����ȭ�ȴ�. �̷��� ��Ģ�� ���� ���� ���� �� �ֱ� ������ �� �ٸ�
���������� �ȴ�.
�� ����ȭ�ȴ�. �̷��� ��Ģ�� ���� ���� ���� �� �ֱ� ������ �� �ٸ�
���������� �ȴ�. 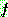 �� ���̸� ���̴� �� ���� (relevant) �� �������̴�.
�� ���̸� ���̴� �� ���� (relevant) �� �������̴�.
4.
 . ġȯ
. ġȯ 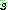 �� �̿���
�� �̿��� 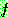 �� ����̴�.
�� ����̴�. 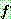 �� ���� ����� �ʿ�� ������, ���� ���������� ������ ���� �� �ִ�.
�� ���� ����� �ʿ�� ������, ���� ���������� ������ ���� �� �ִ�.
5.
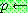 (ġȯ
(ġȯ 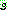 �� ���ȭ��)
�� ���ȭ��) 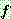 �� �������ǽ�.
�� �������ǽ�.
6.
STRIPS (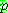 ). �θ�ǥ�� ������Ű�� ���� ����� �����ϴ� ��� ȣ��. �� ȣ���� �̷������
�Ϲ�������
). �θ�ǥ�� ������Ű�� ���� ����� �����ϴ� ��� ȣ��. �� ȣ���� �̷������
�Ϲ������� 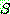 �� ����ȴ�.
�� ����ȴ�.
7.
 ���� �����ų �� �ִ�
���� �����ų �� �ִ� 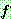 �� ���� ���.
�� ���� ���.
8.
 ��
�� 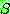 �� �����Ų ���.
�� �����Ų ���. 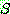 �� �� ���ʸ��ͷ��� ���������� �����ȴ�.
�� �� ���ʸ��ͷ��� ���������� �����ȴ�.
9.
until 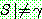 .
.
9 �� �ܰ迡���� ��
��ü ��ǥ�� 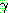 �� ���Ͽ� �˻縦 �����Ѵ�. ����
�� ���Ͽ� �˻縦 �����Ѵ�. ���� 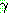 �� ������ ���� �� �ϳ��� �ٸ� ������ ���ڸ� ������Ű�� �������� öȸ�Ǹ�,
�� ������ ����DZ� ���� ù° ���ڸ� �ٽ� �������Ѿ� �ϰų� ù° ���ڰ� öȸ����
�ʴ� �ٸ� ��θ� �������ؾ� �Ѵ�.
�� ������ ���� �� �ϳ��� �ٸ� ������ ���ڸ� ������Ű�� �������� öȸ�Ǹ�,
�� ������ ����DZ� ���� ù° ���ڸ� �ٽ� �������Ѿ� �ϰų� ù° ���ڰ� öȸ����
�ʴ� �ٸ� ��θ� �������ؾ� �Ѵ�.
�� �˰����� ������� ���������� ��������� �ʾ����� ��ȹ�� �����ϴ� �Ϸ��� ��ǥ �� �����ڴ� ���������� ����� �˰������� ���� (trace) �Ͽ� ������ �� �ִ�. �̵��� �ٽ� ������Ʈ�� ������ �� �ִ� �ൿ�� �����Ǵµ�, �ܹ��� (ballistically) ����ǰų�, ����/��ȹ/�ൿ �ֱ⸦ ������ ����ȴ�.
�˰������� ���
�۵��ϴ����� ���� ������ ���� �����ϰ��� �Ѵ�. ���� �ʱ �� 1 ���� ���õ�
�Ͱ� ���� ��Ȳ�� ���ؼ� On(A, F1) �� On (B, F1) �� On (C, B) �� ��ǥ�� ���Ϸ�
�Ѵٰ� ����. 9 �� �ܰ��� ��ǥ �˻翡���� � ������ ���ڰ� �ʱ� ���� �����
���� �����Ǵ��� ���� ���Ѵ�. ���� STRIPS �� On (A, F1) �� 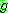 �� �����Ѵٰ� ��������. ��Ģ ��� move (A, x, F1) �� �߰� ����Ʈ�� On (A,
F1) �� ������ ������, ���� ��Ģ�� ���������� Clear (A) �� Clear (F1) �� On
(A, x) �� ���ϱ� ���� STRIPS �� ��������� ȣ���Ѵ�. ����� ȣ���� 9 �� �ܰ���
�˻翡�� C/x �� ġȯ�� �����ϴµ�, �� ġȯ�� Clear (A) �� ������ ������ ���ڸ�
�ʱ� ���¿� ���� ������Ų��. �� Clear (A) ���ͷ��� ���õǰ�, ��Ģ ��� move
(y, A, u) �� �̰��� ���ϱ� ���� ���õȴ�.
�� �����Ѵٰ� ��������. ��Ģ ��� move (A, x, F1) �� �߰� ����Ʈ�� On (A,
F1) �� ������ ������, ���� ��Ģ�� ���������� Clear (A) �� Clear (F1) �� On
(A, x) �� ���ϱ� ���� STRIPS �� ��������� ȣ���Ѵ�. ����� ȣ���� 9 �� �ܰ���
�˻翡�� C/x �� ġȯ�� �����ϴµ�, �� ġȯ�� Clear (A) �� ������ ������ ���ڸ�
�ʱ� ���¿� ���� ������Ų��. �� Clear (A) ���ͷ��� ���õǰ�, ��Ģ ��� move
(y, A, u) �� �̰��� ���ϱ� ���� ���õȴ�.
�ٽ� �� ��Ģ�� ���������� Clear (y) �� Clear (u) �� On (y, A) �� ���ϱ� ���� STRIPS �� ��������� ȣ���Ѵ�. �� �ι�° ��� ȣ���� 9 �� �ܰ迡���� B/y, F1/u �� ġȯ�� �����Ͽ� ���������� �� ���ͷ��� �ʱ� ���¿� ��Ÿ���� ���ͷ��� ����� �ش�. ���� �� �ι�° ����� ȣ��� �������ͼ� move (B, A, F1) �� �����ڸ� ������� �ʱ� ���¸� �������� �����Ų��.
On (B, F1)
On
(A, C)
On (C, F1)
Clear (A)
Clear (B)
Clear (F1)
���� ù��° ��� ȣ��� ���ư��� 9 �� �ܰ��� �˻� (��, Clear (A) �� Clear (F1) �� On (A, x)) �� �ٽ� �����Ѵ�. �� �˻�� C/x �� ġȯ�� ���� ����� ���� ����� ���� �����Ǹ�, ���� ù° ��� ȣ��� �������� move (A, C, F1) �����ڸ� ������� ������ ���� ����° ���� ����� �����Ѵ�.
On (B, F1)
On
(A, F1)
On (C, F1)
Clear (A)
Clear (B)
Clear (C)
Clear (F1)
���� �ٽ� �����α��� 9 �� �ܰ��� �˻縦 �����Ѵ�. ���� ��ǥ���� ���ο� ���� ����� ��Ÿ���� ���� ������ ���ڴ� On (C, B) ���̴�. �����α��� �ٽ� ��������� �����ϸ� move (C, F1, B) �� ���������� �̹� �����Ǿ��� ������ �̰��� ������� �ָ�ǥ�� ������Ű�� ���� ����� ������ �� �ְ�, ���� ��� ������ ����ȴ�.
���� ���� (perceptual process) �� ���� ��ȹ ���� ���ȿ� ���� ����� �ٵ��� �� �ִٸ� ���� ������� ����ϴ� ���� ������ �ణ �Ϲ�ȭ�� �� �ִ�. ���� ����Ŀ� ���ͷ��� �������� ����ϸ� ��� �Ǵ��� ������ ����. ��ü������ ���ϸ�, ���� �� ���� ����� On (B, A) �� On (B, C) �� wff �� �����ٰ� ��������. �� wff �� B �� A ���� �ְų� ���� B �� C ���� �ִٴ� ���� �ǹ������� �ý����� ��ȹ�� �����Ǵ� ���������� �� �� ��� ���� �´��� ���� ���Ѵ�. �̿� ���� ���� ����� ����� �� �ִ� STRIPS �����ڿ� �� �������� ����� On (B, A) �� On (B, C) �� ��� ���� �����Ǵ����� ���������� �ʴ´�. �̵� �����ڿ� ���ؼ� ���� ����� �������� �ִ� ���� ������ ���� ������, �� �������� �ൿ �� ���� ����� �ٷ� ���ȴ�.
������ � �����ڴ� On (B, A) �� On (B, C) ���� �ϳ��� ������������ ���� �� �ִ�. �̷� �����ڿ� �����ϴ� �ൿ�� �����ϱ� ���ؼ��� �� �ൿ�� ����� �� (��, ����ð���) � ������ ���ڰ� �����Ǵ����� �ý����� �˾ƾ� �Ѵ�. �Ƹ��� ������������ �̿� ���� ������ �� �� ���� ���̴�. ���� ���ٸ�, �����ڸ� �����ϴ� �������� ��ȹ�� ����ð� ���� (run-time conditional) �� ������ �� �ִ�. ����ð� ���� ���� ��ȹ�� ���� ���� ��ȹ���� ������ ������ ���������� ������ų �� �ִ� ������ ������ ����ŭ�� ���� (branch) �� �ɰ�����. �� ������ ������ ���� ����� �����ڸ� ������. ���� �������� ���� �� ���������� ������ �ൿ�� ����Ǿ��� ���� �Ǽ��迡�� On (B, A) �� ���� �ȴ� (�Ǵ� ���� �� ���̴�) �� �����ϰ�, �ٸ� ���������� On (B, C) �� ���� �ȴ� (�Ǵ� ���� �� ���̴�) �� �����Ѵ�. �� ������ ���� (context) �̶� �θ���. ��ȹ�����ÿ��� ������ ������ ������ �Ǽ��� ���¸� �����ϴ� ���±���� ��� ������ ���� �������� �� �� �ϳ��� ���� ��Ȯ�ϴ�. �� ���ƿ� ���� ������ ��ȹ�� �����ȴ�. ���� ����, ����ÿ� �ý����� �� �̻��� �������� ���������� ��Ȳ�� ������ ����, ���� �������� ��� ������ ���ڰ� ���ܸ� �����ϰ� ������ ������ ��θ� ���� ����ȴ�. ������ ���������� ���� ���� �б� ������ ���� �� �ִ�.
���δ� ���� �ൿ�� ����� ���� ���� �������� �Ǽ����� ��� ������ ���ڰ� �������� �ʿ��� �� ������ �� �ִ�. �� �Ϲ������δ� �ý����� �������� �ൿ (information-gathering action) �� �����ϴ� �����ڸ� ����Ͽ� �� ������ ��� ���� ��ȹ�� ������ �Ѵ�. ���� �������� On (B, A) �� On (B, C) �� ��� ���� ������ �����ϱ� ���ؼ��� �ý����� ���� ���� ���ڸ� ���� �� �ִ� �ൿ�� �����ؾ� �� ���̴�. �� �ൿ�� STRIPS �����ڿ� ���� ����� �� �ִµ� �� �������� ����� "know-which" �� �����ϴ� ������ ����� �����Ѵ�. ����ð� ������ ���� �� know which �� ������������ ������ �ȴ�.
�� 4 �� �ִ� ���ϼ��� ������ ���� ����� STRIPS �� ������ ����. ��ǥ������ On (A, B) �� On (B, C) �̴�. STRIPS �� �� ������ ���� �� �ϳ��� ���� �������Ѿ� �Ѵ�. ���� On (A, B) �� ���õǾ��ٰ� ����. ���� C �� A ���� �и����� �ٴڿ� ���´�. ���� ���� A �� B ���� �ű��. ������ �ٸ� ������ ������ On (B, C) �� ������Ű��� �������� On (A, B) �� �����·� �ǵ����� (undo) ������ �̸� �ٽ� �������Ѿ� �Ѵ�. ���� On (B, C) �� ���� ���õǾ��ٰ� ����. �� ���� B �� C ���� �ű�� ������ �ٸ� ������ ������ On (A, B) �� ������Ű�� �������� On (B, C) �� �����·� �ǵ����� �ǰ� ���� �ٽ� �������Ѿ� �Ѵ�. ����, ��� ���� ���� �����Ѵٰ� �ص� �������� ���� �ּҷ� ������ ��ȹ�� ������ ���Ѵ�. �̷��� Ư���� ���� ���� ������ ������ ����� �̸��� ���� ������ �̻� (Sussman anomaly) �̶�� �Ѵ� [Sussman 1975].
�� ������ ����� STRIPS �� Ǯ�� ����� ������ ���̿켱 (depth-first) Ž�� ���ó�� �ѹ��� �ϳ��� ������ ���ڿ��� �����ϱ� �����̴�. ���� ������ Ž���� �ʺ�켱 (breadth-first) ������ ����Ѵٸ� �ִ��� ��ȹ�� ã�� �� �ִ�. ������ �տ��� ������ �ٿ� ���� �ʺ�켱 ������ Ž���� ���� ��Ȳ������ �ſ� ���� ����� �䱸�ϱ� ������ ���� �Ұ����ϴ�.
�ϳ��� ������δ� �ʺ�켱�� ������ Ž���� �õ��� ���� ���̴�. �� ����� �������� ������ Ž���� ���� ȿ�����ε� �ֳ��ϸ� �Ϲ������� �ʱ� ���� ����� �ִ� ���� ���ͷ��� ������ ��ǥ wff �� �ִ� ������ ������ ���� ���� �����̴�. ���� ������ ������ Ž���� ���� �ٷ���� �Ѵ�.

�� 4 ������ �̻�
STRIPS ��Ģ�� �̿��Ͽ�
��ǥ ���·κ��� ������ Ž���� �� �� �ִ�. �̸� ���ؼ��� STRIPS ��Ģ�� ���� ��ǥ
wff �� ȸ�ͽ��� (regress) �θ�ǥ (subgoal) wff �� �����ؾ� �Ѵ�. STRIPS ��Ģ
�� �� ���� �� 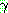 �� ȸ�� (regression) �� ������ ������Ű�� ���� ���� �� (weakest formula)
�� ȸ�� (regression) �� ������ ������Ű�� ���� ���� �� (weakest formula)
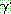 �� �ȴ�. ��, ����
�� �ȴ�. ��, ���� 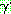 �� �� �� ��ʸ� �����Ű�� ���� � ���� ����� ���� �����Ǹ� (����
�� �� �� ��ʸ� �����Ű�� ���� � ���� ����� ���� �����Ǹ� (���� 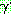 �� �� �� ����� ���������� ������Ű��),
�� �� �� ����� ���������� ������Ű��), 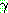 �� �� �� ��ʸ� �����Ų �Ŀ��� �� ���� ����� ���� �����ȴ� (
�� �� �� ��ʸ� �����Ų �Ŀ��� �� ���� ����� ���� �����ȴ� ( �� ���
�� ���  ��
��  ���� �� ���ϴٰ� �Ѵ�. ���� ��� P �� Q �� P ���� ���ϰ�, P �� P�� Q ����
���ϴ�).
���� �� ���ϴٰ� �Ѵ�. ���� ��� P �� Q �� P ���� ���ϰ�, P �� P�� Q ����
���ϴ�).

�� 5 STRIPS �����ڸ� ���� �������� ȸ��
ȸ�� ����� ���� ���ͷ��� ���������� �� ��ǥ���� ����Ͽ� STRIPS ������ (STRIPS ��Ģ�� ���� ���) �� ���ؼ��� ȸ���ϰ� �ȴٸ� �ſ� �����ϴ�. �� ��� ��� ȸ�͵� ���� ���ͷ��� �������� �ȴ�. �� 5 �� ��ǥ ����κ��� ������ Ž���� �̿��ϴ� �� ���� �����ְ� �ִ�. ���⼭�� ������ B �� A ���� �ְ�, A �� C ����, C �� �ٴ� ���� �ִ� ���·κ��� A �� B ����, B �� C ����, C �� �ٴ� ���� �ִ� ���¸� ���ϴ� ���̴�. �� ���������� ��ǥ�� �ִ� ������ ���� �� �ϳ��� ���ϴ� ������ �����ڸ� ���Ͽ� ��ǥ������ On (C, F1) �� On (B, C) �� On (A, B) �� ȸ�ͽ�Ű�� �ȴ�. �θ�ǥ wff �� �����ϱ� ���� move (A, F1, B) �� ���� ȸ���Ѵٰ� ����. �� �����ڴ� ������ ���� �� �ϳ��� On (A, B) �� ���ϹǷ� On (A, B) �� �θ�ǥ�� ���Ե� �ʿ䰡 ����. ������ ��ǥ ����� ���� ���� �� �������� ��� ���������� �θ�ǥ�� ���ԵǾ�� �Ѵ�. �� ��� Clear (B), Clear (A), On (A, F1) �� ��� �ش�ȴ�. ��ǥ wff �� �ִ� �ٸ� �� ������ ����, �� On (C, F1) �� On (B, C) �� �� �����ڿ� ���� �߰��ǰų� �������� �����Ƿ� �ܼ��� �� �����ڸ� ����Ͽ� �θ�ǥ�� ��Ÿ���� �ȴ�. �� 5 �� ��Ÿ�� ��ó�� ������ Ž���� �� �ٸ� ����� move (B, F1, C) �� ���� ��ǥ wff �� ȸ�ͽ�Ű�� ���̴�. ������ Ž���� (A* �� ����� ����� �̿��Ͽ�) ������ ���� ����� ���� �����Ǵ� �θ�ǥ�� ������ ������ ����ȴ�.
���� � ���ͷ��� ������, ���� ����Ʈ�� �� ���ͷ� �� �ϳ��� ���Ե� �����ڿ� ���� ȸ�͵ȴٸ� � ������ ������ �˾ƺ��� �͵� ��̷ο� ���̴�. ���ͷ� �� �� � �����ڿ� ���� �����ȴٸ� �� �����ڰ� �� ���ͷ��� ������ų ����� ����. ���� �� �� �����ϴ� �����ڸ� ���� �� �� �����ϴ� ������ �������� ȸ�ͽ�Ų ����� �� F �� �ȴ�. ����, F �� ������Ű�Ⱑ �Ұ����ϱ� ������ �˻��� �� �� F �� �����ϴ� ���� ����κ��� ���������� �õ��� �ʿ�� ����.
������ ���ȭ���� ���� ��Ģ, ��, ��Ű�������� ������ �����ϴ� ��Ģ�� ���� ��ǥ�� ȸ�ͽ�Ű�� ���� ���δ� ������ �� �ִ�. �� 5 ���� On (A, B) �� ���ϴ� �� ���� ������� move (A, F1 B) �� �̿��Ͽ���. �� A �� �ٴ����κ��� �ű�� �����Ͽ��°�? A �� ��Ե� �ٸ� �����κ��� �Űܿ;� �ϴ� ���� ������ �� �����̸� �ٴ����κ��� �ű�� �߾�� �ϴ°�? �Ƹ��� �ٸ� �����κ��� �ű�� �� ���� ��ȹ�� ���� ���� �ִ�. �̿� ���� ������ �̷�� �� ���� ����� �̵� �������� "from place" �κ��� �ӽ÷� �������� ���� ä�� ���ܵδ� ���̴�. �̷� ����� �ּ� ���� ��ȹ���� (least commitment planning) �� �� ��ʰ� �ȴ�. �Ϻθ� ���ȭ�� (partially instantiated) ������ move (A, x, B) �� ���� ��ǥ�� ȸ�ͽ��� "from place" �κ��� �������� �ʰ� ���ܵд�. �� 6 ���� �� ȸ���� ����� �����ְ� �ִ�. �� ����� ������ �Ͱ� ���� ������ �� ���� �ٸ� ���� ���������� �ϳ��� On (A, x) �� ������ �����ϰ� �ִٴ� ���̴�. �θ�ǥ�� �ؼ��Ǵ� �� ���ͷ��� ���±���� ���� ���ͷ��� ����ȭ���� ������ �� �ִ�. ������ �����ϴ� �θ�ǥ�� ������ ���� ������ Ž���� �Ϸ���, ������ �ٸ� ������ ����� ���ȭ��Ű�� �߰� �����ڸ� ����ؾ� �Ѵ�. �̸� ���� �ϳ��� ����ƽ���δ� ������ �����ϴ� ���ͷ��� �ʱ� ���� ����� �ִ� ���ͷ��� ����ȭ�� �� ���� ������ ���ȭ�� �̷�� ���̴�.

�� 6 �ϳ��� ������ �����ϴ� STRIPS ��Ģ�� ���� �������� ȸ��
�� 7 ������ Ž��
���� ������ ���������� �ο��ϱ� ���� ���� �߷� ������ ���� �� �ִ�. �� 6 ���� ������ ���������� A �� �ű���� �ϴ� �����̹Ƿ� On (A, x) �� ������ x �� A �� ���� �� ����. x �� C �� �� ���� ���µ� �� ������ A �� �ٸ� ������ B �� �ű�� ���̱� �����̴�. ���� x �� C �� �� ���� ���µ� �� ������ �ణ �̹��ϴ�. ���� x �� C ��� �θ�ǥ�� ���������� �� �ϳ��� On (A, C) �� �� ���̴�. ������ ���� B �� ���� A �� ���ÿ� C ���� ���� �� ���� ������ �� ��� ��ǥ�� �ִ� On (B, C) �� �θ�ǥ�� On (B, C) �� ȸ�ͽ�ų �� ���� (STRIPS �� ����� ȣ� �̿�� �θ�ǥ�� ȸ�Ϳ� ���� ������ �θ�ǥ�ʹ� �ٸ��ٴ� �Ϳ� �����϶�).
������ ���ȭ���� ���� STRIPS ��Ģ�� ���ؼ� ��ǥ�� �θ�ǥ�� ȸ�ͽ�Ű�� ��ü ���ν����� �����ϸ� [Nilsson 1980, pp.288ff] �� ���� �� ���� �����Ǿ� �ִ�. ������ Ž���� ���� ������ ������ �� 7 ���� �����ְ� �ִ�. �� ��� �������� F1 �� ���ȭ�Ǿ��µ� �̰��� �������� ���������� ���� �ٸ� ������ ���ȭ�� �� �ִ� ���ɼ��� ���� �����̴�. �ʱ� ���� ����� ���� �����Ǵ� �θ�ǥ�� �����Ǹ� Ž���� ����ȴ�. ���� ����, �ָ�ǥ�� �ʱ� ���¿� ���� �����Ǵ� �θ�ǥ�� �����Ű�� �Ϸ��� ��Ģ�� ��� ��������, Ž�� �������� �߰ߵ� ���ȭ�� ���������ν� ��ǥ�� ���ϴ� ��ȹ�� �����ڷ� ���ȭ�ȴ�. �� ������ ������ [Nilsson 1980, pp.292-296] �� ���� �ִ�.
ȸ�� �̿��� ������ Ž���� ������ Ž������ �� ȿ���������� ������ ��Ÿ���� ������ �� �����ϴ�. �ұԸ��� ������ ���ϼ��� ���������� ū ����� ���� ������ ���ȭ�� �� ������, �ξ� �� ū �Ը��� ������ �������� �� ����� ������ �������� ����ƽ�� ������� �ʰ��� �������� ���� ���������� �ǽɽ�����.
�ʺ�켱�� ������ �Ǵ� ������ Ž�������� ��ǥ�� ������ ���ڸ� ������ų �� Ư���� ������ ���� �ʴ´�. ������ �̻��� �� ������ ���ڸ� �ذ��ϴ� �� �ʿ��� �ܰ踦 ������ġ (interleave) �ϴ� ���� �ּ�å�� ������ �� �����̴�. ���� ��ȹ������ �ܰ���� ������ ���� ������ �̷�� ���� �ּ� ���� ��ȹ������ �� �ٸ� ����̸�, ���� ������ Ž���ϱ⺸�ٴ� ��ȹ�� ������ Ž���ϴ� ���� �ּ�å�� �� �ִ�. ��ȹ ���������� ��ȹ�� �ܰ���� �κ� ������ (partially ordered) �� �� �ִ�. �� ��ȹ���� ������ �κ� ���� ��ȹ���� (partial-order planning, POP) �̶�� �ϸ� ���� ������ �ٷ�� �ȴ� (�κ� �������� �ܰ踦 ���� ��ȹ�� ���� ��ȹ (nonlinear plan) �̶���� �Ѵ�).

�� 8 ���°��� Ž���� ��ȹ���� Ž���� ���
��ȹ ������ ���� �� ���� ���� �ٸ� ���� ����� �� 8 �� �����Ǿ� �ִ�. ���� ������ Ž�� (������) �� ���� STRIPS ��Ģ�� ���� ���տ� ����Ǿ� ���� �ļ��� (successor) ������ �����ϰ�, �� ������ ��ǥ���� ������Ű�� ���� ����� ������ ������ ��ӵȴ�. ������ ��ȹ�� ������ Ž���� ���� �ļ��� �����ڰ� STRIPS ��Ģ�� �ƴϰ�, �ҿ����ϰ� ���ȭ���� ���� �Ǵ� ������� ��ȹ�� ���� ��Ȯ�� ��ȹ���� ��ȯ��Ű�� �����ڰ� �Ǹ�, �ʱ� ���� ����� ��ǥ������ ������Ű�� ���� ����� �ٲپ��ִ� ���� ������ ��ȹ�� ������ ������ Ž���� ��ӵȴ�. ��ȹ���� Ž���� �����ڵ��� ��ȹ�� �ٸ� ��ȹ���� ��ȯ��Ű�� ���� �پ��� ������ �̿��Ѵ�. �̷��� ���ܿ��� (a) ��ȹ�� �ܰ踦 �߰�, (b) ��ȹ�� �̹� ���Ե� �ܰ踦 ���ġ, (c) ���� ����ȭ�� ��ȹ�� �κ������� ����ȭ�� ��ȹ���� ��ȯ, (d) ��ȹ ��Ű�� (���ȭ���� ���� ���� ����) �� �� ��Ű���� ��ʷ� ��ȯ�ϴ� �� ���� �����Ѵ�. �̷� ��ȹ ��ȯ �������� �Ϻο� ���� ���� �� 9 �� ��Ÿ�� �ִ�.

�� 9 ��ȹ��ȯ ������
��ȹ���� Ž�� ����� ������ �̻� (�� 4) �� ������� ������ ����. ���⼭�� ü����, ������ ��ȹ���� (systematic, nonlinear planning, SNLP) ��� [McAllester & Rosenblitt 1991] �� NONLIN [Tate 1977] �� �����Ͽ� �����ϰ��� �Ѵ�. ��ȹ�� �⺻ ������Ҵ� STRIPS ��Ģ�̴�. �� ��Ģ�� �� ���� ������ ��带 ���� ���� ������ ǥ���Ǵµ�, Ÿ���� ���� STRIPS ��Ģ�� �̸����� ǥ�� (label) �� �ٰ�, ������ ���� �� ��Ģ�� �������ǰ� ��� ���ͷ��� ǥ���� �ٴ´�. �̷��� ���� ������ �� 10 �� ��Ÿ�� �ִ�. ������ ���κп� �ִ� ���ڴ� ����̰�, �Ʒ��� �ִ� ���ڴ� ���������̴�.

�� 10 STRIPS ��Ģ�� ���� ǥ��
��ǥ wff �� �ʱ� ������ ���ͷ��� finish �� start �� �Ҹ��� ������ ��Ģ ������ ǥ���ȴ�. finish ��Ģ�� ���� ������ ��ü ��ǥ�̰� ����� Nil �� �ȴ�. start �������� ����� �ʱ� ���� ����� �ִ� ��� ���ͷ��̰�, ���������� T �̴�. ������ �̻� ���� �� �� ������ �� 11 ���� �����Ͽ���.
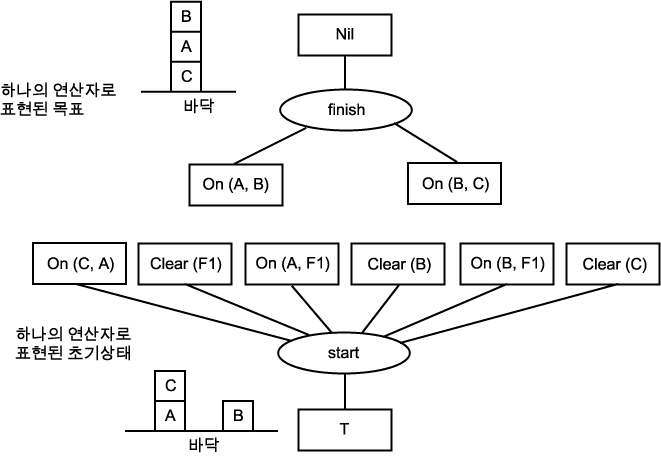
�� 11 finish �� start ��Ģ�� ���� ǥ��
�ʱ� ��ȹ ���� (� ��ȹ ��ȯ �����ڵ� �����Ű�� ����) �� �� 11 ���� ������ �Ͱ� ���� (������� ����) start �� finish ��Ģ���θ� �����ȴ�. ���� �̰��� �ſ� �ҿ����� ���̴� (��ȹ�� �����ϴٴ� ���� ������ �ǹ��ϴ����� ���߿� �����ϰ��� �Ѵ�).
���� ��ȹ�� Ž���� ��ȹ��ȯ �����ڵ� �� �ϳ��� �ʱ� ��ȹ ������ �����Ű�� �����κ��� �����Ѵ�. �� �ܰ迡�� ä�õ� �� �ִ� ��ȯ �� �ϳ��� �ʱ� ��ȹ ������ ��ǥ�� ������ ���� �� �ϳ��� ������ų �� �ִ� ��Ģ�� �߰��Ͽ� Ȯ���ϴ� ���̴�. ���� ��Ģ ��� move (A, y, B) �� �߰��Ͽ� On (A, B) �� ������Ű��� ����. �� ��ʿ� ���� ���� ������ �ʱ� ��ȹ ������ �߰��Ѵ�. �� ��Ģ�� �߰��ϸ� On (A, B) �� ���� �� ���� ���̶�� �Ǵ��߱� ������ ��Ģ�� ��� ���ڸ� finish ��Ģ�� ���� ���� ���ڿ� �����Ų��. �� ����� �� 12 �� ��Ÿ�� �ִ�. ���⼭ ���� A �� ���κ��� �Ű��������� ���� ����� ���� ���� �ʾҴٴ� �Ϳ� �����϶�.

�� 12 �ʱ� ������ ���� �ܰ��� ��ȹ ����
�� �ܰ迡�� ���� ��ȹ ��ȯ�� �����ϴ�. Clear (B) �� �����ų ���� �ִ�. �Ǵ� move (A, y, B) �� ���������� Clear (A) �� ������Ű���� �õ��� �� �ִ�. �� ������ A ���� �ִ� � ��ü (u �� ���) �� �ٸ� �� (v �� ���) ���� �ű�� ��Ģ ��� move (u, A, v) �� �����Ͽ� ������ų �� �ִ�. ���� ���� u �� C ��, ���� v �� F1 ���� ���ȭ���� �ʱ� ���¿� �ִ� �Ŀ� ���� ������ Ȯ���� �� �ִ�. �̷��� �Ϸ��� ��ȹ ��ȯ (plan-alteration) �ܰ��� ����� �� 13 �� ��Ÿ�� �Ͱ� ���� ��ȹ ������ ������ �� �ִ�.

�� 13 �߰� �ܰ��� ��ȹ ����
�� �ܰ迡�� �� �� �ִ� ����, �� move �������� �������ǵ��� �� �����ڰ� ����� �� �����ȴٴ� ���̴�. ���� �ҿ����� ��ȹ�� ǥ���ϴ� ���� ������ �ִ� �� move �����ڿ��� ����� ������ �ִ�. ���Ŀ� ��ȹ ������ ����� ���� move �������� �� �� ��츦 �ο��Ϸ��� �Ѵ�. �̷��� ������ �� 13 �� �� �ѿ� ���� a �� b �� ǥ���� �ٿ���. b �� a ���� ���� �;� �Ѵٴ� ����� b < a ��� ǥ����� ���� ��Ȯ�ϰ� ǥ���ϴµ� ���⼭ < �� ���� (before) �� ��Ÿ����. �̶� On (C, F1) �� Clear (F1) �� �� ���ڴ� move �������� ����ǰ (product) ������ ���Ŀ� �ٸ� �����ڿ� ���� �Һ���� (consumed) �ʴ´ٴ� �Ϳ� �����϶�. �̵��� ��ȹ�� ���� �ܰ迡�� �ݵ�� ���� �Ǿ�� �ϴ� ���ǿ� ������� �ʴ� �� ��ȹ���� �ƹ��� �ظ� ��ġ�� �ʴ´�.
�������� �ٸ� �ָ�ǥ ������ ������ On (B, C) �� ��� �������Ѿ� ������ ������ ����. �� ������ B �� ��κ��� C ���� �ű�� ��Ģ ����� move (B, z, C) �� ���� ���� �� �ִ�. ���� �� �ܰ踦 ��ȹ �������� �߰��ϸ� �ȴ�. �� �� z �� F1 �� ���ȭ�Ͽ� �ʱ� ���ǰ� �����ų �� �ִ�. ��������� �� 14 �� ���� ��ȹ ������ ��Ÿ����.

�� 14 �Ĺ� �ܰ��� ��ȹ ����
���� ������ a, b, c �� �����ϴ� ��ȹ ������ ���� �Ǵµ�, �̵� �����ڴ� �κ������θ� ������ �Ű��� �ִ� (only partially ordered). ���ݱ����� ��ȹ �ܰ��� �������� c �� ��� �;� �ϴ����� ���ؼ� �ƹ��� ����� ���� �ʾҴ�. �κ� ���� ��ȹ������ �� �����ڰ� �߸��Ͽ� �������� ���� �� ����Ǿ� �ٸ� �����ڰ� �ʿ�� �ϴ� ���������� �����·� �ǵ��� �� �ֱ� ������ �̶� ���ϴ� ������ �����ؾ� �Ѵ�. �̷� ���ɼ��� ��ȹ ���� �������� ���� ��ũ (threat arc) �� ��Ÿ����. �� 15 �� �ִ� ���� ������ ������ ����. ���� ȸ�� ȭ��ǥ�� ���� ��ũ�̴�. ���� ��ũ�� ������ (Ÿ����) ��忡������ (a) �� �������� ���� ����Ʈ�� �ְ�, (b) �� ������ ����� �ļ��� �ƴ� �������� (����) ��忡�Է� ȭ��ǥ�� ������. �� 15 ���� ����, ������ move (A, F1, B) �� move (B, F1, C) �� ���������� Clear (B) �� �����Ѵ�. �̷� �鿡�� move (A, F1, B) �� move (B, F1, C) �� �����Ѵٰ� ���µ�, �ֳ��ϸ� �� �����ڰ� ���� ����Ǹ� �� �����ڸ� ������ �� ���� �����̴�. ���� ��ũ�� �������� ������ ���� ���� ������ �����ν� ���ŵǾ�� (discharged) �Ѵ�. �ϳ��� ��ȹ�� ��� ���� ��ũ�� �����ϴ� �ϰ��� ���� ���� ������ ã�� �� ���� �������� �ϼ��� ���� �ƴϴ�. ���� �������� �̷��� �ϰ��� ���� ������ ������ (c < a, b < c) �̴�. ���� ���� ���� ��ü�� (b < a) ��� ������ �Ͻ��ϰ� ������, �̰��� �ٸ� ��� ���� ����� �ϰ��ȴ�. ���� �� 15 �� ��ȹ ������ (b < c < a) �� ��ü ���� (total order) �� �����Ѵ�. �� ��ȹ�� ��� ���� ��ũ�� ���ŵǰ� ������ (finish �����ڸ� �����ϴ�) ���� �䱸�ϴ� ��� ���� ������ �� �����ڰ� ����� �� �����DZ� ������ �����ϴ�. ���� ���� ��ȹ�� {move (C, A, F1), move (B, F1, C), move (A, F1, B)} �� �ȴ�.

�� 15 ���� ��ũ �߰�
�̹� 10 �忡�� ������ Ž�� ���ν����� ���� ����Ͽ���. ���� ���������� STRIPS ��Ģ�� ����� �� ������ ��ȹ�ڸ� �����Ͽ���. �� �� �ϳ��� ABSTRIPS �ý��� [Sacerdoti 1974] �� STRIPS ��Ģ�� �������ǿ� �ִ� �� ������ ���ڿ� �Ѱ谪 (criticality number) �� �ο��Ѵ�. ���ϱⰡ ������� �� ������ ������ �Ѱ谪�� ��������. ABSTRIPS ������ �� �Ѱ谪�� ����ؼ� ������ ���� �ܰ������� ��ȹ�� �����Ѵ�.
1. �Ѱ��� ��� ���������� � �Ӱ谩 (threshold value) ������ ���� ���̶�� �����ϰ� �� ������ ����� �ΰ� ��ȹ�� �����Ѵ�. �ٺ������� ���� ���ϱ� ����� ������ ���ڸ� ������ �ٸ� ��� ������ ������ ���� �̷������.
2. �Ѱ� �Ӱ谪 (criticality threshold) �� 1 ��ŭ ���߰�, �ܰ� 1 ���� ������ ��ȹ�� �ȳ��ڷ� ��� �Ӱ谪���� ���� �Ѱ��� ���������� ���̶�� �����ϴ� ��ȹ�� �����Ѵ�.
3. �̷� ������ ����Ѵ�.
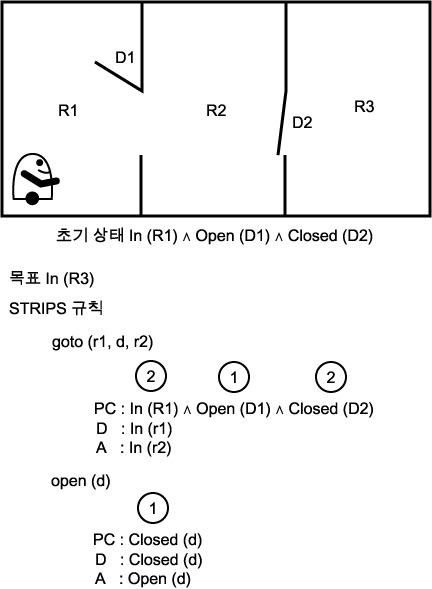
�� 16 ABSTRIPS �� ���� ��ȹ���� ����
ABSTRIPS �� ���̵� ������ �ϳ� ��� �����ϰ��� �Ѵ�. �̹����� �� �濡�� �ٸ� ������ �̵��ϴ� �κ��� �̿��Ѵ�. �� 16 �� �ʱ� ��Ȳ�� ��ǥ, ��Ģ�� ���ǵǾ� �ִ�. goto (r1, d, r2) ��Ģ�� �κ��� �� r1 ���� �� r2 �� �� d �� ����ؼ� �����̰� �ϴ� �ൿ ��Ű���� ���Ѵ�. open (d) ��Ģ�� �� d �� ���� ���̴�. �Ѱ谪�� �� ��Ģ���� �������ǿ� �ִ� �ش� ���ͷ� ���� ������ ��Ÿ����. Ư�� ���� ���� ���� ���� ����ϴ� �Ϳ� ���� ��������� ���ٰ� �����ϸ�, open (d) �� 1 �� �Ѱ谪�� ���´�.
����, �� ��ȹ (�������� ���ǵ� ��ȹ���� ��� �� �ϳ��� ����ϴ�) �� �����Ѵ�. �̶� �Ѱ谪�� 1 �� ��� ���������� �̹� �����Ǿ��ٰ� �����Ѵ�. �� �� �ܰ迡�� In (R3) �� ���ϴ� ��ȹ�� {goto (R1, D1, R2), goto (R2, D2, R3)} �̴�. �������� �� ��ȹ�� �ִ� ù��° �������� ���������� ���ϱ� ���� ���� �ڼ��� ��ȹ�� �����ϰ�, �� �����ڸ� �����Ͽ� �� ��ȹ�� �ι�° �������� ���������� ���ϰ�, �̷� ������ ��� �����Ѵ�. �� �����ڵ��� ���������� Ž�������� �ִ� ������ ������ �� �ִµ�, �� ������ ù��° �ܰ��� ���� ��ȹ���� �������� �߰ߵȴ�. ������ �� ���������� ������ų �� �Ѱ� �Ӱ谪�� 1 ��ŭ ���߾ �Ѱ谪�� 1 �� ��� �������ǵ� �����ǵ��� �Ѵ�. ��������� {goto (R1, D1, R2), open (D2), goto (R2, D2, R3) �� ��ȹ�� �����ȴ�. �Ϲ������� �� �� �̻��� �Ѱ谪�� ���� ���� �ִµ�, �̶����� ��ȹ���� ������ ���� �� �ܰ踦 ���� �������� �ȴ�.
ABSTRIPS ���� ���Ǵ� ��ȹ���� ���� (plan-development process) �� ���̿켱 (length first) �̴�. ��, �� �� �ܰ迡�� ���� ������ ��ȹ�� �����ϰ� ����, �Ʒ��� �� ���� �ܰ�� �������� �װ������� ������ ��ȹ�� �����ϴ� ���̴�. �� ���̿켱�� ��ȹ ���߿� ���� ��ȵ� �ִ�. ���� ���, Ž�������� �ִ� �Ϸ��� ���� �ĺ��ϱ� ���ؼ��� �ֻ��� �ܰ迡�� ������ ��ȹ�� ������ ���� �ִ�. �̷��� ���� ù° �ܰ��� ���� �������� ���� ������ �� �ִ�. ���� ����, ���� �ܰ迡�� ù° ���� ���ؼ��� ������ ��ȹ�� ù �κ��� ������ �� �ִ�. �̷� ������ ���� ���� �ܰ迡 �ִ� ù° ���� ���� ������ ��ȹ�� ������� ������ ��ӵȴ�. ���⼭ ���� ���� �ܰ迡���� ��ȹ�� ù° �����ڰ� �ʱ� ���¿��� ����� �� �ִ� �ൿ�� �����ȴٰ� �����Ѵ�. �̷��� ���̿켱 (depth first) �� ��ȹ���� ������ ����/��ȹ/�ൿ �ֱ� (sense/plan/act cycle) �� �̿��ϴ� ��Ȳ�� �����ϴ�. ó�� �ൿ�� �����Ͽ� ����� ��Ÿ���� ���¸� �ν��� �� ��ȹ����� (replanning) �� ���� ������ �ݺ��ϴµ�, �̶� ���� ��ȹ�� �� �� ������ �ܰ踦 �ȳ��ڷ� �̿��ϰ� �ȴ�.
������ ��ȹ���� (hierarchical planning) �� 9 �忡�� ����� ���, �� ���� �������� ���Ǵ� ����ƽ �Լ��� ���� ��� ���ؼ��� �� ������ ���� �ܼ�ȭ�ǰ� ��ȭ�� ������ ���� �ذ��Ѵٴ� ����� �� ����̴�. ���� ��ȹ���� ������ �� �ܰ�� �� �Ʒ� �ܰ��� �ܼ�ȭ�� �������� ���ֵ� �� �ִ� ([Pearl 1984, p.131-132] ���� Pearl �� �ڽ��� ������ �ܼ�ȭ �� ABSTRIPS ���� ���踦 ����ϰ� �ִ�).
NOAH, SIPE, O-PLAN [Sacerdoti 1977, Wilkins 1988, Currie & Tate 1991] �� ���� ��ȹ���� �ý����� �κ� ���� ��ȹ���� ��ȹ������ ������ ��ȹ������ �����ϰ� �ִ�. �� �ý��۵��� �̹� ����� ��ȹ���� ������ (������ ���ȭ, STRIPS ��Ģ�� �߰� ���) �ܿ��� �� ��ȹ�� �� ������ �Ʒ� �ܰ迡 �ִ� ��ȹ�� ���� �����Ű�� �����ڸ� �����Ѵ�. �� ���� (articulation) �� �տ��� ������ ��ȹ���� �����ڿ� ������ �� �ִ�. ���� ���, ���ϼ��迡�� ���� move ��Ģ�� pickup �� putdown �� ���� �� �� �������� ��Ģ�� �������� ������ �� �ִ�. �� �����ܰ� ��Ģ���� �Ϲ������� ���� ��ü���� ���������� ������ �Ǵµ�, �� �������ǵ��� �� �ܰ迡�� ������ ��ȹ�� ����� ���� �ٸ� ���� �ܰ� ��Ģ�� ������ �䱸�Ѵ� (�� 17 �� ����). �� ������ ��� ������ (�Ǵ� ��� ù° ������) �� ���� ������ ���� �ൿ (primitive action) �� ������ ������ ��ӵȴ�.

�� 17 ��ȹ�� ����
17 �忡�� �߷� �ý��ۿ� ���� ���ο� ��Ģ�� �н��� �� EBG �� �̿��� ��ó�� �̹� �����ϴ� �Ϸ��� STRIPS ��Ģ���� ������ ���ο� STRIPS ��Ģ�� �н��� ���� STRIPS �� �̿��� �� �ִ�. �̷��� �н��� ��Ģ���� �� ������ ��ȹ�� �����ϱ� ���� ���� �� �ִ�. ���� �տ��� ����� �Ͱ� ���� ȿ�뼺 ���� (utility problem) �� �����ϰ� �ȴ�. �н��� ��Ģ�� ���� ������ �ʰ�, ��ȹ������ ������ ���� ���ϰ�, ����ϴ� �� ����� ���� ��ٸ� ���� ���� ���̴�. ������ �ϳ� �� ���ο� ��Ģ�� �н��ϴ� ����� �����ϰ��� �Ѵ�.

�� 18 �� ������ �������� ����
�� 18 �� ��Ÿ�� �Ͱ� ���� ������ ��ġ�� �ٲٴ� ������ ������ ����. �ʱ�� ���� A �� ���� B ���� �ְ�, ���� B �� ���� C ���� ������, �� �ʱ� ���·κ��� A �� B �� ��� �ٴ� ���� ���̴� ��ǥ ���¸� ���Ϸ��� �Ѵ�. �������� ���ǵ� ��� ��ȹ���� ��������� {move (A, B, F1), move (B, C, F1)} �� ��ȹ���� �����ϰ� �� ���̴�. �̶�, �� ��ȹ�� ���ο� STRIPS ��Ģ�� ���·� ������ ��ġ�� �ְڴ°�? ������Ʈ�� �� ��ü���� ������ ���� Ǯ��� �Ѵٸ� ������ ��. �� ��ȹ�� �� ���� �� ���� (�̸��� �������) �� ������ ���ÿ��� ���� ��ǥ �������� �ű�� �Ϲ�ȭ�� �� �ִٸ� ���� ���� ȿ�뼺�� ���� �� �ִ�. ��ȹ�� �����ϴ� ���� ������ �̸��� �������� �ʱ� ������ EBG �� ������ ������ ���� ��ü����� A, B, C ��ſ� ���� ��ȣ�� ���� ��ȹ ��Ű���� ������ �� �ִ�. ������ �̷��� �� �ܰ� ��ȹ���� ��ǥ ������ �ٴ��̾�� �ϱ� ������ ��ü��� F1 �� �Ϲ�ȭ�� �� ����.

�� 19 ���� ������� ���� �ﰢ�� ���̺�
�� ��ȹ �Ϲ�ȭ ����
(plan-generalization process) ���� ��ȹ�� �ִ� �������ǰ� ����� ���� ������
�̿�ȴ�. �̷��� ������ ǥ���ϴ� ������ ��� �� �ϳ��� �ﰢ�� ���̺� (triangle
table) [Fikes, Hart, & Nilsson 1972] �� �̿��ϴ� ���̴�. ���� �������� ������
���� ���̺��� �� 19 �� ��Ÿ������. ���̺��� �� �� (column) �� �� ������ ��ȹ��
���Ե� ������ �� �ϳ��� ���� �Ǵµ� ��ȹ�� ��Ÿ���� ������ ���� ��ġ�Ѵ�. �κ�
���� ��ȹ��������ó�� ������ start �� finish �����ڸ� �����ϴ� ���� �����ϴ�.
�� ���̺��� �� �����ڿ� ���� �������ǰ� �� �����ڰ� ������ ������Ű������ ǥ���Ѵ�.
�� ������ �ٷ� �Ʒ��� �ִ� ���� �����ڿ� ���� �߰��Ǵ� ���ͷ� (�ݺ��� �� ����)
�� ������. �� �������� ���ʿ� �ִ� ���� �� �������� ���������� �Ǵ� ���ͷ���
������. ���̺��� ���� ���̺��� �� �� �� (row) �� 1 �� �� ���� �� ��ġ 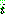 �� ���̺��� �� ���� ���� 1 �� �� ���� �� ��ġ
�� ���̺��� �� ���� ���� 1 �� �� ���� �� ��ġ  �� ���εȴ�. ��ü������ ���Ѵٸ�, ��
�� ���εȴ�. ��ü������ ���Ѵٸ�, �� 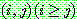 �� ������
�� ������  �� ������������ �䱸�Ǵ� �� �߿�
�� ������������ �䱸�Ǵ� �� �߿� 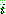 �����ڿ� ���� �߰��Ǵ� ���ͷ���
�����ڿ� ���� �߰��Ǵ� ���ͷ��� 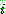 ��
��  �� �����ڸ� �����ؼ� ���� �Ǵ� ���ͷ��� ������. ���� start �������� �Ʒ���
�ִ� ���� �ʱ� ���� ����� �ִ� ���ͷ��� ���Ŀ� ���� �����ڰ� �ʿ�� �ϰų�
�Ǵ� ��ǥ���ǿ� �ִ� ������ ���ڸ� ������Ű�� ���ͷ��� �����Ѵ�. finish ��������
���ʿ� �ִ� ���� ��ǥ������ ������Ű�� ���ͷ��� ������.
�� �����ڸ� �����ؼ� ���� �Ǵ� ���ͷ��� ������. ���� start �������� �Ʒ���
�ִ� ���� �ʱ� ���� ����� �ִ� ���ͷ��� ���Ŀ� ���� �����ڰ� �ʿ�� �ϰų�
�Ǵ� ��ǥ���ǿ� �ִ� ������ ���ڸ� ������Ű�� ���ͷ��� �����Ѵ�. finish ��������
���ʿ� �ִ� ���� ��ǥ������ ������Ű�� ���ͷ��� ������.
��ȹ �Ϲ�ȭ ���ν����� ���� �ܰ迡���� �ﰢ�� ���̺��� �ִ� ��� ��ü����� ���� ��ȣ�� �ٲ۴�. �� ��ü����� ���� �� ���� ���� ���� ���� ��ȣ�� �ٲ۴�. ���� ���� �� ������ ��� ��Ģ�� ���������� �� ��Ģ�� �� ��ʰ� ����� �� �����ǵ��� ��� ��ȹ ��Ű�� (resulting plan schema) �� ���� �Ϲ����� ��ʸ� ã�´�. �� ��Ģ�� �������ǵ��� ù° ���Ǻ��� ���ʷ� �˻�Ǹ�, ���� �� ���������� ������Ű�� ���� ġȯ�� �ʿ䰡 �ִ� ��� �ش� ġȯ�� ���������. ���� �������� ������ ���� ��� �ﰢ�� ���̺� ��Ű���� �� 20 �� ��Ÿ���ִ�.

�� 20 ���� ������� ���� �ﰢ�����̺� ��Ű��
�ﰢ�� ���̺� ���·� �� �Ϲ�ȭ�� ��ȹ ��Ű���� MACROP (��ũ�� �������� �ǹ���) �� �θ���. �̰��� �� �� ��ȹ�� �����ϱ� ���� STRIPS ��Ģ���� ���� �� �ִ�. 1 �� ���� �ִ� ���ͷ��� �������� MACROP �� ���������� �ǰ�, 3 �� � �ִ� ���ͷ��� �߰� ����Ʈ�� �ִ� ���ͷ��� �ȴ� (���� ����Ʈ�� ����Ϸ��� ������ ��Ģ���� ���� ����Ʈ�� �м��ؾ� �Ѵ�). �Ϲ�ȭ ���� ��ü�� ���� ����� ��ȹ�� ������ �����ϴ� �� ���� �ﰢ�� ���̺��� �̿��� [Fikes, Hart, & Nilsson 1972] ���� ���ǵǾ���.
MACROP �� �н��ϴ� �� �ܿ� ��ü���� ��ȹ�� �����ϱ� ���� �õ��� �̷��� ��ȹ���� ����� ���̴� �������� ������ ������ �� �ִ�. ���� ���, ���� �������� On (A, F1) �� On (B, F1) �� �������� ���ϱ� ���ؼ��� On (A, F1) �� ������ ���ڸ� ���� ���ϴ� ���� �߿��ϴ� (On (B, F1) �� ���� ���ϱ� ���� B ���� �ƹ� �͵� ������ �Ϸ��� A �� �ٸ� ���� ���� �ű�� ����, �ٽ� �ٴ����� �Űܾ� �Ѵ�). Minton �� PRODIGY �ý����� EBG �� �̿��Ͽ� �̰��� ���� ������ �н��� �� �־��� [Minton 1988] (�κ� ��� (partial evaluation) �� ���ʸ� �� ����� [Etzioni 1993] �� ���� �ִ�).
��ȹ������ �־ �� �ٸ� ������ �н����δ� ��Ģ ��ü�� ����� �н��ϴ� ���̴�. ������Ʈ�� ���� ���� ��� ������ �ൿ�� ���� �� ������ �� �ൿ�� ����� �Ǵ� �� �ൿ�� � ���ǿ��� ����� �� �ִ����� ���� ���� �� �� �ִ�. �ذ��ϱ�� ������� �߿��� ������ �ൿ �� (action model) �� �н��� [Shen 1994, Gil 1992, Wang 1995, Benson 1997] �� ���� �̷������. [Benson 1997] ������ �н��� �����ڸ� �̿��Ͽ� ����� ��ȹ�� ��Ÿ���� ���� ���� ������ (teleo-reactive, T-R) ���α� ǥ���� �̿��Ͽ���. 2 �忡�� ����� ��� T-R ǥ���� ��ȹ ������ ���� �߰��ϰ� �����.
[Lifschitz 1986 (Lifschitz, V., "On the Semantics of {STRIPS}," in Georgeff, M., and Lansky, A. (eds.), Reasoning about Actions and Plans: Proceedings of the 1986 Workshop}, Timberline, Oregon, pp.1-9, San Francisco: Morgan Kaufmann, 1986. (Also in Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, pp.523-530, San Francisco: Morgan Kaufmann, 1990.))] �� STRIPS �� �ʱ� ������ Ÿ������ �ʰ� ���ǹ��� ����ȭ�� �����ϴ� �� �ʿ��� ��Ȯ���� ���� ������ ���̵Ǿ� �ִٰ� ����Ͽ���. ���� �� ������ ���ϱ� ���� �䱸�Ǵ� STRIPS �� ��� �� ���� ���� ������ �����Ͽ��� (�� å���� ����� ���� �� ���� ������ ������ �ִ�). [Pednault 1986 (Pednault, E. "Formulating Multiagent, Dynamic-World Problems in the Classical Planning Framework," in Georgeff, M., and Lansky, A. (eds.), Reasoning about Actions and Plans: Proceedings of the 1986 Workshop, Timberline, Oregon, pp.47-82, San Francisco: Morgan Kaufmann, 1986. (Also in Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, pp.675-710, San Francisco: Morgan Kaufmann, 1990.)), Pednault 1989 (Pednault, E., "ADL: Exploring the Middle Ground between STRIPS and the Situation Calculus," in Brachman, R., Levesque, H., and Reiter, R. (eds.), Proceedings of the First International Conference on Principles of Knowledge Representation and Reasoning (KR-89), pp.324-332, San Francisco: Morgan Kaufmann, 1989.)] ������ ���Ǻ� ��� (conditional effects) �� ���� ��Ģ�� �̿��ؼ� Lifschitz �� ����� ������ �����ϰ� ���� ������Ʈ ��ȹ�� ����ȭ�� �� �ִ� STRIPS �� ������ ���õǾ���. [Bylander 1994] ������ STRIPS �� ���� �����ڿ� ���� ��ȹ������ �־��� ��� (worst case) �� ���������� ó���� �Ұ����ϴٴ� ���� �����Ͽ��� (��� ��� (average case) �м��� ���ؼ��� [Bylander 1993 (Bylander, T., "An Average Case Analysis of Planning," in Proceedings of the Eleventh National Conference on Artificial Intelligence (AAAI-93), pp.480-485, Menlo Park, CA: AAAI Press, 1993.)] �� �����϶�). [Erol, Nau, & Subrahmanian 1992 (Erol, K., Nau, D., and Subrahmanian, V., "On the Complexity of Domain-Independent Planning," in Proceedings of the Tenth National Conference on Artificial Intelligence (AAAI-92), pp.381-386, Menlo Park, CA: AAAI Press, 1992.)] �� STRIPS �� ���� ������ ��ȹ���� �ý����� ����� ���� ö���� �м��� �����ϰ� �ִ�.
[Gupta & Nau 1992 (Gupta, N., and Nau, D., "On the Complexity of Blocks-World Planning," Artificial Intelligence, 56(2/3):223-254, 1992.)] �� �Ǽ����� ���¿� ��ǥ�� ���� ���� (ground atom) �� ���������� ����Ǵ� ���ϼ��� �������� ������ (�ִ���) ��ȹ�� ã�� ���� �Ϲ������� NP-hard ���� �����Ͽ��� (������ �ұ��ϰ� [Chapman 1989 (Chapman, D., "Penguins Can Make Cake," AI Magazine, 10(4):45-50, 1989.)] �� �ܼ��� ������ �ý��� (reactive system) �̶� ������ ���� ���� (sensory predicate) �� ����ٸ� ���ϼ��� �۾��� ���� ������ �� �ִٴ� ���� ������).
������ Ž������ �䱸�Ǵ� ������ STRIPS ��Ģ�� ���� ��ǥ�� ȸ�� �̿��ϴ� ����� [Waldinger 1975 (Waldinger, R., "Achieving Several Goals Simultaneously," in Elcock, E., and Michie, D. (eds.), Machine Intelligence 8, pp.94-138, Chichester, England: Ellis Horwood, 1975.)] ���� �Ұ��Ǿ���.
[Blum & Furst 1995 (Blum, A., and Furst, M., "Fast Planning through Planning Graph Analysis," in Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI-95), pp.1636-1642, San Francisco: Morgan Kaufmann, 1995.)] �� STRIPS ��Ģ���� ����� ��ȹ���� ������ ��� ã�� ������� �ذ��ϱ� ���� ��ȹ���� ���� (planning graph) �� �Ҹ��� ������ ��ȯ�Ͽ���. [Kautz & Selman 1996 (Kautz, H., and Selman, B., "Pushing the Envelope: Planning, Propositional Logic, and Stochastic Search," in Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI-96), pp.1194-1201, Menlo Park, CA: AAAI Press, 1996.), Kautz, McAllester, & Selman 1996 (Kautz, H., McAllester, D., and Selman, B., "Encoding Plans in Propositional Logic," in Proceedings of the Fifth International Conference on Principles of Knowledge Representation and Reasoning (KR-96), pp.374-384, San Francisco: Morgan Kaufmann, 1996.)] �� WALKSAT �� ���� �ذ��� �ϱ� ���� ��ȹ���� ������ �������� PSAT ������ ��ȯ�ϴ� ����� �����ϰ� �ִ�. ���� ��ȹ���� ������ PSAT ������ ���� �ڵ�ȭ�ϴ� ���ο� ����� �����Ͽ���. [Ernst, Millstein, & Weld 1997 (Ernst, M., Millstein, T., and Weld, D., "Automatic SAT-Compilation of Planning Problems," in Proceedings of the Fifteenth International Conference on Artificial Intelligence (IJCAI-97), pp.1169-1176, San Francisco: Morgan Kaufmann, 1997.)] �� ȿ������ Ȯ���� ��������� (stochastic and hill-climbing) Ž�� ����� �̿��� �������� (scalable) ��ȹ���� ����� ����� ���� �ſ� �߿��� �����̴�.
Sacerdoti �� NOAH �ý��� [Sacerdoti 1975 (Sacerdoti, E., "The Non-linear Nature of Plans," in Proceedings of the Fourth International Joint Conference on Artificial Intelligence (IJCAI-75), pp.206-214, San Francisco: Morgan Kaufmann, 1975. (Reprinted in Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, pp.162-170, San Francisco: Morgan Kaufmann, 1990.))], Sacerdoti 1977 (Sacerdoti, E., A Structure for Plans and Behavior, New York: American Elsevier, 1977.)] �� Tate �� INTERPLAN [Tate 1977 (Tate, A., "Generating Project Networks," in Proceedings of the Fifth International Joint Conference on Artificial Intelligence (IJCAI-77), pp.888-893, San Francisco: Morgan Kaufmann, 1977. (Reprinted in Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, pp.291-296, San Francisco: Morgan Kaufmann, 1990.))] �� ������ �κ� ���� ��ȹ�ڿ���. Chapman �� TWEAK �ý��� [Chapman 1987 (Chapman, D., "Planning for Conjunctive Goals," Artificial Intelligence, 32(3):333-377, 1987.)] �� �κ� ���� ��ȹ�ڸ� ���ʷ� ����ȭ�Ͽ���, ���� ���� �߿��� ������ �Ұ��Ͽ���. �״� ���� ��ǥ���� (atomic goal conditions) �� �������� ���ϱ� ���� �κ� ���� ��ȹ�� ã�� ������ NP-hard ���� ������.
McAllester �� Rosenblitt �� �κ� ���� ��ȹ���� SNLP ����ȭ�� [Soderland & Weld 1991 (Soderland, S., and Weld, D., "Evaluating Nonlinear Planning," Technical Report TR-91-02-03, University of Washington Department of Computer Science and Engineering, Seattle, WA, 1991.)] ���� �����Ǿ���. �� ������ UCPOP [Penberthy & Weld 1992 (Penberthy, J., and Weld, D., "UCPOP: A Sound, Complete Partial-Order Planner for ADL," in Proceedings of the Third International Conference on Principles of Knowledge Representation and Reasoning (KR-92), pp.103-113, San Francisco: Morgan Kaufmann, 1992.)] ���� �̾�����. [Ephrati, Pollack, & Milshtein 1996 (Ephrati, E., Pollack, M., and Milshtein, M., "A Cost-Directed Planner: Preliminary Report," in Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI-96), pp.1194-1201, Menlo Park, CA: AAAI Press, 1996.)] �� ��ȹ���� �����ڸ� �����ϱ� ���� A* ������ Ž���� �̿��Ͽ���. �κ� ���� ��ȹ�ڿ� ��ü ���� ��ȹ���� �� [Minton, Bresina, & Drummond 1994 (Minton, S., Bresina, J., and Drummond, M., "Total-Order and Partial-Order Planning: A Comparative Analysis," Journal of Artificial Intelligence Research, 2:227-262, 1994.)] ���� �̷������. �ּ� ���� ��ȹ������ �κ� ���� ��ȹ���� ����� ���� ��������� [Weld 1994 (Weld, D., "An Introduction to Least Commitment Planning," AI Magazine, 15(4):27-61, 1994.)] �� �����϶�.
[Christensen 1990 (Christensen, J., "A Hierarchical Planner That Generates Its Own Hierarchies," in Proceedings of the Eighth National Conference on Artificial Intelligence (AAAI-90), pp.1004-1009, Menlo Park, CA: AAAI Press, 1990.), Knoblock 1990 (Knoblock, C. A., "Learning Abstraction Hierarchies for Problem Solving," in Proceedings of the Eighth National Conference on Artificial Intelligence (AAAI-90), nl pp.923-928, Menlo Park, CA: AAAI Press, 1990.)] �� �ڵ����� ������ ���� ������ �н��ϴ� ����� �����Ͽ���. [Tenenberg 1991 (Tenenberg, J., "Abstraction in Planning," in Allen, J., Kautz, H., Pelavin, R., and Tenenberg, J. (eds.), Reasoning about Plans, Ch.~4, San Francisco: Morgan Kaufmann, 1991.)] �� ������ ��ȹ�ڿ��� �ʿ��� ��ȭ�� �����Ͽ���. [Erol, Hendler, & Nau 1994 (Erol, K., Hendler, J., and Nau, D., "HTN Planning: Complexity and Expressivity," in Proceedings of the Twelfth National Conference on Artificial Intelligence (AAAI-94), pp.1123-1128, Menlo Park, CA: AAAI Press, 1994.)] �� �� �ٸ� ������, �κ� ���� ��ȹ���̴�.
[Dean & Wellman 1991 (Dean, T., and Wellman, M., Planning and Control, San Francisco: Morgan Kaufmann, 1991.)] �� AI ��ȹ������ �ð��� �߷� ����� ������ ���� �̷а� �� ������ å�̴�. �̷��� �߸� ������ �ٸ� ����� ������ ���� [Ramadge & Wonham 1989 (Ramadge, P., and Wonham, M., "The Control of Discrete Event Systems," Proc. of the IEEE, 77(1):81-93, 1989.)] �� ���� �̻��� �̺�Ʈ �ý��ۿ� ���� �����̴�. �ð��� �߷а� ��ȹ ���������� ���ҿ� ���� �߰� ���Ǵ� [Allen, et al. 1990 (Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, san Francisco: Morgan Kaufmann, 1990.)] �� �����϶�. [Zweben & Fox 1994 (Zweben, M., and Fox, M. (eds.), Intelligent Scheduling, San Francisco: Morgan Kaufmann, 1994. endbiblio endlist)] �� ���� ���� ��ȹ������ Ž�� ����� �����ٸ� ������ ������״�. [Wilkins, et al. 1995 (Wilkins, D. E., Myers, K., Lowrance, J., and Wesley, L., "Planning and Reacting in Uncertain and Dynamic Domains," Journal of Experimental and Theoretical Artificial Intelligence, 7(1):197-227, 1995.)] �� ��ȹ���� ����� Ȯ���Ͽ� ��Ȯ�Ǽ��� �����ϴ� ���뿡 ������״�.
��ȹ������ ���� ���� �߿��� �������� [Allen, et al. 1990 (Allen, J., Hendler, J., and Tate, A. (eds.), Readings in Planning, san Francisco: Morgan Kaufmann, 1990.)] �� �������� ���ԵǾ� �ִ�. �н��� ��ȹ������ ���� �������� [Minton 1993 (Minton, S. (ed.), Machine Learning Methods for Planning, San Francisco: Morgan Kaufmann, 1993.)] �� ���� �ִ�. Practical Planning �̶�� �̸��� å�� SPIE �ý��۰� �� ���뿡 ���� ����ϰ� �ִ� [Wilkins 1988 (Wilkins, D. E., Practical Planning: Extending the Classical AI Planning Paradigm, San Francisco: Morgan Kaufmann, 1988.)].
��ȹ������ ���� ������ �ֿ��� AI ���ΰ� ��ȸ �������� ���������� �Ǹ���. AI ��ȹ���� �ý���(AI Planning Systems, AIPS) �� ���� ������ȸ�� �ִ�. ��ȹ������ �����ٸ� ����� �ֱ� ���뿡 ���� �������� [Tate 1996 (Tate, A. (ed.), Advanced Planning Technology, The Technological Achievements of the ARPA/Rome Laboratory Planning Initiative, Menlo Park, CA: AAAI Press, May 1996.)] �� ���� �ִ�.